基于并行计算的木马免疫算法研究
摘要:传统的木马检测技术在检测正确率、误报率和漏报率上都有不足,针时传统阴性选择算法在检测效率上的不足,提出一种基于并行计算的多特征区域匹配算法。这个算法首先把随机字符串分为多个特征区域,每个特征区域内对应一个检测器集合进行匹配,而且特征区域之间采用r连续位匹配方式再次匹配,同时采用并行计算,设置匹配阈值进行匹配确认。实验证明改进的阴性选择算法在匹配位数和随机字符串位数增加时,候选检测器增加速度较平缓,系统负担增加较缓慢,因此具有较好的检测效率。
关键词:并行计算;木马检测;免疫;算法
免疫算法是借鉴生物免疫系统中抗体识别抗原的原理发展起来的,是人工智能的一个新的研究领域,也是目前国内外研究的一大热点,许多研究学者都针对这一领域开展了深入、富有成效的研究工作。免疫算法主要模拟生物免疫系统中抗原处理的核心原理,运用免疫算法求解问题,本质上是抗体识别抗原的过程,而抗体(检测器)的产生是非常关键的一个步骤,关系到整个免疫检测系统的运行效率。
常见免疫算法主要有阴性选择算法和克隆选择算法等。阴性选择算法由Forrest等人在1994年提出,该算法步骤简单,但却实用有效,阴性选择算法以r连续位匹配规则为基础,实现局部匹配,算法效率较高。但其也存在着致命缺陷,因为当检测字符长度增加或者匹配位数r增加时,检测效率大大降低,系统开销大大增加。
文中提出一种改进的阴性选择算法,把总长度为L的字符串分成n个特征区域时,每一段特征区域产生一系列相应的检测器子集合,然后采用并行计算的匹配方式,对于整体则采用r连续位匹配规则进行匹配。设定匹配阈值,如果匹配度高于该阈值则两个字符串匹配,否则不匹配。
1 阴性选择算法
在免疫系统中,按照机体内外可以把整个机体分为“自我”和“非我”。将所要维护的正常模式行为或者系统的静态行为定义成“自我”,将异常行为模式定义为“非我”。阴性选择算法是个否定选择过程,目的在于区分“自我”和“非我”。设免疫系统整个空间为U,“自我”为S,“非我”为N,它们满足关系式:U=S∪N,S∩N=φ。阴性选择算法以r连续位匹配规则为基础,r代表一个阈值,是衡量单个检测器能匹配字符串子集大小的指标。
图1给出了采用阴性选择算法产生检测器的流程。

Forrest阴性选择免疫算法简述如下:1)分析问题,根据实际问题确定参数PM、NS、Pf、r,其中PM为匹配概率,NS为自体个数,Pf为期望的检测失败率,r为阈值;2)随机产生NS个长度为L的二进制字符串作为自体;3)计算所需检测器个数NR与候选检测器个数NH;4)产生检测器,即随机产生一个长度为L的字符串,并与自体进行比较,如果随机产生的字符串与自体中任何一个字符串匹配,则丢弃该字符串;如果随机产生的字符串与自体中所有字符串都不匹配,则保留该字符串作为检测器。重复该过程直到得到NR个检测器。其重复次数即为候选检测器个数NH;5)验证检测效果,即改变自体中的某个字符串,并用所有检测器与自体进行逐个比较,若出现匹配则表明检测成功否则检测失败。

由表1可知,匹配概率PM、检测失败率Pf对系统整体性能有很大影响。设定检测失败率只和自体规模NS在一定范围内的时候,决定候选检测器规模NH和检测器规模NR的只有匹配概率PM。当PM增大,NH和NR呈指数形式增加,这将导致检测时间大幅增加。而NH决定着系统的整体运行时间,NR决定着系统所占用的空间,因此PM的选择范围对整个系统性能起着决定性作用。传统阴性选择算法采用随机生成字符串的形式,匹配概率PM的值就由两个字符串间的匹配规则、匹配位数来决定。
如果采用完全匹配规则(r=L),则当且仅当两个随机字符串相应位置的每一位字符均相同时,则两个字符串匹配,其匹配概率为PM=1/2L;如果采用部分匹配规则,即rL时,则匹配概率PM≈m-r[(l-r)(m-1)m+1]。当在试验中字符串采用二进制码,即m=2时,匹配概率公式则变为PM≈2-r[(l-r)/2+1]。
