基于ADSP-BF533处理器的H.264解码器
时间:09-15
来源:互联网
点击:
3.3 程序移植
VisualDSP++是一款支持Blackfin处理器的集成开发、调试环境,包括VisuaIDSP++内核(VDK)、C/C++编译器、高级图形绘制工具、调试工具、器件模拟器等多种功能;能够很好地支持在Blackfin处理器上用C/C++语言进行开发工作。
移植的第一步是除去所有的编译环境不支持的函数(例如某些时间相关的函数),将文件操作修改为读取文件数据缓存的操作,删除SNR信息收集和信息打印输出等DSP平台实现不需要的代码。第二步是添加与硬件相关的代码。这些代码包括系统初始化代码、输出模块代码、中断服务程序和解码速率控制程序等程序代码。
移植完毕后,就实现了基于ADSP-BF533处理器的H_264解码器;但速度达不到实时解码的要求,还需要进行优化。
3.4 基于DSP平台的优化
基于DSP平台的优化分为系统级优化、C程序级优化和汇编级优化。
(1)系统级优化
打开编译器中的优化开关,设置为速度最优化;打开自动内联开关;打开“Interprocedural optimization”(过程间优化)开关;使用VisualDSP++编译器的PGO(Profile—Guided Optimization)优化编译技术。
(2)C程序级优化
C程序级的优化主要是针对BIackfin处理器的具体特点进行优化:
①编写链接描述文件,将经常用的数据存储在片内存储器,例如CAVLC熵解码的码表;启用指令Cache和数据Cache,设置好启用Cache机制的指令地址和数据地址。
②将除法操作转换为乘法操作或者采用查表法计算。
③减少对片外存储器的访问次数。对于经常访问的片外存储器区域,设置Cache使能,并可设置Cache锁定,防止被缓存的数据被替换,减少Cache未命中的几率。
④对于能够用较短的数据类型表达的数据改用较短的数据类型表达,例如原定义为int类型的4×4逆整数变换的输人数据,实际上可以定义为short类型。
(3)汇编级优化
汇编级优化通常遵循以下原则:
① 使用寄存器代替局部变量。如果局部变量用来保存计算的中间结果,那么用寄存器
代替局部变量可以省掉很多访问内存的时问。
② 使用硬件循环代替软件循环。.Blackfin处理器有专用的硬件支持两级嵌套的零开销
硬件循环。用硬件循环代替软件循环可避免堵塞流水线,提高速度。
③ 使用并行指令和向量指令。使用并行指令和向量指令,可以充分利用Blackfin处理器的SIMD系统结构的优点和内部硬件资源的并行处理优点,减少指令执行次数和提高指令执行效率。使用1条并行指令同时执行2条或3条非并行指令。向量指令可以同时对多个数据流进行相同的加工操作。
④ 使用视频处理指令。视频处理应用可以使用Blackfin处理器专用的视频处理指令,提高执行效率。
将最耗时的一些函数用汇编语言改写,充分利用Blackfin处理器的S1MD结构的优点和硬件上的并行性,在一个指令周期内执行多个操作,减少函数执行需要的指令周期。最耗时的函数有宏块解码函数decode_one_macroblock、逆整数变换函数itrans、去块效应滤波函数EdgeLoop、滤波门限计算函数Get_Strength等函数。
下面以4×4矩阵逆整数变换函数itrans和1/4像素插值滤波get_block(),说明用汇编指令优化带来的性能提高。4×4矩阵的逆整数变换函数itrans采用的是2级蝶形运算,先对4×4矩阵的每一行分别做行逆变换,再对每一列做列逆变换。一维变换采用如图2所示的蝶形算法。
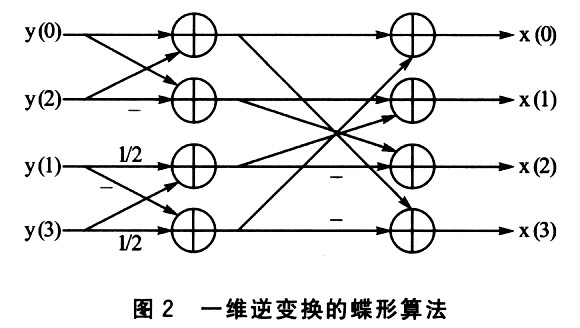
