基于听觉特性的声纹识别系统的研究
平稳的。为了得到短时的语音信号,对语音信号进行加窗计算。本课题主要选用的是汉明窗。汉明窗显示了一个好的窗口的优点。其在时域中波形细节不容易丢失,且能防止泄露。汉明窗函数式:
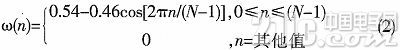
经过前面的一些处理之后,采集的语音信号就被分割成一帧帧的短时的加窗信号,把这些信号假设成随机平稳的信号,然后提取语音特征参数。
提取出来的语音参数,对其端点检测。此时,先设置门限,依据短时能量和过零率的公式,求出来短时能量值和过零率值。然后用手工方法在MATLAB上去除语音信号中的静音段和噪音语段来进行端点检测。
对系统的输入信号进行判断,准确地找到语音信号的起始点和终止点的位置。除去语音中的杂乱语音段,只有这样才能采集到真正的语音数据,减少数据冗余和运算量,并减少处理时间。如表3所示。在这里本课题用的是双门限法。将短时平均能量和短时平均过零率结合起来,进行端点检测,可以很好的检测语音是否开始和结束。

在本文的实验系统中,语音特征参数依次使用了12阶LPCC以及12阶MFCC。最后选定12阶MFCC参数。本课题建立的是与文本有关的声纹身份确认系统,用于测试模型是连续CHMM模型。
实验中我们用的是30 ms的汉明窗,依次计算它的特征参数,分别使用了12阶LPCC和12阶MFCC(24个Mel滤波器,语音信号的帧长度为256,信号的采样频率为8 000 Hz)和由此推导出的一阶MFCC差分参数。LPCC特征和MFCC特征识别率比较如表4所示。

表4显示了在测试人数为10人时,在相同的帧长下,MFCC特征的识别性能高于LPCC特征。这个结论又一次证明了倒谱特征的可区分性测度优于LPCC特征。
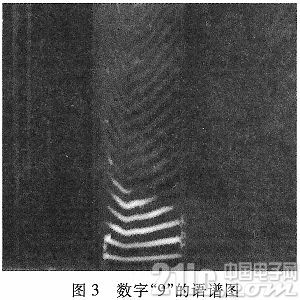
实验中,我们把第一个说话人的语音“9”,作为实验研究样本。图2是数字“9”的语音波形图,图3是数字“9”的语谱图。

MFCC参数是按帧计算的,在这里语音帧长度是256,信号采样频率是8 kHz,采用24个滤波器,MFCC特征阶数是12。MFCC的优点是在噪声的环境下,可以表现出对环境更强的鲁棒性。接下来一步要做的是对语音特征矢量序列进行矢量量化,矢量量化的数据压缩效果相当好,因此进行语音处理经常要用到。在本文的实验中,采用LBG法聚类生成码书。矢量量化之后这些语音特征参数就转变成语音模型。紧接着可以开始进行下一步的操作。
在训练阶段,对数字1~9建立HMM模型,就要对10个人进行每个数字10遍训练。第一天训练,第二天检测。每天一遍,一共两遍,首先把语音信号做端点检测,然后根据特征量计算出MFCC系数序列后,这里要用Baum-Welch算法建立各个说话人的HMM模型库。测试阶段,先保持和训练阶段一样,提取说话人测试语音中的特征矢量,然后根据维特比算法,并以各个说话人的HMM模板为参照,计算出来该输入序列的生成概率,根据最大的输出概率进行判决结果。对于本课题研究的身份确认系统,把概率值与判决门限相比较,其值大于或等于判决门限的声音作为受测者本人的声音被接受,小于门限的被拒绝。
2.2 实验结果分析
本文的实验是与文本有关的说话人身份确认系统。在实验中,分别按照不同人数进行训练,但是测试语音数保持不变。任意抽3个人朗读数字,在随后的实验中我们依次确定实验人数为5,7和10时,这时可以看出识别率会有一些大的差异。其结果如表5所示。
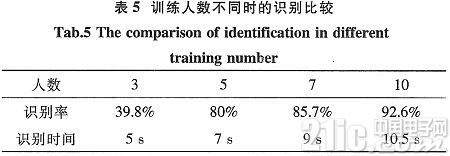
实验中的语音特征是MFCC,所用模型是连续CHMM,每一数字模型有4个状态。在这个身份确认系统中,在二值判定的前提下,确认受测者是否是之前所认定的某人。从表5可以看到识别的时间比较短,当有10个人训练时,识别率最大。为了训练出可靠的参数模型,必须加大训练集的数据。本实验由于条件限制,实验语音模板库比较小,训练数据不太充足,影响系统的一定性能。当训练数据足够大时,得修改补充一下程序的流程。本实验中系统的识别率达到了90%以上。
3 结论
本文的实验达到了预期的实验效果,基本完成了身份确认的目标。但是针对语音的特征提取和模式匹配,在实验中难免会出现一些误差,出现误认识和拒认识的偏差。对于说话人确认系统,虽然说从理论上来说,识别率和登录的说话者量无关,但是实际上对于二值判定的说话人确认系统也会随着登录人数的增减而有所改变,怎么样才能确保有足够多的登录者,登录到说话人确认系统中,而它的识别率问题仍然是一个很大的课题。
声纹识别 线性预测倒谱系数 MEL频率倒谱系数 隐形马尔可夫模型 相关文章:
- Windows CE 进程、线程和内存管理(11-09)
- RedHatLinux新手入门教程(5)(11-12)
- uClinux介绍(11-09)
- openwebmailV1.60安装教学(11-12)
- Linux嵌入式系统开发平台选型探讨(11-09)
- Windows CE 进程、线程和内存管理(二)(11-09)