基于语音识别的微博签到系统
近年来,语音识别在语音导航,室内设备控制,人际对话等方面得到了广泛的应用。
我们在今年第1期杂志《为设备添加社交网络功能》中,实现了W5500EVB自己发微博功能。试想如果我们把语音识别与微博签到结合起来,我们上班时,报上姓名,经识别后,摄像头为我们拍张照片,传到新浪微博,这样既能得到我们签到的时间,又能保证是本人签到,可靠高效,同时朋友通过微博能了解到我们上班时的状态,这样是不是很有意思呢?
今天要介绍的就是上面提到的,基于语音识别的微博签到系统,我们用摄像头ov2640拍照,LD3320做语音识别,然后W5500EVB把我们想说的话,以及照片发送到新浪微博。
基于语音识别的微博签到系统设计
(1)
a)
b)
c)
(2)
(3)
(4)
(5)
a)
b)
c)
d)
图1是系统实物图。

图1系统实物图
首先,我们了解一下整个程序流程,流程图由一个主流程图(见图2)和四个子流程图(图3,图4,图5,图6)组成。在STM32及ov2640初始化完成之后,将进行网络参数配置,根据自己网络的情况配置W5500的IP地址等网络参数,确保W5500能连接外网。然后配置LD3320语音模块,语音模块处于初始状态,将进行写入识别列表,启动语音识别过程,当我们对着麦克风说话的时候,LD3320检测到有语音输入,LD3320将进入中断,在中断中将把我们说的内容与寄存器里的词条比较,如果找到1-4个候选答案,返回“找到识别结果”状态,如果没有找到候选答案,返回“未找到识别结果”状态。在下一次循环中,LD3320如果是“找到识别结果”状态,将拍摄照片及发送微博,如果是“未找到识别结果”状态,将进入初始状态,如果是“正在识别”或者“识别错误”将重新检查LD3320的状态。各个子流程图描述的比较详尽,这里不再一一赘述。对于拍摄照片子流程图,我们需要了解jpg图片的数据格式,图片的前两个字节是0xff,0xd8,最后两个字节是0xff,0xd9,在中断程序接收图片数据的过程中,首先判断数据是不是前两个字节,如果是,保存数据,后面的数据是先保存,然后判断是不是数据结尾,直到接收成功。
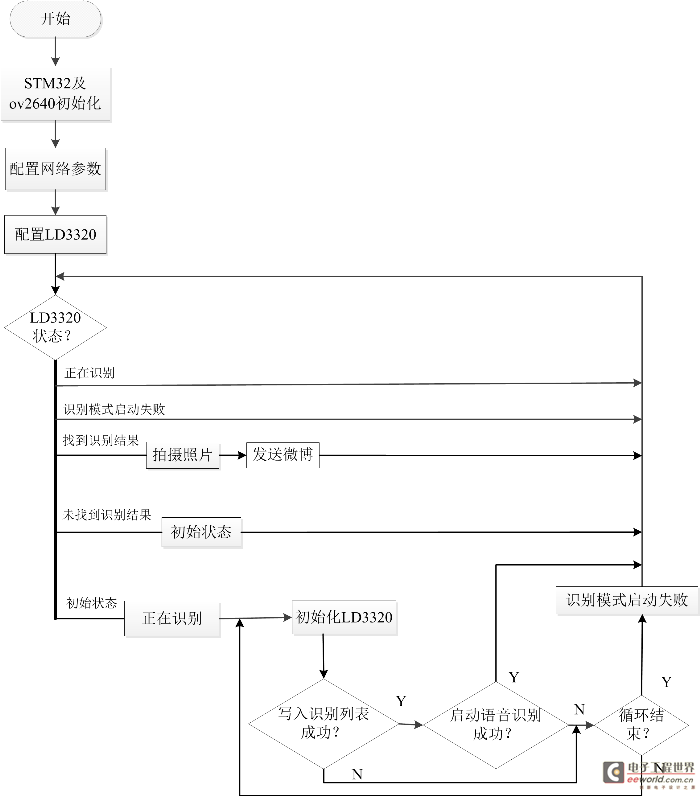
图2系统主流程图
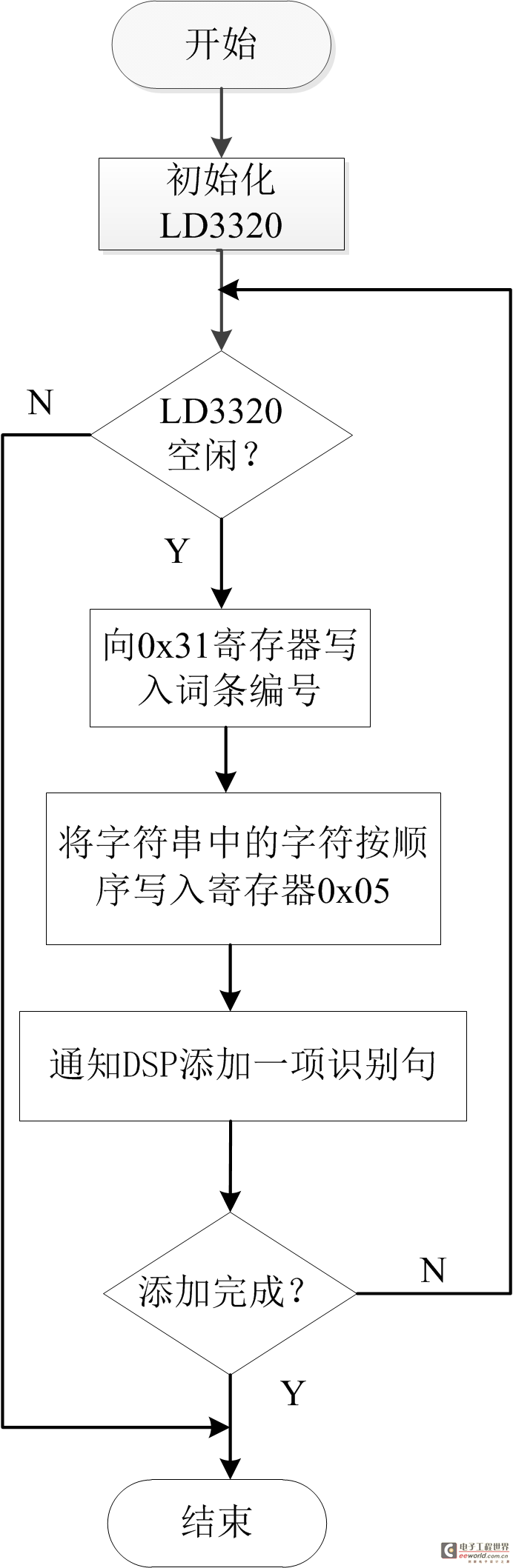