Blackfin处理器的SIMD结构支持向量操作,最多可以在1个周期内完成4个16位的加法操作。它的并行指令能同时进行算术运算和两个数据的装载/存储操作。例如上述的蝶形运算可以用如下指令实现(设寄存器IO中保存了输人数据y的地址,I2中保存了系数数组cof={0x7fff,0x4000}的地址,Il中保存了临时变量tmp的地址,R2和R1保存的是中问结果):
R7=[IO++];
Al=R6.I*R7.1,AO=R6.1*R7.1(IS)┃│I R5=
[10++]┃┃[││++]=R2;
R4.h =(A1一一R5.1*R6.1),R4.1=(AO+=R5.1*R6.1)(IS)││W[I1++]=R1.h;
R7.1=R6.1*R5.h(IS)1 W[11++]=R1.1;
R5=R7>>>1(v);
A1=R6.1*R5.h,AO—R6.1*R5.1(IS);
R3.h一(A1+一R6.1*R7.1), R3.1一(AO =R6.1*R7.h)(IS);
R2=R4+l+R3,R1=R4一│ 一R3:
完成一次一维逆变换只需8条指令,算上函数调用的开销和其他一些辅助指令,完成一个4×4矩阵的逆整数变换时总共需要82条指令周期。表1是优化前、后的比较。

get_block函数对像素矩阵进行1/4像素插值操作。先用六阶滤波器进行1/2像素插值,然后用线性内插法进行l/4像素插值。
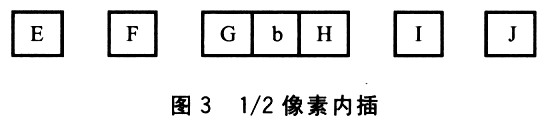
l/2像素b计算方法为:b=round((E一5F+20G+20H一5I+j)/32)。示意图如图3所示。E、F、G、H、I、J是整数像素,b是G和H之问的1/2像素。
像素的亮度值为unsigned char类型,先利用并行指令可以在1个指令周期内将8个像素的亮度值读到寄存器,然后利用视频专用指令将4个字节解包到1个寄存器对(R1:O或R3:2)中去,利用向量指令在1个周期内进行2次乘加操作。通过视频专用指令、向量指令和并行指令的使用,减少了函数指令的指令周期数。
VisualDSP++是一款支持Blackfin处理器的集成开发、调试环境,包括VisuaIDSP++内核(VDK)、C/C++编译器、高级图形绘制工具、调试工具、器件模拟器等多种功能;能够很好地支持在Blackfin处理器上用C/C++语言进行开发工作。
移植的第一步是除去所有的编译环境不支持的函数(例如某些时间相关的函数),将文件操作修改为读取文件数据缓存的操作,删除SNR信息收集和信息打印输出等DSP平台实现不需要的代码。第二步是添加与硬件相关的代码。这些代码包括系统初始化代码、输出模块代码、中断服务程序和解码速率控制程序等程序代码。
移植完毕后,就实现了基于ADSP-BF533处理器的H_264解码器;但速度达不到实时解码的要求,还需要进行优化。
3.4 基于DSP平台的优化
基于DSP平台的优化分为系统级优化、C程序级优化和汇编级优化。
(1)系统级优化
打开编译器中的优化开关,设置为速度最优化;打开自动内联开关;打开“Interprocedural optimization”(过程间优化)开关;使用VisualDSP++编译器的PGO(Profile—Guided Optimization)优化编译技术。
(2)C程序级优化
C程序级的优化主要是针对BIackfin处理器的具体特点进行优化:
①编写链接描述文件,将经常用的数据存储在片内存储器,例如CAVLC熵解码的码表;启用指令Cache和数据Cache,设置好启用Cache机制的指令地址和数据地址。
②将除法操作转换为乘法操作或者采用查表法计算。
③减少对片外存储器的访问次数。对于经常访问的片外存储器区域,设置Cache使能,并可设置Cache锁定,防止被缓存的数据被替换,减少Cache未命中的几率。
④对于能够用较短的数据类型表达的数据改用较短的数据类型表达,例如原定义为int类型的4×4逆整数变换的输人数据,实际上可以定义为short类型。
(3)汇编级优化
汇编级优化通常遵循以下原则:
① 使用寄存器代替局部变量。如果局部变量用来保存计算的中间结果,那么用寄存器
