在TM1300上实现H.26L的4×4点整数变换
时间:03-09
来源:互联网
点击:
引言
H.26L是下一代视频编码标准。最初,H.26L由ITU-T的VCEG小组开始着手制订。2001年11月,MPEG和VCEG联合成立 JVT小组共同参与制订H.26L。也正因为MPEG的加入,H.26L将被纳入MPEG-4的第十部分。由于H.26L标准还在制订过程中,本文暂时以 JVT提供的测试模型TML8为参考。
H.26L信源编码的基本编码框架类似于当前流行的视频编码标准,采用结合变换编码和预测编码的混合编码技术。它出色的性能主要来源于引入的新编码特性:4×4点整数变换、使用UVLC进行熵编码、1/4~1/8像素精度的运行矢量、有多种块大小进行运动估计等等。这些新的编码技术从不同侧面提高了压缩性能和容错性能。尤其是4×4点整数变换,是所有视频压缩协议中独一无二的。
虽然H.26L标准还在制订中,但是在初步的测试中,它的编码性能超越了现存所有标准,包括H.263+和MPEG-4(Simple profile)。这些试验结果表明,在取得相同的客观视频质量下,H.26L比H.263+能够节省20%~50%的码率,比MPEG-4(SP)节省多达50%的码率。作为下一代视频编码标准,H.26L展示了其巨大的发展前景。
1 H.26L的4×4点整数变换
1.1 变换简介
在H.26L编码技术中,4×4点整数变换可以看作是DCT变换的整数版本,主要完成去除图像的空间相关性,与4×4点DCT变换有着相同的性质。先考虑一维的整数变换:设a,b,c,d是4个待变换的点,A,B,C,D是对应的4个变换系数,则可以用以下公式表示a,b,c,d点的正变换:
A=13a+13b+13c+13d
B=17a+7b-7c-17d
C=13a-13b-13c+13d
D=7a-17b+17c-7d
反变换公式如下:
a‘=13A+17B+13C+7D
b‘=13A+7B-13C-17D
c‘=13A-7B-13C+17D
d‘=13A-17B+13C-7D
其中a和a‘的关系是a‘=676a。也就是说,经过反变换后,还需要进行归一化操作,使得正变换和变换尺度一致。
同样二维的4×4整数变换的变换核是可分离的。分离的变换将计算复杂度从O(N4)降到O(N3)。
1.2 与8×8点DCT变换的比较
与传统的DCT变换相比,H.26L采用4×4点整数变换为视频编码带来了以下优点:
①有助于减少块斑和环形斑,提高了图像质量。由于对变换系数进行了量化,造成了高频系数丢失,所以恢复的图像中会有块班和环形班。在H.26L中,采用了更小的4×4点变换,可以有效抑制块斑和环形斑。
②整数变换减小了积累误差。传统的积累误差来自两个方面:正变换和反变换不匹配造成的误与量化造成的误差。为了达到压缩的目的,第二种误差不可避免。但是,由于H.26L采用了精确的整数变换,所以正变换和反变换不会产生误差,这样有效地减少了积累误差。
③运算速度快。因为H.26L采用的变换公式是一个简单的整数方程,也就是说计算都是基于整数的,而不是浮点数,所以它减少了单个变换的计算量,也有利于采用定点的DSP实现。
2 在TM1300中的实现
TM1300是一款32位超高性能的多媒体处理器。它的核心处理器采用的是VLIW超长指令字结构,可以在每一个时钟周期内同时进行5个操作;支持高度并行的定制操作,能大大加快数字信号处理和多媒体应用中常见的特殊运行的性能,而定制操作在使用上类似于C语言函数调用,方便了程序的设计。
本文针对4×4点整数变换的特点和TM1300的定制运算指令的特点,对整数变换作了以下调整:先做行变换,再做列变换。由于行变换的结果不会超过16位的表示范围,故在作列变换之前,重新合并数据,再作列变换,这样作是基于以下两点考虑。
第一,由于视频输入数据为无符号的字节型,而TM1300是32位的处理器,以字为单位访问内存,能提高访问的效率。当前4×4数据块(指针为P1)和参考帧4×4数据块(指针为P2)的数据组织如下。待变换的点为当前数据块的值与参考帧数据块对应的值之差。
P1:cal,cb1,cc1,cd1 P2:ra1,rb1,rc1,rd1
ca2,cb2,cc2,cd2 ra2,rb2,rc2,rd2
ca3,cb3,cc3,cd3 ra3,rb3,rc3,rd3
ca4,cb4,cc4,cd4 ra4,rb4,rc4,rd4
第二,可以利用8位乘/累加的定制操作,一个操作能完成4个8位乘/累加,一个机器周期(CLK)最多能执行5个操作。与非定制的乘/累加相比,减少了运算的次数,提高了程序运行的并行度。
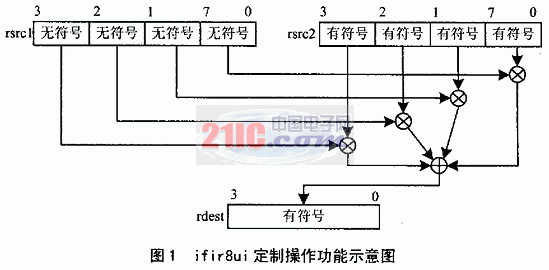
图1为ifir8ui定制操作功能示意图
3 实验结果
本文提出的基于TM1300的4×4整数变换的快速算法,使用了并行算是技术大大减少了计算量。实验表明,进行1个4×4点整数变换,直接用乘法和加法运算需要80个机器周期,改进后的算法只需28个机器周期;而利用TM1300进行1个8×8点定点DCT变换需要180个机器周期,也明显大于 4个4×4点整数变换时间。在变换方面H.264的变换编码运算复杂度小于其它编码方法。