图3写入识别列表函数流程图
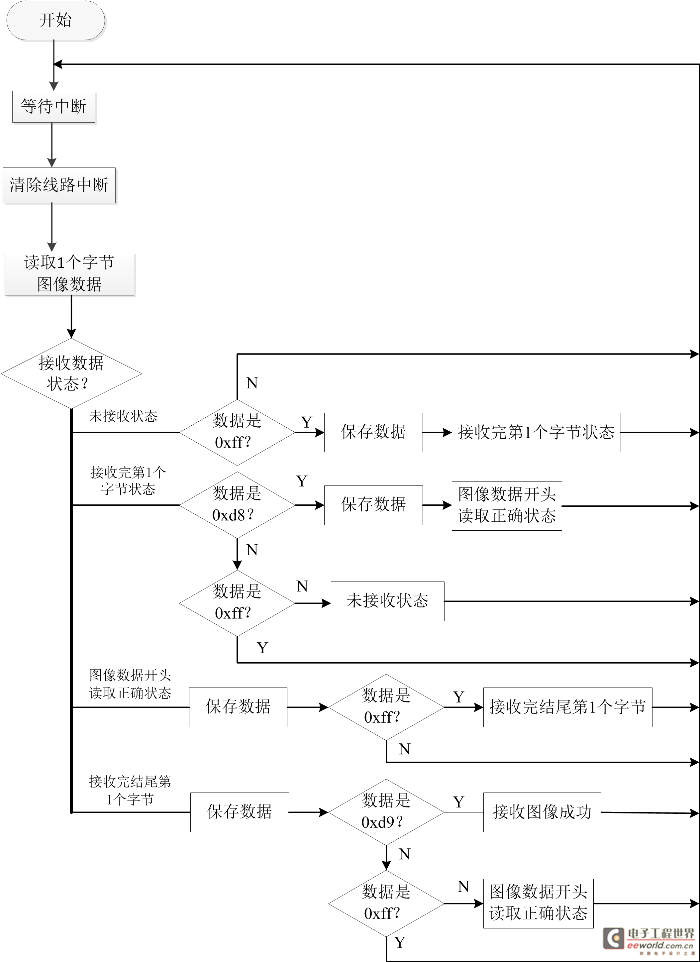
图5拍摄照片流程图

图6发送微博流程图
以上四个子流程图,已清晰地给大家展示语音识别微博签到系统的整个工作流程,那么接下来就为大家揭开详细的制作过程。
LD3320介绍
1 通过快速而稳定的优化算法,完成非特定人语音识别,识别准确率95%。
2 不需要外接任何辅助的Flash芯片,RAM芯片和AD芯片,就可以完成语音识别功能。
3 每次识别最多可以设置50项候选识别句,每个识别句可以是单字,词组或短句,长度为不超过10个汉字或者79个字节的拼音串。识别句内容还可以动态编辑修改。
4 芯片内部已经准备了16位A/D转换器、16位D/A转换器和功放电路,麦克风、立体声耳机和单声道喇叭可以很方便地和芯片管脚连接。
5 支持并行和串行接口,串行方式可以简化与其他模块的连接。
在本系统中采用的LD3320模块如图7,LD3320芯片外部已经连接了麦克风,耳机接口,基本电路,只引出了我们需要的引脚。本系统采用串行方式,串行接口通过SPI协议和外部主CPU连接,首先要将MD接高电平,将SPIS接地,选定LD3320工作在串行模式,此时使用的管脚有:片选(SCS*)、SPI时钟(SDCK)、SPI输入(SDI)和SPI输出(SDO),中断引脚(INT),复位引脚(RST),时钟引脚(CLK),通过SPI接口,配置LD3320的工作模式,读取识别结果,图8,图9为SPI读写时序。当LD3320识别到有语音输入,INT引脚将产生中断,在中断处理函数中,读取识别结果,改变LD3320状态。

图7LD3320语音模块
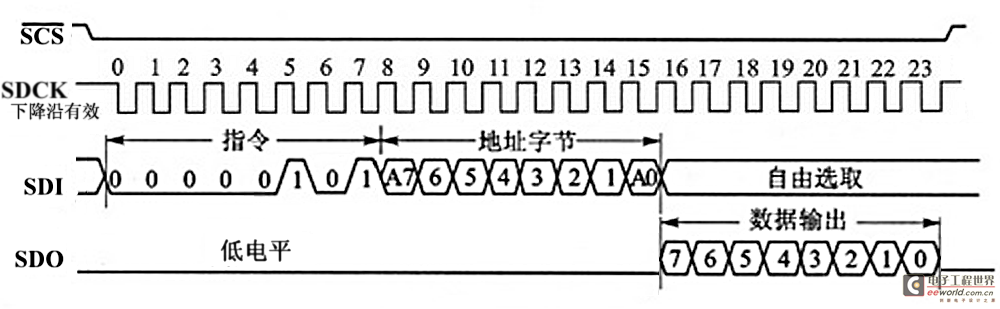
图8

图9 SPI方式写时序
在本系统中,OV2640输出JPEG压缩图像格式。MCU与OV2640的通信采用串行与并行结合,OV2640带有SCCB(Serial Camera Control Bus)双线串行接口,MCU通过SCCB接口配置和读取OV2640的信息;MCU通过并行总
语音识别签到系统STM32F103RCT 相关文章:
- Windows CE 进程、线程和内存管理(11-09)
- RedHatLinux新手入门教程(5)(11-12)
- uClinux介绍(11-09)
- openwebmailV1.60安装教学(11-12)
- Linux嵌入式系统开发平台选型探讨(11-09)
- Windows CE 进程、线程和内存管理(二)(11-09)