嵌入式实时英语语音识别系统的设计和实现
时间:12-22
来源:互联网
点击:
随着移动设备的快速发展,迫切需要一种更友好、更便捷的用户操作系统。自动语音识别系统能够提供便利的人机交互,将成为一种主要方法。目前,实验室环境中自动语音识别系统已经取得了很好的效果,但需要很大的存储空间和运算资源。当自动语音识别应用于移动设备时,必须对模型和识别策略进行相应改进,才能满足其对运算速度、内存资源和功耗的要求。为了解决这个问题,本文将结合英语语音的特点,设计并实现嵌入式英语语音识别系统,完成中等词汇量的孤立词实时识别任务。
1 硬件平台
嵌入式系统的软硬件高度结合,针对系统的特定任务,要量体裁衣、去除冗余,使得系统能够在高性能、高效率、高稳定性的同时,保证低成本和低功耗。因此,系统硬件平台的选用是影响系统整体性能的关键因素。系统采用Infineon公司Unispeech 80D51语音处理专用芯片作为核心的硬件平台,该芯片集成了一个16位定点DSP核(OAK)、一个8位MCU核(M8051 E-Warp)、两路ADC、两路DAC、104KB的SRAM以及高灵活性的MMU等器件。其中DSP最高工作频率可达100MHz,MCU最高工作频率为50MHz。
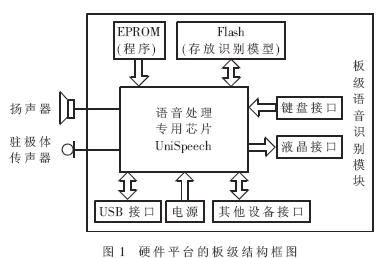
由于系统的语音处理专用芯片UniSpeech集成了大部分的功能单元,片外所需元件很少,因此系统硬件平台的板级结构非常简单。图1为硬件平台的板级结构图。
专用芯片只需外接:
(1)EPROM:存放系统程序;
(2)Flash Memory:存放语音识别系统需要的声学模型参数和系统中的语音提示、语音回放数据;
(3)语音输入器件:可直接外接麦克风,接收语音信号;
(4)语音输出器件:可直接外接扬声器或耳机,输出系统的提示音;
(5)电源:通过电压变换芯片,为电路板上各芯片提供需要的电压;
(6)USB接口:该板级语音识别模块提供了USB接口,以提高该嵌入式系统和通用计算机系统之间数据交换的速度;
(7)键盘:提供外接键盘接口,方便系统控制;
(8)液晶:可外接一块液晶显示屏,以输出识别结果;
(9)其他设备接口:为了增强该语音信号处理模块的功能扩展性,UniSpeech提供了丰富的I/O资源,共有100条通用I/O,系统也预留了这些I/O接口,以方便与其他设备连接。
2 算法研究
2.1 两阶段识别算法
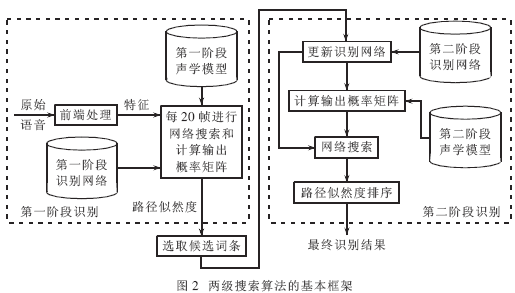
在英语语音识别系统中,常用的声学模型基本单元是单词(Word)、上下文无关音素(Monophone)、上下文相关音素(Triphone,Biphone)和音节(Syllable)。单词模型由于其灵活性太差及计算时间和占用内存随待识别单词数的增加而线性增长,所以在嵌入式语音识别系统中很少应用。Monophone模型具有模型简单、状态数较少、识别速度快、内存占用少且与识别词汇量无关等优点,但其对发音的相关性描述不够精确,一选识别率不高。Triphone和Syllable模型对发音相关性能准确建模,但模型数量巨大、状态数较多、识别速度慢、内存占用多。为了解决内存占用量与识别速度之间的矛盾,本文采用了两阶段搜索算法,其基本流程如图2所示。
在第一阶段识别中,采用monophone模型和静态识别网络,得到多候选词条;在第二阶段识别中,根据第一阶段输出的多候选词条,构建新的识别网络,采用triphone模型,进行精确识别,得到最终的识别结果。由于第二阶段识别的词条数较少,与只采用triphone模型的一阶段识别相比,识别速度大大提高;同时,第二阶段识别可重用第一阶段的内存资源,也减少了识别系统的内存占用量。
2.2 特征提取与选择
在连续语音识别系统中,通常采用39维的MFCC(Mel Frequency Cepstral Coefficient)特征,甚至再加入一些特征。但是,考虑到嵌入式系统有限的硬件资源,在不降低识别率的基础上,应尽量减少特征的维数。本文采用最小互信息改变准则MMIC(Minimum Mutual Information Change)进行特征选择。一阶段采用22维MFCC特征(9 MFCC,6 ΔMFCC,4 Δ2MFCC,E,ΔE,Δ2E),二阶段采用26维MFCC特征(10 MFCC,7 ΔMFCC,6 Δ2MFCC,E,ΔE,Δ2E)。
2.3 数据的输入输出
对于硬件系统,如果数据的读入速度较慢,则对运算速度影响就很大。在保证系统高识别率的前提下,系统的内存消耗量和识别时间常常是一对矛盾体,很难保证两者同时达到理想状态。如果仅仅考虑节省内存,将每个词条识别网络和相应的状态逐个读入,计算匹配分数,这样虽然可以最大限度地节省内存的使用量,但是数据的多次读入占用了大量时间,并且反复计算同一个转移概率,也对识别时间影响很大。另一方面,如果仅仅考虑运算速度,一次性将所有词条的识别网络和所有状态模型读入内存,虽然仅需一次数据读入,运算速度大大提高,但却对内存提出了更高要求。为了更好地利用系统的硬件资源,本系统首先逐个读入状态模型,计算所有观察矢量在各状态模型下的输出概率,存放在内存中;然后逐条读入识别网络,选取路径似然度最高的词条作为最终的识别结果。这样综合了前面两种方案的优点,适应了硬件系统的要求。
