Freescale同步串行传输SPI优化设计
时间:09-21
来源:互联网
点击:
Freescale系列的MCU大部分都存在一个SPI模块,它是一个同步串行外围接口,允许MCU与各种外周设备以串行方式进行通信。
目前,Freescale系列的大多数单片机总线不能外部加以扩展,当片内I/O或者存储器不能满足需求时,可以使用SPI来扩展各种接口芯片。这是一种最方便的Free-scale系列单片机系统扩展方法。
SPI系统主机最高频率=主机总线频率/2,从机最高频率=从机总线频率,即硬件体系决定了SPI的最高工作频率。如何在硬件体系结构已定的情况下,使I/O或存储器数据传输效率最高,成为SPI使用的一个关键问题。
1 同步串行传输SPI结构及常规操作
图1为Freescale同步串行传输SPI的体系结构图。
对Freescale同步串行传输体系来说,一般有两种操作模式:
①利用中断通知已经传输结束,或者接收完成;
②采用轮询方式,读取相应寄存器位置,判断传输是否完成。
无论是哪种模式,其常规操作流程(无配置过程)均如图2所示。
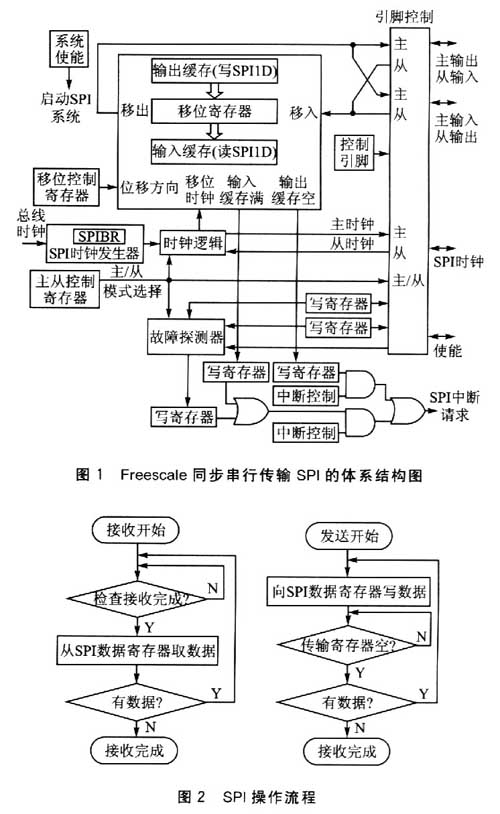
2 常规操作中的时间浪费
从图2中可以看出,当CPU向SPI数据寄存器中写入1字节数据后,必须等待,直至SPI模块通知传输结束,才能写入下一个字节。这是由于SPI数据模块由两部分构成:一部分是数据寄存器;另一部分是移位寄存器。当CPU向SPI数据寄存器写入1字节后,SPI模块需要将8位数据传入移位寄存器,在每个SPI时钟周期内传出1位数据。由于采样的原因,SPI的最大速率=BUS_CLK/2,所以当CPU向SPI写入一个8位数据后,必须等待8×2的时间单位,用于移位寄存器将数据串行输出。在该等待时间内,SPI模块处于工作状态,而CPU则处于等待状态。
3 SPI操作的一种优化设计
根据第2节的分析可以得出,常规SPI操作中的时间浪费在于——移位寄存器将数据串行传输时,CPU完全处于等待状态。如何利用这个等待时间,就是提高SPI系统效率的关键所在。下面是一段标准的SPI读数据操作(省略了清理寄存器操作):

为了更加清楚地了解程序的操作过程,对上面这段代码进行反汇编:

从上面这段程序可以很清楚地看到,程序将在①处等待,直至移位寄存器将数据传输完毕。等待时间为8个SPI时钟周期,如果采用最高速度1/2总线时钟,那么总共需要等待16个总线时钟。如果能将程序进行一定调整,将一些操作转移到需要等待的这个时间段内,那么可以避免全部或者部分的浪费。①处的操作需要5个总线周期,实际可以利用的时间为11个总线时钟。考虑到汇编中将数据传送到数据寄存器的操作,实际是由两部分构成:第一步,将数据读入A寄存器;第二步,将A寄存器中的值存入SPID数据寄存器中。在Freescale的单片机指令集中,将数据存入A寄存器消耗4个总线周期;INCX需要一个总线周期;判断数据是否为空的CPX指令需要3个时钟周期;决定是否退出循环Beq需要3个总线周期。将这4个操作转移到等待的时间内,那么等待数据从移位寄存器移出的时间被合理地利用,从而使得传输速度达到最高。
程序修改如下:
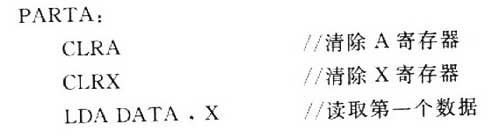

