Linux 网络文件系统的数据备份及恢复机制实现
版本生成算法。主要思想是:生成版本时不进行文件的复制,仅复制目录结构,在新版本生成后到下一版本生成前,如果有文件需要修改,则第一次修改时对该文件进行复制,从而保证该文件状态与对应的版本保持一致。
在一般情况下,目录结构的数据量远远小于文件的数据量,因而这种方法可以大大降低版本生成时需要复制的数据量,因而具有较高的性能。同时,这种把单个文件版本生成的实际操作推后到非做不可的时候,并且任意文件在两次版本之间最多生成一次版本,因此这种惰性策略可以使需要实际生成版本的文件数量达到最少,同时还可以把多个文件版本生成操作分散到具体的文件操作中,从而避免了集中的一次性版本生成方法可能造成的服务暂时停顿的问题。
版本生成后的结构如图 2 所示。
图 2 多版本生成示意图

具体算法包括两个部分,即版本生成算法和文件第一次修改处理算法,版本生成算法主要完成版本生成工作,主要过程如下:
找到需要形成版本的最高层目录作为原目录;
利用文件系统提供的函数,生成新的目录节点,称为新目录;
把原目录中的结构复制到新目录;
在原目录中找到所有的子目录,重复 2、3 步;
把新的子目录对应的 inode 号替换上一层目录中的老 inode 号;
重复上述过程,及到目录树中的所有目录得到复制为止。
在上述策略中,新版本并没有复制所有的文件,只是在复制的目录结构中记录下了该文件的 inode 号(即复制了目录的结构,而不是把文件都进行复制,从而节省了存储和计算资源),因此,当有 NFS 请求需要对文件进行版本生成后的第一次修改时,需要复制该文件,生成新的版本。该实现过程参见如下流程图:
图 3 写时复制算法示意图
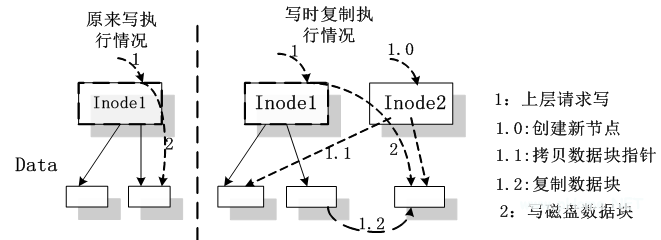
这种文件复制策略其实是一种惰性算法,也即我们常说的写时复制的方法,这个方法在 Linux 操作系统的子进程对父进程资源的继承中有所体现。这个策略一方面可以最大限度减少复制文件的数量,另一方面则可以避免瞬间过大的文件复制工作量,影响文件服务的性能。该算法的过程如下:当文件操作为写操作时,判断该文件是否版本生成后的第一次写操作;若是则利用文件系统提供的底层函数生成一个新的文件,复制源文件的数据到新生成的文件,同时把该文件当前版本的 inode 节点中的版本号置为当前版本号,这样新文件就成为该文件的最新版本。
虽然我们采用的算法可以有较好的性能,存储开销也是最优,但是,每次版本生成肯定会造成服务性能的下降和空间的占用,而这些代价在一个比较安全可靠的环境中是可以适当降低的,即当系统比较安全的时候,可以选择让系统以更低的频率进行版本生成,相反,当系统安全状况比较糟糕的时候,可以通过提高版本生成频率适当降低服务性能来获得更高的数据安全性能,当系统处于紧急状态时,甚至可以要求立即进行版本生成。
基于这些考虑,我们采用了自适应的备份策略,灾情评估系统可以动态评估系统的灾情程度,然后可以立即修改版本生成策略,以适应当时的安全要求。
NFS 数据恢复技术
企业应用 NFS 的一个重要目标就是要保证系统的高可用性,即使在出现严重灾难、故障、攻击等情况下能具有较好的生存能力。因此,当一个系统出现故障时,如何快速地恢复系统,迅速投入到服务备份中去是相当重要的,所以,对于文件系统数据的恢复而言,也需要专门的考虑和设计。
本方案被配置成多个站点互为备份的情况,即平时只有一个主站点在服务,其他站点处于同步备份状态,当某个站点出现故障或灾难时,或者是被非法入侵者攻破时,系统可以立即分配新的主站点把被破坏的站点替换下来,进入恢复状态,其他正常的站点仍可提供正常的服务。
当然,也存在所有站点均出现故障的情况,但是由于我们采用了多种措施,如动态随机迁移、灾情评估与响应策略等,再配合传统的防火墙、IDS 等安全系统,可以极大限度地减少这种几率。因此,我们的数据恢复问题主要考虑上述这种情形,即个别服务器出现故障退出服务而其他系统依然正常的情况。
首先,我们来分析一下系统退出后数据的情形,主要涉及到退出的服务器和正常的主服务器与备份服务器,如图 4 所示:
图 4 一个系统退出后数据状态示意图
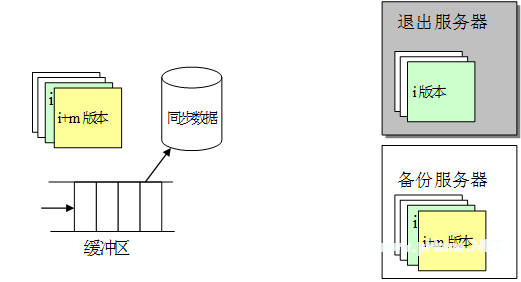
在上图中,退出服务器最后生成的版本号为 i,系统退出后,一方面主文件服务器会察觉到同步数据无法从退出服务器返回结果,这样的话它就会重发同步请求,经过 3 次重发后,如果依然没有返回信息,则认为该服务器退出服务,因此会把同步数据备份到磁盘文件中,并记录下该服务器在同步数据文件中的起始位置,这当由多个文件服务
- REDIce-Linux--灵活的实时Linux内核(11-12)
- linux文件系统基础(02-09)
- Linux标准趋向统一(11-12)
- linux基础技术(02-09)
- LINUX的目录树(02-09)
- 在Windows下启动Linux(02-09)