1 硬件平台
嵌入式系统的软硬件高度结合,针对系统的特定任务,要量体裁衣、去除冗余,使得系统能够在高性能、高效率、高稳定性的同时,保证低成本和低功耗。因此,系统硬件平台的选用是影响系统整体性能的关键因素。系统采用Infineon公司Unispeech 80D51语音处理专用芯片作为核心的硬件平台,该芯片集成了一个16位定点DSP核(OAK)、一个8位MCU核(M8051 E-Warp)、两路ADC、两路DAC、104KB的SRAM以及高灵活性的MMU等器件。其中DSP最高工作频率可达100MHz,MCU最高工作频率为50MHz。
由于系统的语音处理专用芯片UniSpeech集成了大部分的功能单元,片外所需元件很少,因此系统硬件平台的板级结构非常简单。图1为硬件平台的板级结构图。
专用芯片只需外接:
(1)EPROM:存放系统程序;
(2)Flash Memory:存放语音识别系统需要的声学模型参数和系统中的语音提示、语音回放数据;
(3)语音输入器件:可直接外接麦克风,接收语音信号;
(4)语音输出器件:可直接外接扬声器或耳机,输出系统的提示音;
(5)电源:通过电压变换芯片,为电路板上各芯片提供需要的电压;
(6)USB接口:该板级语音识别模块提供了USB接口,以提高该嵌入式系统和通用计算机系统之间数据交换的速度;
(7)键盘:提供外接键盘接口,方便系统控制;
(8)液晶:可外接一块液晶显示屏,以输出识别结果;
(9)其他设备接口:为了增强该语音信号处理模块的功能扩展性,UniSpeech提供了丰富的I/O资源,共有100条通用I/O,系统也预留了这些I/O接口,以方便与其他设备连接。
2 算法研究
2.1 两阶段识别算法
在英语语音识别系统中,常用的声学模型基本单元是单词(Word)、上下文无关音素(Monophone)、上下文相关音素(Triphone,Biphone)和音节(Syllable)。单词模型由于其灵活性太差及计算时间和占用内存随待识别单词数的增加而线性增长,所以在嵌入式语音识别系统中很少应用。Monophone模型具有模型简单、状态数较少、识别速度快、内存占用少且与识别词汇量无关等优点,但其对发音的相关性描述不够精确,一选识别率不高。Triphone和Syllable模型对发音相关性能准确建模,但模型数量巨大、状态数较多、识别速度慢、内存占用多。为了解决内存占用量与识别速度之间的矛盾,本文采用了两阶段搜索算法,其基本流程如图2所示。
在第一阶段识别中,采用monophone模型和静态识别网络,得到多候选词条;在第二阶段识别中,根据第一阶段输出的多候选词条,构建新的识别网络,采用triphone模型,进行精确识别,得到最终的识别结果。由于第二阶段识别的词条数较少,与只采用triphone模型的一阶段识别相比,识别速度大大提高;同时,第二阶段识别可重用第一阶段的内存资源,也减少了识别系统的内存占用量。
2.2 特征提取与选择
在连续语音识别系统中,通常采用39维的MFCC(Mel Frequency Cepstral Coefficient)特征,甚至再加入一些特征。但是,考虑到嵌入式系统有限的硬件资源,在不降低识别率的基础上,应尽量减少特征的维数。本文采用最小互信息改变准则MMIC(Minimum Mutual Information Change)进行特征选择。一阶段采用22维MFCC特征(9 MFCC,6 ΔMFCC,4 Δ2MFCC,E,ΔE,Δ2E),二阶段采用26维MFCC特征(10 MFCC,7 ΔMFCC,6 Δ2MFCC,E,ΔE,Δ2E)。
2.3 数据的输入输出
对于硬件系统,如果数据的读入速度较慢,则对运算速度影响就很大。在保证系统高识别率的前提下,系统的内存消耗量和识别时间常常是一对矛盾体,很难保证两者同时达到理想状态。如果仅仅考虑节省内存,将每个词条识别网络和相应的状态逐个读入,计算匹配分数,这样虽然可以最大限度地节省内存的使用量,但是数据的多次读入占用了大量时间,并且反复计算同一个转移概率,也对识别时间影响很大。另一方面,如果仅仅考虑运算速度,一次性将所有词条的识别网络和所有状态模型读入内存,虽然仅需一次数据读入,运算速度大大提高,但却对内存提出了更高要求。为了更好地利用系统的硬件资源,本系统首先逐个读入状态模型,计算所有观察矢量在各状态模型下的输出概率,存放在内存中;然后逐条读入识别网络,选取路径似然度最高的词条作为最终的识别结果。这样综合了前面两种方案的优点,适应了硬件系统的要求。
嵌入式 DSP MCU ADC DAC 电压 电路 USB 滤波器 相关文章:
- 嵌入式系统的定义与发展历史(11-15)
- 嵌入式系统亲密接触(11-22)
- 嵌入式系统设计中的USB OTG方案(02-01)
- 嵌入式线控驾驶系统开发过程中设计和测试考虑(02-02)
- 一个典型的嵌入式系统设计和实现 (02-02)
- DDR SDRAM在嵌入式系统中的应用(02-07)