基于多任务嵌入式应用的MP3实时解码系统设计
1 引 言
MP3是目前世界上流行的音频格式之一,采用MPEG-1标准的Audio LayerⅢ压缩编码格式,具有高压缩率和保真度。MP3的解码功能大多以专用解码芯片的形式应用于多种消费类电子产品中。采用软解码的方式实现MP3实时播放功能可以充分利用硬件资源,节省芯片面积,有利于降低设计成本,同时软件方式可移植性好,解码质量可通过软件参数设定,具有更大的灵活性,便于系统升级。随着主流嵌入式微处理器ARM的处理能力越来越强,这种实现方式也已经成为众多嵌入式设计公司研究的焦点。
与专用解码芯片相比,采用软件方式实现MP3实时解码的瓶颈在于解码效率。在多任务嵌入式系统中,单个任务的执行效率以及任务间的调度方式将直接影响整个系统在一定硬件资源条件下的实时响应速度。因此,在多任务嵌入式系统中采用软解码方式实现MP3实时播放,必须通过优化算法提高解码效率,在保证实时性的基础上降低对硬件资源的要求。
2 设计思想
MP3解码需要经过大量的数据处理。首先对MP3数据流进行帧同步并解出头信息和边信息供解码主数据使用,之后对主数据依次进行霍夫曼解码、反量化、IMDCT以及子带合成滤波,最终输出PCM码流。整个解码过程如图1所示。对定点化开源解码程序各模块执行时间进行测试,找出关键耗时模块并对其采用改进型快速算法;在保证一定音质的前提下,根据解码运算特征降低运算精度,从而在基于ARM926EJ-S处理器开发平台上实现对MP3音乐(码率为192 kb/s,采样率为44.1 kHz,立体声编码模式)的解码;在实时播放方面,提出双Buffer轮换DMA传送的设计方案,为高效任务调度的实现提供有利条件。
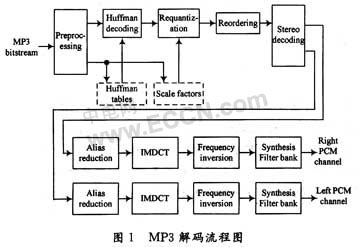
3 系统实现过程
3.1 硬件系统
本文采用的嵌入式系统是以ARM926EJ-S处理器为核心的SoC开发平台,最高运行主频为190 MHz,支持ARMv5T指令集,存储器包括SDRAM和NAND FLASHROM,外围设备包括DMA控制器、中断控制器、USB控制器、UART、控制器、I2S控制器以及定时/计数器。整个硬件系统的架构如图2所示。
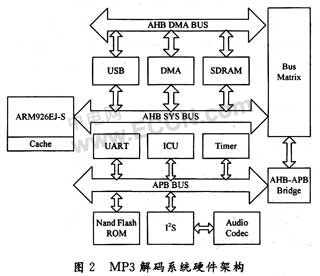
MP3文件和程序代码通过USB线下载并分别存放入NAND FLASH ROM和SDRAM;解码MP3文件得到的PCM码流送入I2S控制器输出;UART控制器可实现串口打印输出调试信息,跟踪程序运行状态;定时/计数器用于测试解码时间,对解码各个模块进行耗时分析。
3.2 代码移植
搭建好硬件平台后,对各硬件模块进行初始化,并加载文件系统,完成软件平台的搭建。将开源的MP3解码程序代码移植到软件平台上,这一过程主要是针对平台的文件系统,对文件读写函数进行替换,并将屏幕打印替换为串口打印操作。移植后的代码实现对MP3文件进行解码,并输出为PCM码流文件。利用CoolEdit对输出PCM码流文件进行测试播放,输出音质良好。
3.3 耗时分析
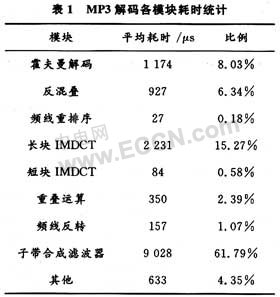
成功移植后,对代码进行耗时分析,找出耗时最大的功能模块,确定重点优化对象。该系统采用硬件定时/计数器作为测试工具,将计数器的计数频率调配为1 MHz,可实现1μs的测试精度。在ARM工作主频为150 MHz的条件下,对100帧MP3数据的解码过程进行耗时测试,测试结果如表1所示。根据表1测试数据可知,子带合成滤波占了整个解码时间的60%以上,是决定解码速度的最关键模块;其次是长块IMDCT运算,占了整个解码时间的10%以上。因此,子带合成滤波与长块IMDCT成为优化重点。
3.4 解码算法分析与优化
3.4.1 子带合成滤波算法优化
子带合成滤波是MP3解码过程中最耗时的关键流程,该解码系统采用Konstantinos Konstantinides提出的改进型算法对其进行优化。子带合成滤波的标准算法涉及从32值变换到64值的矩阵运算,Konstantinos Konstantinides提出的改进型算法将矩阵运算进行一系列变化,最终归结于32点DCT变换,而DCT变换有类似于FFT的快速算法(FCT),从而加速了整个子带合成滤波过程。由DCT变换到矩阵运算的转换过程如图3所示,其中S和V分别为矩阵运算的32点输入序列和64点输出序列,A,B均为16点矢量。
3.4.2 IMDCT算法优化
IMDCT采用Szu-Wei Lee提出的快速算法进行优化,该算法充分利用余弦函数的对称性,将N点IMDCT运算经过一系列变形,最终转化为N/4点的SDCT-Ⅱ运算,其转化流程如图4所示。对短块IMDCT使用该算法并没有带来较大的速度改善,故只对长块应用。相比于直接运算的648次乘法和612次加法,优化后的长块。IM-DCT运算量下降为43次乘法和115次加法。
3.4.3 低精度乘法
在ARM指令集中的乘法指令有2类:32 b×32 b→64 b长乘法指令(MULL,MLAL)和32 b×32 b→32 b短乘法指令(MUL,MLA),前者的
MP3 相关文章:
- 便携设计中面向特定应用的高速开关(09-18)
- STMP36xx系列音视频编解码芯片解决方案详解(04-07)
- 基于Zigbee技术家用无线网络的构架(12-14)
- 无线通信领域中的模拟技术发展趋势(蜂窝基站)(09-22)
- 新一代移动通信系统及无线传输关键技术(06-19)
- 蜂窝移动通信基站电磁辐射对人体影响的探讨(04-10)