高性能32位内核与基于微控制器存储架构的集成
时间:09-28
来源:互联网
点击:
提高CPU内核性能——闪存接口
来自高性能计算环境的一个通用概念是高速缓存,在主要存储器件和处理器内核之间采用更小及更快的内存存储,可以实现突发数据或程序指令的更快访问。
设计和实现高速缓存可能非常复杂——需要考虑高速缓存标记、N-Way级联和普通高速缓存控制等问题——仅关注程序指令存储器可让这项工作变得非常简单。这是因为对此特定的 32 位内核来说,对程序存储器的访问是一个严格的只读操作。在这种情况下,我们只需考虑一个方向的数据流可以减少缓冲器和高速缓存系统的复杂性。
预取缓冲器
增加闪存接口总体带宽的一个简单方法是扩展处理器和闪存器件间的通道宽度。假定闪存的速度一定,增加带宽的另外一个方法是扩展接口宽度,以实现一次提取更多指令,创造一个更为快速的闪存接口外观。
这是预取缓冲器的一个基本前提。它利用了连接闪存的更宽接口的优势,可在同样的时钟周期数内读取更大的数据量,这通常只要花闪存读一个字的时间。
因此,预取缓冲器还定义了新数据通道的最小尺寸,原因显而易见。
图2.1显示了我们的120 MHz内核连接到20 MHz闪存阵列的情况。采用两个系统间的速度比作为起始值,我们可以确定预取缓冲器、闪存接口读取的宽度,假设我们需要在无需等待状态的情况下读取指令。
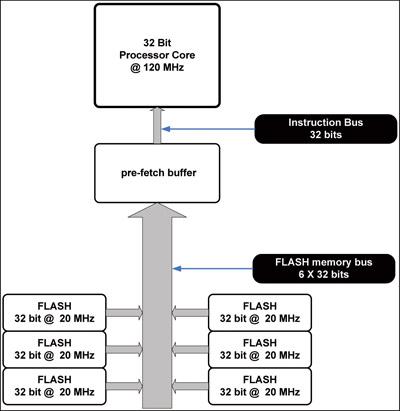
图2.1 指令预取
在这种情况下,预取/闪存数据通道将是:
(120/20)X32位=192位宽
预取缓冲器控制逻辑不断对存取缓冲器的读取数进行标记。最后一次存取后,它将使下一个周期从闪存重新加载整个缓冲器。
预取缓冲器控制逻辑还可识别缓冲器每次进入的有效地址。它还将提供适当的解码,根据正确的顺序指令显示处理器数据总线,当一个执行分支需要完整的新的顺序指令时,将重新加载缓冲器。
当然,在提取新的指令时,分支将造成一些额外的延迟。但是由于相比处理器内核,预取缓冲器实现六合一方法在数据通道宽度方面具有绝对的优势,为该分支问题的最终平衡的结果付出的代价是值得的。
更多经验法则分析都显示,一个典型的嵌入式应用有20%发生分支的机会,每五个周期相当于一个分支。采用之前的方法,CPI值现在为:
周期+1指令*6周期)/5指令
CPI = 2.0
我们已经看到利用基本实现方法,整个系统周期效率有了大幅提高。
图2.1还显示了一个更为现实解决方案方法,即将六个独立的闪存系统的32位总线加在一起,而不是重新设计一个新的、极宽的数据总线闪存系统。预取缓冲器控制逻辑将自动创建六个连续的程序地址,然后允许一个正常的读取周期同时访问所有六个组。在读取周期的末尾,预取缓冲器现在可保持六个新的指令,而非一个,模拟的零等待状态系统。
指令高速缓存
形式指令高速缓存赋予预取缓冲器更高水平的复杂性,因为高速缓存不需要包含整个高速缓存阵列的特定线性地址。形式高速缓存的尺寸也比简单预取缓冲器大,它可能在高速缓存内存储整个循环序列。
图 2.2 显示了一个简单的有 8 块、单路的高速缓存设计,1 块有 16 个字节。虽然这么小的高速缓存很难实现,但它对指令执行很有用。在这种情况下,地址标记将是整个地址的高 12 位,而索引将是寻址高速缓存块内的特定条目的余下的两位。
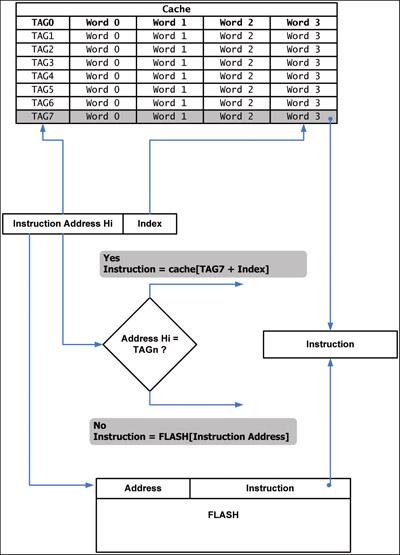