4 优化后的SPI操作与常规SPI操作比较
改进后的SPI操作与传统方式的SPI操作分别如图3和图4所示。

图3和图4是利用Agilent 54622D对主设备为MC9S08GB60,从设备为MCl3192的SPI传输采样。其中,MC9S08GB60总线速度为4 Mbps,SPI传输率为1 Mbps;图3中示波器每格是2μs,而图4中每格为5μs。一次SPI数据传输3字节,比较两图,可以很清楚地看到:采用传统方式的SPI操作,在每个字节数据之间的停留时间甚至超过自身传输时间;而改进后的SPI传输,每个字节之间几乎不存在等待时间。
结语
这种改进,从本质上来说,是根据SPI系统自身的特性,调整、优化软件操作结构,使系统在不改变硬件的条件下,提高工作效率。
目前,Freescale系列的大多数单片机总线不能外部加以扩展,当片内I/O或者存储器不能满足需求时,可以使用SPI来扩展各种接口芯片。这是一种最方便的Free-scale系列单片机系统扩展方法。
SPI系统主机最高频率=主机总线频率/2,从机最高频率=从机总线频率,即硬件体系决定了SPI的最高工作频率。如何在硬件体系结构已定的情况下,使I/O或存储器数据传输效率最高,成为SPI使用的一个关键问题。
1 同步串行传输SPI结构及常规操作
图1为Freescale同步串行传输SPI的体系结构图。
对Freescale同步串行传输体系来说,一般有两种操作模式:
①利用中断通知已经传输结束,或者接收完成;
②采用轮询方式,读取相应寄存器位置,判断传输是否完成。
无论是哪种模式,其常规操作流程(无配置过程)均如图2所示。
2 常规操作中的时间浪费
从图2中可以看出,当CPU向SPI数据寄存器中写入1字节数据后,必须等待,直至SPI模块通知传输结束,才能写入下一个字节。这是由于SPI数据模块由两部分构成:一部分是数据寄存器;另一部分是移位寄存器。当CPU向SPI数据寄存器写入1字节后,SPI模块需要将8位数据传入移位寄存器,在每个SPI时钟周期内传出1位数据。由于采样的原因,SPI的最大速率=BUS_CLK/2,所以当CPU向SPI写入一个8位数据后,必须等待8×2的时间单位,用于移位寄存器将数据串行输出。在该等待时间内,SPI模块处于工作状态,而CPU则处于等待状态。
3 SPI操作的一种优化设计
根据第2节的分析可以得出,常规SPI操作中的时间浪费在于——移位寄存器将数据串行传输时,CPU完全处于等待状态。如何利用这个等待时间,就是提高SPI系统效率的关键所在。下面是一段标准的SPI读数据操作(省略了清理寄存器操作):
为了更加清楚地了解程序的操作过程,对上面这段代码进行反汇编:
从上面这段程序可以很清楚地看到,程序将在①处等待,直至移位寄存器将数据传输完毕。等待时间为8个SPI时钟周期,如果采用最高速度1/2总线时钟,那么总共需要等待16个总线时钟。如果能将程序进行一定调整,将一些操作转移到需要等待的这个时间段内,那么可以避免全部或者部分的浪费。①处的操作需要5个总线周期,实际可以利用的时间为11个总线时钟。考虑到汇编中将数据传送到数据寄存器的操作,实际是由两部分构成:第一步,将数据读入A寄存器;第二步,将A寄存器中的值存入SPID数据寄存器中。在Freescale的单片机指令集中,将数据存入A寄存器消耗4个总线周期;INCX需要一个总线周期;判断数据是否为空的CPX指令需要3个时钟周期;决定是否退出循环Beq需要3个总线周期。将这4个操作转移到等待的时间内,那么等待数据从移位寄存器移出的时间被合理地利用,从而使得传输速度达到最高。
程序修改如下:
4 优化后的SPI操作与常规SPI操作比较
改进后的SPI操作与传统方式的SPI操作分别如图3和图4所示。
图3和图4是利用Agilent 54622D对主设备为MC9S08GB60,从设备为MCl3192的SPI传输采样。其中,MC9S08GB60总线速度为4 Mbps,SPI传输率为1 Mbps;图3中示波器每格是2μs,而图4中每格为5μs。一次SPI数据传输3字节,比较两图,可以很清楚地看到:采用传统方式的SPI操作,在每个字节数据之间的停留时间甚至超过自身传输时间;而改进后的SPI传输,每个字节之间几乎不存在等待时间。
结语
这种改进,从本质上来说,是根据SPI系统自身的特性,调整、优化软件操作结构,使系统在不改变硬件的条件下,提高工作效率。
Freescale MCU 单片机 总线 示波器 相关文章:
- TI在微控制器市场中奋战(05-29)
- 嵌入式系统降低功耗的方法研究(01-22)
- Linux下ColdFire 片内SRAM的应用程序优化设计(01-27)
- 由外部总线访问MPC5554的内部存储器(04-02)
- Freescale+HC08+MCU集成开发环境的设计(03-28)
- 嵌入式处理器MPC8272与外设的总线适配(04-12)