基于LD3320的非特定人语音识别方案
58 通过UART 接口或SPI接口通信方式,接收待合成的文本数据,实现文本到语音(或TTS语音)的转换[6]。控制器和SYN6658 语音合成芯片之间通过UART接口连接,控制器通过串口通信向SYN6658语音合成芯片发送控制命令和文本,SYN6658语音合成芯片把接收到的文本合成为语音信号输出,输出的信号经LM386 功率放大器进行放大后连接到喇叭进行播放。
如图6所示。
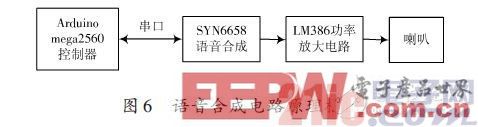
SYN6658语音合成电路采用芯片硬件数据手册提供的典型应用电路进行设计[5],在此不做介绍,功率放大电路采用美国国家半导体生产的音频功率放大器LM386进行放大。
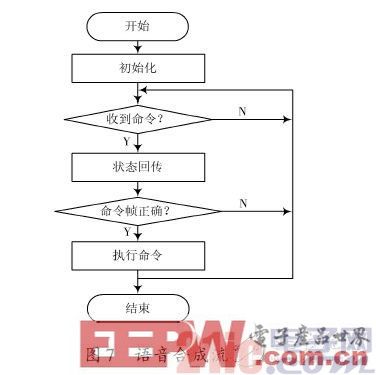
在进行语音合成时首先进行初始化,包括发音人选择、数字处理策略、语速调节、语调调节、音量调节等。
由于该系统要模拟多人发音,所以不同的从设备设置不同的发音人及语调与语速以便于区分。初始化后等待测控计算机的语音合成命令,待收到命令后芯片会向上位机发送1字节的状态回传,上位机可根据这个回传来判断芯片目前的工作状态。语音合成流程图如图7所示。
3 系统软件设计
示教与回放系统的软件设计包括测控计算机的软件设计和各从设备Arduino mega260控制器的软件设计。
测控计算机是整个系统的控制核心,其软件采用C#进行编写,在示教与回放系统中主要是对操作数据的记录以便根据所记录的数据对操作过程进行精确回放,需要记录的数据包括:各从设备操作人员的操作口令,操作动作,口令及动作时间,各操作对应的操作现象。为简化记录数据,事先编制好各事件代码,记录过程只记录代码,大大提高程序效率。建立结构体如下:

在操作训练过程中测控计算机每隔50 ms 对下位机进行控制及轮询,并记录反馈数据,在数据记录时以50 ms 为一个单位。采用定时器对时间进行控制。在回放过程中首先比对当前时间和所记录的时间,当所记录的时间与当前时间吻合时测控计算机控制下位机执行该事件,完成事件回放。
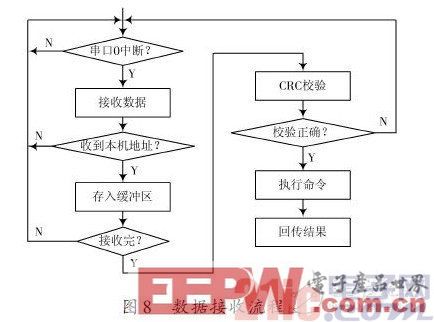
Arduino mega2560控制器负责接收测控计算机的控制指令并执行指令,读取语音识别结果,对声强数据采集和处理,控制语音合成单元进行语音合成等。Arduinomega2560 控制器采用串口中断的方式进行命令接收。
只有正确接收到命令才会执行并回传结果,若测控计算机在限定时间内未收到回传结果则表明发生错误,测控计算机需重新发送。数据接收流程图如图8所示。
4 总结
本文利用智能语音芯片设计了某模拟训练器的示教与回放系统,该系统不需要现在流行的虚拟现实技术的支持,仅在MCU 的控制下就可以运行。该系统也可以在小型的便携式设备上实现,具有良好的应用前景。
- 基于ARM的非特定人语音识别系统的设计方案(02-27)
- LD3320嵌入式语音识别系统应用(09-12)
- 基于AVR单片机的语音识别系统设计(08-08)
- Windows CE 进程、线程和内存管理(11-09)
- RedHatLinux新手入门教程(5)(11-12)
- uClinux介绍(11-09)