代替局部变量可以省掉很多访问内存的时问。
② 使用硬件循环代替软件循环。.Blackfin处理器有专用的硬件支持两级嵌套的零开销
硬件循环。用硬件循环代替软件循环可避免堵塞流水线,提高速度。
③ 使用并行指令和向量指令。使用并行指令和向量指令,可以充分利用Blackfin处理器的SIMD系统结构的优点和内部硬件资源的并行处理优点,减少指令执行次数和提高指令执行效率。使用1条并行指令同时执行2条或3条非并行指令。向量指令可以同时对多个数据流进行相同的加工操作。
④ 使用视频处理指令。视频处理应用可以使用Blackfin处理器专用的视频处理指令,提高执行效率。
将最耗时的一些函数用汇编语言改写,充分利用Blackfin处理器的S1MD结构的优点和硬件上的并行性,在一个指令周期内执行多个操作,减少函数执行需要的指令周期。最耗时的函数有宏块解码函数decode_one_macroblock、逆整数变换函数itrans、去块效应滤波函数EdgeLoop、滤波门限计算函数Get_Strength等函数。
下面以4×4矩阵逆整数变换函数itrans和1/4像素插值滤波get_block(),说明用汇编指令优化带来的性能提高。4×4矩阵的逆整数变换函数itrans采用的是2级蝶形运算,先对4×4矩阵的每一行分别做行逆变换,再对每一列做列逆变换。一维变换采用如图2所示的蝶形算法。
Blackfin处理器的SIMD结构支持向量操作,最多可以在1个周期内完成4个16位的加法操作。它的并行指令能同时进行算术运算和两个数据的装载/存储操作。例如上述的蝶形运算可以用如下指令实现(设寄存器IO中保存了输人数据y的地址,I2中保存了系数数组cof={0x7fff,0x4000}的地址,Il中保存了临时变量tmp的地址,R2和R1保存的是中问结果):
R7=[IO++];
Al=R6.I*R7.1,AO=R6.1*R7.1(IS)┃│I R5=
[10++]┃┃[││++]=R2;
R4.h =(A1一一R5.1*R6.1),R4.1=(AO+=R5.1*R6.1)(IS)││W[I1++]=R1.h;
R7.1=R6.1*R5.h(IS)1 W[11++]=R1.1;
R5=R7>>>1(v);
A1=R6.1*R5.h,AO—R6.1*R5.1(IS);
R3.h一(A1+一R6.1*R7.1), R3.1一(AO =R6.1*R7.h)(IS);
R2=R4+l+R3,R1=R4一│ 一R3:
完成一次一维逆变换只需8条指令,算上函数调用的开销和其他一些辅助指令,完成一个4×4矩阵的逆整数变换时总共需要82条指令周期。表1是优化前、后的比较。
get_block函数对像素矩阵进行1/4像素插值操作。先用六阶滤波器进行1/2像素插值,然后用线性内插法进行l/4像素插值。
l/2像素b计算方法为:b=round((E一5F+20G+20H一5I+j)/32)。示意图如图3所示。E、F、G、H、I、J是整数像素,b是G和H之问的1/2像素。
像素的亮度值为unsigned char类型,先利用并行指令可以在1个指令周期内将8个像素的亮度值读到寄存器,然后利用视频专用指令将4个字节解包到1个寄存器对(R1:O或R3:2)中去,利用向量指令在1个周期内进行2次乘加操作。通过视频专用指令、向量指令和并行指令的使用,减少了函数指令的指令周期数。
滤波器 ADI DSP 嵌入式 解码器 编码器 USB 电源管理 仿真 显示器 C语言 机顶盒 相关文章:
- 便携产品电源芯片的应用技术(02-15)
- 如何设计用于标清视频信道的有源滤波器(04-11)
- 头戴耳机的可调串音电路(03-24)
- 基于I2C总线控制的音频处理电路设计(10-17)
- 新型低电容EMI滤波器为手机带来更强抗干扰性能(01-22)
- 面向LCD的电磁干扰滤波器设计 (02-17)