ARM920T的MMU与Cache之cache
Cache概念的基础,这种Cache应该很好理解,512条Cache Line分成8组,每组64条,地址0-31、256-587、512-543等等可以缓存到第1组64条Cache Line中的任何一条,地址32-63、288-319、544-575等等可以缓存到第2组64条Cache Line中的任何一条,依此类推。为什么说组相联Cache是全相联和直接映射Cache的一个折衷呢?如果把组分得很大,把全部Cache Line都分到一个组里面去,就变成了全相联Cache;如果把组分得很小,每组只有一个Cache Line,就变成了直接映射Cache。作为练习,请读者自己计算一下为什么VA Tag是VA[31:8],为什么组的编号用VA[7:5]表示。
那么,为什么组相联Cache的性能比直接映射Cache要好呢?一方面,组相联Cache把一条Cache Line上的冲突分散到了64条Cache Line上,起到了64倍的积极作用。而另一方面,应该缓存到同一个组的VA更多了:对于直接映射Cache,在同一个组(也就是同一条Cache Line)互相冲突的VA有4G/512个;对于组相联Cache,在同一个组(64条Cache Line)互相冲突的VA有4G/8个。从这个数量关系来看,组相联Cache又起到了64倍的消极作用。难道这两种作用不会完全抵销吗?我不打算从数学上严格证明,这不是本节的重点,读者可以通过一个生活常识的例子来理解:层数一样多的两栋楼,其中一栋楼是一部电梯,每层三户,而另一栋楼是两部电梯,每层六户,每户的平均人数一样多,你认为在哪个楼里等电梯的时间较短呢?
接下来解释一下有关Cache写回内存的问题。Cache写回内存有两种模式:
Write Back:Cache Line中的数据被CPU核修改时并不立刻写回内存,Cache Line和内存中的数据会暂时不一致,在Cache Line中有一个Dirty位标记这一情况。当一条Cache Line要被其它VA的数据替换时,如果不是Dirty的就直接替换掉,如果是Dirty的就先写回内存再替换。
Write Through:每当CPU核修改Cache Line中的数据时就立刻写回内存,Cache Line和内存中的数据总是一致的。如果有多个CPU或设备同时访问内存,例如采用双口RAM,那么Cache中的数据和内存保持一致就非常重要了,这时相关的内存页面通常配置为Write Through模式。
通过读写CP15的相关寄存器,可以对Cache做以下操作:
Clean:将Cache Line中的数据写回内存,清除Dirty位。在程序中的某些同步点上用于确保Cache Line和内存中的数据一致。
Invalidate:在Cache Line中有一个Invalid位表示无效,将这个位置1,下次要访问时即使VA Tag匹配也重新从内存读取数据。例如进程切换时需要声明前一个进程缓存在Cache中的数据无效。
Lock:将某个地址的数据锁定在Cache中,确保不被替换掉。在实时系统中,这样做可以保证某个地址的数据能在一个确定的时间内访问到。
从Cache中查找要访问的数据时用的是VA,但是Cache写回内存要用PA,如果写回内存时还需要查一遍页表就太没有效率了,所以实际上每条Cache Line中还保存了PA[31:5](PA Tag),完整的Cache构造如下图所示:

图 20. PA Tag
最后解决我们前面遗留的一个问题:页描述符中的C、B位具体是什么意思?
表 2. 页描述符中C、B位的含义
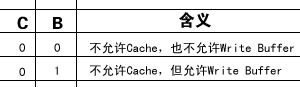
C位为1表示允许Cache,这种情况下用B位来表示Write Through还是Write Back。有些页面不允许Cache,置C位为0,这种情况下可以用B位来选择是否允许使用Write Buffer。Write Buffer也是一种简单的Cache,CPU核执行写指令时可以把数据交给Write Buffer,然后由Write Buffer负责写回内存,这时CPU可以执行后续指令而不必等待写回内存这个较慢的操作结束。想一下,既然有Write Buffer,为什么没有Read Buffer?
ARM920TMMUCach 相关文章:
- Windows CE 进程、线程和内存管理(11-09)
- RedHatLinux新手入门教程(5)(11-12)
- uClinux介绍(11-09)
- openwebmailV1.60安装教学(11-12)
- Linux嵌入式系统开发平台选型探讨(11-09)
- Windows CE 进程、线程和内存管理(二)(11-09)