KEIL C51可重入函数及模拟栈浅析
;
func2(int b,int c, int *d):“b”在R6,R7中传递,“c”在R4,R5中传递,“d”则在R1,R2,R3中传递。
至于函数的返回值通过哪些寄存器或是什么方法传递这里就不说了,大家可以看看c51的相关文档或是书籍。
好了,接下来我们开始剖析一个简单的程序,代码如下:

程序很简单,废话少说,下面跟我一起看看c51翻译成的汇编语言是什么样子的(大存储模式下large XDATA)。
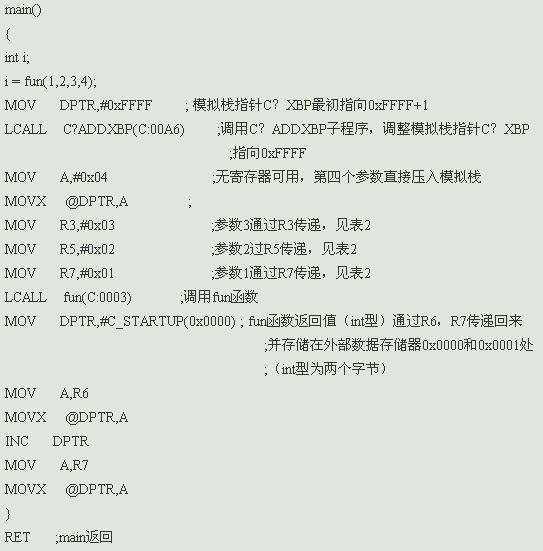
说明:模拟栈指针最初在startup.a51中初始化为0xFFFF+1;由以上汇编代码可以看出参数是从右往左扫描的。
接下来看看fun的汇编代码:(很长,大家耐心看吧,有些可以跳过的)



说明:栈结构如下

接下来说明两个重点子函数C_ADDXBP和C_XBPOFF


终于到尾声了,最后重点说明啦~~~
是向下生长的,C_XBP最初等于0xffff+1,那么请看下面这句

其实是这样:加0xffff相当与减1,加0xfffe相当与减2,加0xfffd相当于减3。。。。。。为啥,就不用说了吧:)
结束语:
经过了几天的研究,终于写了个总结报告,算是自己的一点小小成就吧,错误之处在所难免,希望能够同大家一起讨论问题,共同进步。
附录:
在其它环境下(比如PC,比如ARM),函数重入的问题一般不是要特别注意的问题。只要你没有使用static变量,或者指向static变量的指针,一般情况下,函数自然而然地就是可重入的。
但C51不一样,如果你不特别设计你的函数,它就是不可重入的.
引起这个差别的原因在于:一般的C编译器(或者更确切点地说:基于一般的处理器上的C编译器),其函数的局部变量是存放于堆栈中的,而C51是存放于一个可覆盖的(数据)段中的。
至于C51这样做的原因,不是象有些人说的那样,为了节约内存.事实上,这样做根本节约不了内存.理由如下:
1)
2)
真实的原因(C51使用覆盖段作为局部变量的存放地的原因)是:
51的指令系统没有一个有效的相对寻址(变址寻址)的指令,这使得使用堆栈作为变量的代价太过昂贵.
使用堆栈存放变量的一般做法是:
进入函数时,保留一段堆栈空间,作为变量的存放空间,用一个可作为基址寻址的寄存器指向这个空间,通过加上一个偏移量,就可以访问不同的变量了.
例如:
MOV EAX, [EBP + 14]
LDR R0, [R12, #14]
都可以很好的解决这个问题。但51缺少这样的指令.
其实,51中还是有2个可变址寻址的指令的,但不适合访问堆栈的局部变量这样的场合.
MOVC A, @A+DPTR
MOVC A, @A+PC
所以,C51有个特别的关键字: reentrant
KEILC51可重入函数模拟 相关文章:
- Windows CE 进程、线程和内存管理(11-09)
- RedHatLinux新手入门教程(5)(11-12)
- uClinux介绍(11-09)
- openwebmailV1.60安装教学(11-12)
- Linux嵌入式系统开发平台选型探讨(11-09)
- Windows CE 进程、线程和内存管理(二)(11-09)