Mali GPU: 抽象机器(二) C 基于区块的渲染
定义一台抽象机器,用于描述 Mali GPU和驱动程序软件对应用程序可见的行为。此机器的用意是为开发人员提供 OpenGL ES API 下有趣行为的一个心智模型,而这反过来也可用于解释影响其应用程序性能的问题。我在本系列后面几篇博文中继续使用这一模型,探讨开发人员在开发图形应用程序时常常遇到的一些性能缺口。
这篇博文将继续开发这台抽象机器,探讨 Mali GPU系列基于区块的渲染模型。你应该已经阅读了关于管线化的第一篇博文;如果还没有,建议你先读一下。
“传统”方式
在传统的主线驱动型桌面 GPU 架构中 — 通常称为直接模式架构 — 片段着色器按照顺序在每一绘制调用、每一原语上执行。每一原语渲染结束后再开始下一个,其利用类似于如下所示的算法:
1. foreach( primitive )
2. foreach( fragment )
3. render fragment
由于流中的任何三角形可能会覆盖屏幕的任何部分,由这些渲染器维护的数据工作集将会很大;通常至少包含全屏尺寸颜色缓冲、深度缓冲,还可能包含模板缓冲。现代设备的典型工作集是 32 位/像素 (bpp) 颜色,以及 32 bpp 封装的深度/模板。因此,1080p 显示屏拥有一个 16MB 工作集,而 4k2k 电视机则有一个 64MB 工作集。由于其大小原因,这些工作缓冲必须存储在芯片外的 DRAM 中。
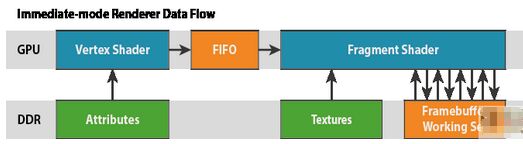
每一次混合、深度测试和模板测试运算都需要从这一工作集中获取当前片段像素坐标的数据值。被着色的所有片段通常会接触到这一工作集,因此在高清显示中,置于这一内存上的带宽负载可能会特别高,每一片段也都有多个读-改-写运算,尽管缓存可能会稍稍缓减这一问题。这一对高带宽存取的需求反过来推动了对具备许多针脚的宽内存接口和专用高频率内存的需求,这两者都会造成能耗特别密集的外部内存访问。
Mali 方式
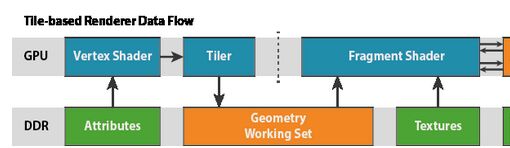
Mali GPU 系列采用非常不同的方式,通常称为基于区块的的渲染,其设计宗旨是竭力减少渲染期间所需的功耗巨大的外部内存访问。如本系列第一篇博文中所述,Mali 对每一渲染目标使用独特的两步骤渲染算法。它首先执行全部的几何处理,然后执行所有的片段处理。在几何处理阶段中,Mali GPU 将屏幕分割为微小的16x16 像素区块,并对每个区块中存在的渲染原语构建一份清单。GPU 片段着色步骤开始时,每一着色器核心一次处理一个 16x16 像素区块,将它渲染完后再开始下一区块。对于基于区块的架构,其算法相当于:
1. foreach( tile )
2. foreach( primitive in tile )
3. foreach( fragment in primitive in tile )
4. render fragment
由于 16x16 区块仅仅是总屏幕面积的一小部分,所以有可能将整个区块的完整工作集(颜色、深度和模板)存放在和 GPU 着色器核心紧密耦合的快速 RAM 中。
这种基于区块的方式有诸多优势。它们大体上对开发人员透明,但也值得了解,尤其是在尝试了解你内容的带宽成本时:
对工作集的所有访问都属于本地访问,速度快、功耗低。读取或写入外部 DRAM 的功耗因系统设计而异,但对于提供的每 1GB/s 带宽,它很容易达到大约 120mW。与这相比,内部内存访问的功耗要大约少一个数量级,所以你会发现这真的大有关系。
混合不仅速度快,而且功耗低,因为许多混合方式需要的目标颜色数据都随时可用。
区块足够小,我们实际上可以在区块内存中本地存储足够数量的样本,实现 4 倍、8 倍和 16 倍多采样抗锯齿1。这可提供质量高、开销很低的抗锯齿。由于涉及的工作集大小(一般单一采样渲染目标的 4、8 或 16 倍;4k2k 显示面板的 16x MSAA需要巨大的 1GB 工作集数据),少数直接模式渲染器甚至将 MSAA 作为一项功能提供给开发人员,因为外部内存大小和带宽通常导致其成本过于高昂。
Mali 仅仅需要将单一区块的颜色数据写回到区块末尾的内存,此时我们便能知道其最终状态。我们可以通过 CRC 检查将块的颜色与主内存中的当前数据进行比较 — 这一过程叫做“事务消除”— 如果区块内容相同,则可完全跳过写出,从而节省了 SoC 功耗。我的同事 Tom Olson 针对这一技术写了一篇 优秀的博文,文中还提供了“事务消除”的一个现实世界示例(某个名叫“愤怒的小鸟”的游戏;你或许听说过)。有关这一技术的详细信息还是由 Tom 的博文来介绍;不过,这儿也稍稍了解一下该技术的运用(仅“多出的粉色”区块由 GPU 写入 - 其他全被成功丢弃)。

我们可以采用快速的无损压缩方案 — ARM 帧缓冲压缩 (AFBC) — ,对逃过事务消除的区块的颜色数据进行压缩,从而进一步降低带宽和功耗。这一
- Windows CE 进程、线程和内存管理(11-09)
- RedHatLinux新手入门教程(5)(11-12)
- uClinux介绍(11-09)
- openwebmailV1.60安装教学(11-12)
- Linux嵌入式系统开发平台选型探讨(11-09)
- Windows CE 进程、线程和内存管理(二)(11-09)