从4004到core i7:处理器的进化史 (3)-2-黑箱内部
上个帖子中我们已经大概明白一个处理器里面都有些什么了。在这个帖子中我们把处理器这个黑箱彻底打开。先来看看4004,这可是我们优化的起点:
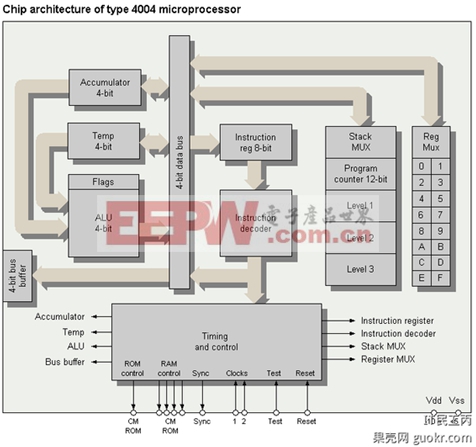
我们发现在上图中,麻雀虽小,五脏俱全,几乎所有结构都具备了。注意下方的timing and control,它就是我上个帖子中提到的控制器。在CPU中,可以将控制器视为一个有限状态机(finite state machine)。所谓有限状态机就是下面的结构
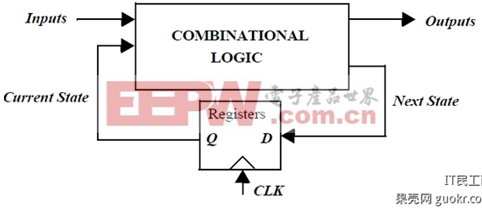
这是一个时序电路(sequential logic),换言之它的工作可以由下面的式子来刻画:
Sn+1=F(Sn,In)
Yn+1=G(Sn+1,In+1)
也就是说它根据上一个状态和上一个输入确定下一个状态,并且根据下一个状态以及下一个输入确定下一个输出。
在控制器当中,输入就是由指令译码器解码得到的控制信号,输出就是整个CPU中其他部分的控制信号。
看到最左侧的bus buffer了吗?它实际上就是储存/加载单元的雏形。
除了ALU和L/S单元以及控制器,还有各类连线,最显眼的可能就是寄存器了。
寄存器是CPU中速度最快的存储单元。这不单因为它的实现常常使用手工完成优化的触发器,而且还因为它就在核心的内部,距离其他部分的连线长度最短。一般来说,寄存器的读写只要1个时钟周期就可以了。可以将寄存器理解为一段程序的首要状态,这些状态最频繁地被读写。因此,你不难理解为什么有些爱耍小聪明的编译器总是变着法子把变量整到寄存器里去了吧。
另外一个值得注意的地方是图中的Program Counter,PC,程序指针。这个寄存器里的值就是将要取得下一条指令的具体的地址。所以它要和ALU连在一起,因为它总是要不停地递增。顺带提一句,PC除了各类跳转(jump)的指令之外一般轻易不会让用户赋值。天知道你要干什么不靠谱的事情!
当然我们不能忘了连线(interconnect),在图中就是那个4-bit bus。总线(bus)是一种易于实现的结构,如果你还记得前面讲过的电路,你就会知道只要在一般的逻辑电路和总线之间接一个传输门,配合上选通结构就可以正常工作了。但是总线是一种低效的结构,原因很简单:由于上面的电平是所有人都共享的,所以一时间只能有一个驱动总线的器件。这在4004中也许没什么大问题,但是当总线上挂载的器件很多的时候可以想象性能有多糟糕。和总线相反的另外一个极端是两两互联。毫无疑问这种连线可以实现最高的效率,但是它却给每个器件带来了非常大的复杂度,并且还不是可拓展的:你不可能往这个网络中无限制地添加器件还保证正确性了。
作为这个简短的帖子的结尾,我们来看一看4004是怎么计算1+2=?这个问题的吧。在以下的解释中,我略去了公共的IF,ID,以及PC递增的环节。
load reg1,mem1 --bus buffer->bus->reg1
load acc,mem2 --bus buffer->bus->accumulator(累加器,也是一个寄存器)
add acc,reg1 --reg1->bus->temp reg(这个寄存器是不可见的);
temp+acc->bus->acc(acc被加上了temp)
store mem3,acc --acc->bus->bus buffer
怎么样,是不是很累呢?
你也许奇怪为什么ALU只能接在acc和temp之间,为什么结果只能存在acc里。
答案是,intel刚发明4004的时候集成电路还是个新生产物,晶体管的集成在当时还是非常昂贵的。因此当时的考虑并不是时间上的性能,而是晶体管的分时复用,怎样让同样的单元实现最多的功能。
现在你能理解x86指令集中许多看起来奇奇怪怪的限制了吧。没错,它们就是这个原始的年代的遗留产物。
- 单片DSP处理器功能系统的SOPC技术设计(01-12)
- 数字信号处理器TMS320F241在变频空调中的应用(04-28)
- 用8位微处理器实现数字低通滤波器设计(05-15)
- 如何构造嵌入式Linux系统(05-23)
- 基于DSP的信号采集处理系统(07-21)
- 基于嵌入式Linux的便携式RFID信息采集与处理系统(07-01)