候选检测器NH的数量将随着“自我”集合中二进制编码长度的增加成指数级增长,经阴性选择的检测器没有经过冗余检查就直接将其作为成熟检测器中的一个元素进入下一个环节,这可能导致成熟检测器集合R中的数据冗余。尽管在Forrest之后也提出了一些改进方法,如线性算法、贪婪算法、二进制模块算法,但都没有很好地解决上述问题。
2 阴性选择算法的改进
Forrest阴性选择算法中步骤4随机产生一个长度为L的字符串,并与自体进行比较,一般是采用局部匹配的方式进行比较,也就是采用r连续位匹配的方式;如果匹配位数r太小,在“自我”和“非我”相似度较大时,检测器会把“非我”当成“自我”而删除;但是随着r的增加和字符串L的增加,匹配次数呈指数形式增加,匹配效率明显不足,并且会产生大量的候选检测器,使得该算法时间复杂度太大,因此,在实际应用中就存在一个如何选择字串长度和匹配区域的问题。
文中提出一种基于并行计算的多特征区域匹配方式,产生检测器和自体进行匹配,然后对于冗余的候选检测器进行筛选,最后产生成熟检测器。
该算法步骤如下:
1)把总长度为L的字符串分成n个特征区域,每个特征区域长度记为Li(i=1,2,3…,n);
2)每一段特征区域产生一系列相应的检测器子集合Ni(i=1,2,3…,n),用这个检测器子集合对相应的特征区域进行特征匹配,各个特征区域的检测器集合是相互独立的,整个字符串的检测器集合N={N1,N2,N3…,Nn};
3)对于每一个特征区域,采用并行计算的匹配方式,采用多指令流多数据流(MIMD)的体系结构。把自体串和特征区域放人两个数组中进行比较,通过n个处理器并行计算;
4)根据检测器子集合对每一个特征区域进行检测,得到它的匹配长度ri,设定每个特征区域的重要性权值Ii,有0≤ri≤li,0≤Ii≤1;
5)设定Mi表示特征区域的匹配情况,Mi=1表示该特征区域匹配,Mi=0表示不匹配,对于由各个特征区域组成的整体字符串,采用r连续位匹配规则进行匹配,得到它的匹配度R;6)设定匹配阈值μ,如果公式(1)成立,则两个字符串匹配,否则不匹配。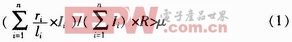
对于r连续位匹配算法,影响算法的主要因素是样本个数、字符串长度和连续位数。运用以往的r连续位算法,要至少遍历两个字符串的对应位置,但是如果采用并行算法,最佳效果是仅匹配一次即可成功,这将大大减少计算量,并增加运行效率。对于木马检测这种对实时反应时间要求较高的匹配模式来说,运用并行算法能较好地提高检测成功率和减少误报率;本算法采用了特征区域生成的办法产生检测器集合,以避免由于匹配区域r增大所带来的效率过低的问题,改进算法能较快速高效地产生满足精度要求的检测器集合。
但是对于各个特征区域,该算法都要产生一系列对应的检测器子集合,各个特征区域的检测器集合是独立的,因此区域与区域之间的检测器有可能会重复,从而产生检测器冗余。针对这个问题,文中加入了冗余检测器筛选步骤,对经过改进的阴性选择算法后产生的候选检测器进行筛选,把它们和已经存在的成熟检测器进行比对,判断该候选检测器是否重复,如果是重复的则删除该检测器,否则把它加入到成熟检测器集合中。
实验1:设定其他的参数不变,在不同的自体规模(即Ns)下进行实验,仿真结果如表2所示。
- 免疫荧光技术的实验方法及其分类(01-11)
- 高等级公路路面裂缝类病害轮廊提取的算法研究(04-12)
- 基于视觉图像的微小零件边缘检测算法研究(08-25)
- 频宽、取样速率及奈奎斯特定理(09-14)
- 为什么要进行信号调理?(09-30)
- IEEE802.16-2004 WiMAX物理层操作和测量(09-16)