协处理器作为独立加速器提升用户体验
当今的消费者对技术的要求日益提升,这一点在用于与设备进行互动的界面技术上体现得尤为明显。人们对包括手机、车载电子、家用网络和办公环境下的设备要求越来越高,要求它们能够融入更易操作的、更直观的用户界面,以更贴切反映人与人之间的互动关系。
在每一个新的产品周期中,设计人员都倍感压力,要设计出操作更加精确、用户界面更加直观的产品。近年来,继触屏技术逐渐普及到包括电话、平板电脑、显示器、销售点解决方案、ATM和查询机等设备之后,语音识别技术正在快速成为驱动产品创新与运用的下一代用户界面技术。语音识别,甚至是手势与影像识别,成为各种工作与个人设备的标准配备只是个时间问题。由于语音识别技术在某种程度上受制于嵌入式应用的发展,因此其至今仍然处于发展的初期。然而,语音识别交互界面技术将最终被广泛采用,这是技术发展的大势所趋。
正如大多数设计人员所熟知的那样,用户界面越直观,其所需的技术平台与设计就越复杂。用户界面技术将消耗更多的计算能力与闪存,才能在达到高性能的处理能力的同时,保持最佳用户体验。一种解决方案是采用专门的硬件,即具有下一代闪存能力、集成了逻辑与灵活软件算法的专用协处理器。这些协处理器能够作为独立的硬件加速器分担主应用处理器的负担,从而获得市场上最高水平的用户体验。
人机交互界面的演进
自从电脑鼠标问世以来,HMI(人机交互)技术取得了长足进步。用户界面的创新从历史上看可归功于新器件的成功运用。打造具有吸引力的用户界面极具挑战性,需要相当复杂的系统来创造功能性强、易于访问、逻辑清晰与令人愉悦的用户体验。这种复杂系统对高可靠性、高性能硬件提在处理能力和闪存带宽方面要求较高。由于终端产品的核心功能创新已接近成熟,消费者们正日益将产品的工业设计与用户界面作为标准来做出购买决定。生产商也注意到了这一变化,而闪存生产商与设计人员也在市场的压力下,加快创新以回应市场的要求。语音识别正是下一波人机交互技术创新的焦点之所在。语音识别如何处理工作
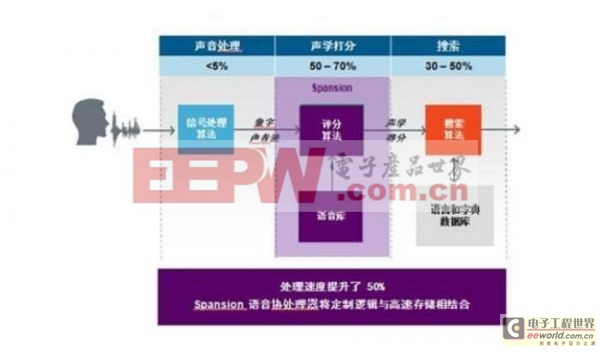
在先进的HMI技术正日益成为许多消费电子产品事实上标准的同时,高性能处理能力对嵌入式系统而言正变得的更为关键。总体而言,语音识别功能可被细分为三个处理阶段:
第一个阶段是声音处理阶段,这通常会占用不到5%的处理能力,即系统将捕获的声音信号从模拟信息转化为数字信息。这同时也是过滤、抑制噪声和回声消除的阶段,将话筒声音与错误捕获的杂音区分开来。经过处理后的信号以数字声音流的形式输出,每一段声音都如同指纹一样是独一无二的。第二个阶段为匹配阶段,即系统将这些声音信号与“语音库”,即声学模型进行匹配。这种匹配阶段被称作声学打分,会占用系统处理带宽的50%到70%。第二阶段产生的声学得分将作为输入信息进入第三个阶段,即系统通过搜索语言与词典模型,将这些声学信号转译为文字信息。这一阶段会占用30%到50%的处理能力。
一般说来,整个处理过程由一个CPU负责,而这个处理器也同时需要负责处理若干其他的任务。由于语音识别非常占用计算能力与闪存空间,因此在一个嵌入式解决方案共享资源会导致无法接受的延迟,或者限制了带宽处理日益增加的软件模型的能力。为了取得更高的精确性,软件模型的大小正在日益膨胀。
为何为HMI处理过程配备专门的硬件?
由于HMI(如语音识别)处理过程中繁重的存储与运算带宽限制,这种多任务共享一个CPU资源的方式常常以牺牲某些终端用户体验为代价。
例如,在语音识别中,在共享资源的嵌入式系统条件下,设计人员必须在速度与精确性之间进行取舍。更大的声学模型能实现更高的精确性,不过却要有更大的处理能力才能避免无法接受的延迟响应速度。另外,由于用户提升了他们对语音处理界面的期望,例如希望界面能够区分性别、噪音、对话、口音以及多语言等,这种功能丰富的语音模块的大小则会呈指数级别与日俱增,而可靠性高、可快速访问的内存对这种日益提升的性能而言将变得更加重要。 不幸的是,如今资源共享、资源限制型的硬件平台并不能为目前最大型的声学模型提供可接受的处理能力。因此,业内目前只能退而求其次,开发出压缩版的声学模型,仅能在最低程度可接受的响应时间内提供最低程度可接受的精确性。
为了克服这个缺点,业界最近已经开发出了一套解决方案:一款能够提升处理能力,加速某些语音识别处理阶段的专用硬件协处理器。这类解决方案的第一个代表就是Spansion语音协处理器。Spansion语音协处理器负责语音识别的声学评分阶段,从而分担了CP
- 电源设计小贴士 1:为您的电源选择正确的工作频率(12-25)
- 用于电压或电流调节的新调节器架构(07-19)
- 超低静态电流电源管理IC延长便携应用工作时间(04-14)
- 电源设计小贴士 2:驾驭噪声电源(01-01)
- 负载点降压稳压器及其稳定性检查方法(07-19)
- 电源设计小贴士 3:阻尼输入滤波器(第一部分)(01-16)