H.26L是下一代视频编码标准。最初,H.26L由ITU-T的VCEG小组开始着手制订。2001年11月,MPEG和VCEG联合成立 JVT小组共同参与制订H.26L。也正因为MPEG的加入,H.26L将被纳入MPEG-4的第十部分。由于H.26L标准还在制订过程中,本文暂时以 JVT提供的测试模型TML8为参考。
H.26L信源编码的基本编码框架类似于当前流行的视频编码标准,采用结合变换编码和预测编码的混合编码技术。它出色的性能主要来源于引入的新编码特性:4×4点整数变换、使用UVLC进行熵编码、1/4~1/8像素精度的运行矢量、有多种块大小进行运动估计等等。这些新的编码技术从不同侧面提高了压缩性能和容错性能。尤其是4×4点整数变换,是所有视频压缩协议中独一无二的。
虽然H.26L标准还在制订中,但是在初步的测试中,它的编码性能超越了现存所有标准,包括H.263+和MPEG-4(Simple profile)。这些试验结果表明,在取得相同的客观视频质量下,H.26L比H.263+能够节省20%~50%的码率,比MPEG-4(SP)节省多达50%的码率。作为下一代视频编码标准,H.26L展示了其巨大的发展前景。
1 H.26L的4×4点整数变换
1.1 变换简介
在H.26L编码技术中,4×4点整数变换可以看作是DCT变换的整数版本,主要完成去除图像的空间相关性,与4×4点DCT变换有着相同的性质。先考虑一维的整数变换:设a,b,c,d是4个待变换的点,A,B,C,D是对应的4个变换系数,则可以用以下公式表示a,b,c,d点的正变换:
A=13a+13b+13c+13d
B=17a+7b-7c-17d
C=13a-13b-13c+13d
D=7a-17b+17c-7d
反变换公式如下:
a‘=13A+17B+13C+7D
b‘=13A+7B-13C-17D
c‘=13A-7B-13C+17D
d‘=13A-17B+13C-7D
其中a和a‘的关系是a‘=676a。也就是说,经过反变换后,还需要进行归一化操作,使得正变换和变换尺度一致。
同样二维的4×4整数变换的变换核是可分离的。分离的变换将计算复杂度从O(N4)降到O(N3)。
1.2 与8×8点DCT变换的比较
与传统的DCT变换相比,H.26L采用4×4点整数变换为视频编码带来了以下优点:
①有助于减少块斑和环形斑,提高了图像质量。由于对变换系数进行了量化,造成了高频系数丢失,所以恢复的图像中会有块班和环形班。在H.26L中,采用了更小的4×4点变换,可以有效抑制块斑和环形斑。
②整数变换减小了积累误差。传统的积累误差来自两个方面:正变换和反变换不匹配造成的误与量化造成的误差。为了达到压缩的目的,第二种误差不可避免。但是,由于H.26L采用了精确的整数变换,所以正变换和反变换不会产生误差,这样有效地减少了积累误差。
③运算速度快。因为H.26L采用的变换公式是一个简单的整数方程,也就是说计算都是基于整数的,而不是浮点数,所以它减少了单个变换的计算量,也有利于采用定点的DSP实现。
2 在TM1300中的实现
TM1300是一款32位超高性能的多媒体处理器。它的核心处理器采用的是VLIW超长指令字结构,可以在每一个时钟周期内同时进行5个操作;支持高度并行的定制操作,能大大加快数字信号处理和多媒体应用中常见的特殊运行的性能,而定制操作在使用上类似于C语言函数调用,方便了程序的设计。
本文针对4×4点整数变换的特点和TM1300的定制运算指令的特点,对整数变换作了以下调整:先做行变换,再做列变换。由于行变换的结果不会超过16位的表示范围,故在作列变换之前,重新合并数据,再作列变换,这样作是基于以下两点考虑。
第一,由于视频输入数据为无符号的字节型,而TM1300是32位的处理器,以字为单位访问内存,能提高访问的效率。当前4×4数据块(指针为P1)和参考帧4×4数据块(指针为P2)的数据组织如下。待变换的点为当前数据块的值与参考帧数据块对应的值之差。
P1:cal,cb1,cc1,cd1 P2:ra1,rb1,rc1,rd1
ca2,cb2,cc2,cd2 ra2,rb2,rc2,rd2
ca3,cb3,cc3,cd3 ra3,rb3,rc3,rd3
ca4,cb4,cc4,cd4 ra4,rb4,rc4,rd4
第二,可以利用8位乘/累加的定制操作,一个操作能完成4个8位乘/累加,一个机器周期(CLK)最多能执行5个操作。与非定制的乘/累加相比,减少了运算的次数,提高了程序运行的并行度。
图1为ifir8ui定制操作功能示意图
3 实验结果
本文提出的基于TM1300的4×4整数变换的快速算法,使用了并行算是技术大大减少了计算量。实验表明,进行1个4×4点整数变换,直接用乘法和加法运算需要80个机器周期,改进后的算法只需28个机器周期;而利用TM1300进行1个8×8点定点DCT变换需要180个机器周期,也明显大于 4个4×4点整数变换时间。在变换方面H.264的变换编码运算复杂度小于其它编码方法。
- F1aSh存储器在TMS320C3X系统中的应用(11-11)
- 基于PIC18F系列单片机的嵌入式系统设计(11-19)
- DSP在卫星测控多波束系统中的应用(01-25)
- 基于PCI总线的双DSP系统及WDM驱动程序设计(01-26)
- 利用Virtex-5 FPGA实现更高性能的方法(03-08)
- DSP与单片机通信的多种方案设计(03-08)