图2.2 指令侧高速缓存
与指令预取缓冲器相比,指令高速缓存系统具有更复杂的地址比较系统,因为该高速缓存阵列不仅包括每个高速缓存块的连续寻址指令,而且可以将指令地址空间的任何区域包含在高速缓存块内。
为了让高速缓存更有效地工作,在闪存器件和指令高速缓存之间应当实现尽量宽的数据通道,保证内核能够以最快的速度执行程序指令。指令高速缓存在与闪存器件的接口上实现了一个指令预取机制来解决这个问题。否则,闪存存取时间的问题就会影响内核执行速度。
在正常执行过程中,所需的指令地址高位和高速缓存阵列的指令标记间开始一连串的比较。如果找到匹配的地址,高速缓存命中即被寄存,指令地址的低位将被用于高速缓存块内的索引,以找回所需的指令。如果没有发现匹配的地址,就是我们所说的高速缓存不命中。高速缓存不命中将导致高速缓存控制器从存储区的特定区域读入包含所需指令的缓存块。被替代的高速缓存块通常是阵列中最旧的高速缓存块。
当使用高速缓存时,基本性能分析变得更加复杂,因为这时高速缓存不命中数在方程里引入了一个新的变量。分析典型应用代码可帮助芯片设计人员确定高速缓存大小和实际性能增益的最佳平衡。
对于我们的设计,假定 CPI 将在以下范围内是比较合理的:
<= CPI (cache) <= 2.0
在高速缓存大得足够存储大多数应用主程序的情况下,性能增益可能非常显著,因为系统正在接近 0 等待状态执行环境。
采用改良的哈佛架构(Modified Harvard Architecture)设计的指令高速缓存的一个重要优势是高速缓存无需执行回写操作。与数据高速缓存相比,这种实现要简单的多,数据缓存还要保证改动过的高速缓存数据正确地存储进主数据存储器。
来自高性能计算环境的一个通用概念是高速缓存,在主要存储器件和处理器内核之间采用更小及更快的内存存储,可以实现突发数据或程序指令的更快访问。
设计和实现高速缓存可能非常复杂——需要考虑高速缓存标记、N-Way级联和普通高速缓存控制等问题——仅关注程序指令存储器可让这项工作变得非常简单。这是因为对此特定的 32 位内核来说,对程序存储器的访问是一个严格的只读操作。在这种情况下,我们只需考虑一个方向的数据流可以减少缓冲器和高速缓存系统的复杂性。
预取缓冲器
增加闪存接口总体带宽的一个简单方法是扩展处理器和闪存器件间的通道宽度。假定闪存的速度一定,增加带宽的另外一个方法是扩展接口宽度,以实现一次提取更多指令,创造一个更为快速的闪存接口外观。
这是预取缓冲器的一个基本前提。它利用了连接闪存的更宽接口的优势,可在同样的时钟周期数内读取更大的数据量,这通常只要花闪存读一个字的时间。
因此,预取缓冲器还定义了新数据通道的最小尺寸,原因显而易见。
图2.1显示了我们的120 MHz内核连接到20 MHz闪存阵列的情况。采用两个系统间的速度比作为起始值,我们可以确定预取缓冲器、闪存接口读取的宽度,假设我们需要在无需等待状态的情况下读取指令。
图2.1 指令预取
在这种情况下,预取/闪存数据通道将是:
(120/20)X32位=192位宽
预取缓冲器控制逻辑不断对存取缓冲器的读取数进行标记。最后一次存取后,它将使下一个周期从闪存重新加载整个缓冲器。
预取缓冲器控制逻辑还可识别缓冲器每次进入的有效地址。它还将提供适当的解码,根据正确的顺序指令显示处理器数据总线,当一个执行分支需要完整的新的顺序指令时,将重新加载缓冲器。
当然,在提取新的指令时,分支将造成一些额外的延迟。但是由于相比处理器内核,预取缓冲器实现六合一方法在数据通道宽度方面具有绝对的优势,为该分支问题的最终平衡的结果付出的代价是值得的。
更多经验法则分析都显示,一个典型的嵌入式应用有20%发生分支的机会,每五个周期相当于一个分支。采用之前的方法,CPI值现在为:
周期+1指令*6周期)/5指令
CPI = 2.0
我们已经看到利用基本实现方法,整个系统周期效率有了大幅提高。
图2.1还显示了一个更为现实解决方案方法,即将六个独立的闪存系统的32位总线加在一起,而不是重新设计一个新的、极宽的数据总线闪存系统。预取缓冲器控制逻辑将自动创建六个连续的程序地址,然后允许一个正常的读取周期同时访问所有六个组。在读取周期的末尾,预取缓冲器现在可保持六个新的指令,而非一个,模拟的零等待状态系统。
指令高速缓存
形式指令高速缓存赋予预取缓冲器更高水平的复杂性,因为高速缓存不需要包含整个高速缓存阵列的特定线性地址。形式高速缓存的尺寸也比简单预取缓冲器大,它可能在高速缓存内存储整个循环序列。
图 2.2 显示了一个简单的有 8 块、单路的高速缓存设计,1 块有 16 个字节。虽然这么小的高速缓存很难实现,但它对指令执行很有用。在这种情况下,地址标记将是整个地址的高 12 位,而索引将是寻址高速缓存块内的特定条目的余下的两位。
图2.2 指令侧高速缓存
与指令预取缓冲器相比,指令高速缓存系统具有更复杂的地址比较系统,因为该高速缓存阵列不仅包括每个高速缓存块的连续寻址指令,而且可以将指令地址空间的任何区域包含在高速缓存块内。
为了让高速缓存更有效地工作,在闪存器件和指令高速缓存之间应当实现尽量宽的数据通道,保证内核能够以最快的速度执行程序指令。指令高速缓存在与闪存器件的接口上实现了一个指令预取机制来解决这个问题。否则,闪存存取时间的问题就会影响内核执行速度。
在正常执行过程中,所需的指令地址高位和高速缓存阵列的指令标记间开始一连串的比较。如果找到匹配的地址,高速缓存命中即被寄存,指令地址的低位将被用于高速缓存块内的索引,以找回所需的指令。如果没有发现匹配的地址,就是我们所说的高速缓存不命中。高速缓存不命中将导致高速缓存控制器从存储区的特定区域读入包含所需指令的缓存块。被替代的高速缓存块通常是阵列中最旧的高速缓存块。
当使用高速缓存时,基本性能分析变得更加复杂,因为这时高速缓存不命中数在方程里引入了一个新的变量。分析典型应用代码可帮助芯片设计人员确定高速缓存大小和实际性能增益的最佳平衡。
对于我们的设计,假定 CPI 将在以下范围内是比较合理的:
<= CPI (cache) <= 2.0
在高速缓存大得足够存储大多数应用主程序的情况下,性能增益可能非常显著,因为系统正在接近 0 等待状态执行环境。
采用改良的哈佛架构(Modified Harvard Architecture)设计的指令高速缓存的一个重要优势是高速缓存无需执行回写操作。与数据高速缓存相比,这种实现要简单的多,数据缓存还要保证改动过的高速缓存数据正确地存储进主数据存储器。
- 音响系统的USB接口开发分析及主流芯片比较 (02-01)
- 让DSP成为创新的不竭源泉(03-08)
- 基于双星定位的4G监控报警系统设计(06-29)
- 可重定目标的嵌入式集成开发平台设计(08-03)
- 基于U盘和单片机的FPGA配置(08-25)
- 基于FPGA的液晶显示控制器设计(02-17)