H.264在ADSP-BF561上的实现与优化
时间:05-27
来源:互联网
点击:
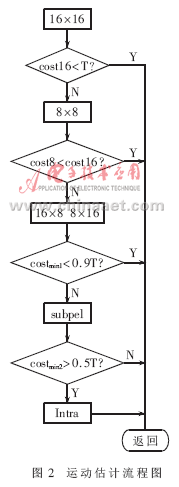
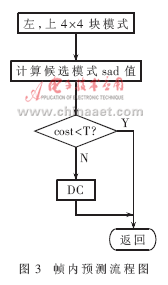
帧内预测的改进:H.264标准所采用的帧内预测模式除了DC模式都具有方向性,相邻4×4块都具有相关性。根据这样的相关性,只将当前4×4块上边和左边选用预测模式及其相邻的两种预测模式作为当前4×4块的预测模式,当其阀值都大于一个经验阀值时,才采用DC模式。这样的方案不用一一计算9种预测模式,在复杂度、编码效率、质量和速度上取了一个折中。流程如图3所示。
2.2.2.3 代码层次优化
针对ADSP-BF561平台,代码层次的优化工作包括以下几个方面:
(1)内联函数。将经常调用的函数体较小的函数改为内联。编译条件中有关于内联函数优化的选项。内联函数的使用是将代码的大小和运行效率取一个折中。根据实际情况,代码的大小并非限制条件,所以应尽可能多地使用内联函数。在项目配置中选中when declared inline选项。
(2)跳转预测。ADSP-BF561采用了静态预测的方式来预测有条件判断情况,预测不成功会造成4~8个内核时钟(CCLK)的延误。如果事先知道某些跳转的概率,将可能性最大的分支放在最前面,可以从概率上降低预测不成功而造成的stall。
(3)使用硬件支持循环。对于大部分平台,将一些循环体小的循环展开也能提高效率。ADSP-BF561有两组硬件计数器用以支持循环。所以除非是展开三层以上的循环,否则,展开循环体不能提高效率。
(4)内存。嵌入式系统的内存是非常宝贵的资源。避免频繁的动态申请和释放内存,能减少碎片产生,提高内存的利用率。X264工程也不会频繁地申请释放内存。在项目中,具体做法是编写平台相关的malloc和free函数。将经常使用的中间数据在L1数据空间中分配。
(5)注释不需要代码。去掉代码中不需要的部分,主要会去掉CAVLC以及部分码率控制、csp、cpu、信息统计、调试和psnr计算等部分代码,这样做的目的是为了减小文件大小和去除代码中的一些跳转。不建议删除代码,可以使用注释符或用宏切换的方式,以防止以后参数改变时需要使用未使用过的代码。
2.2.2.4 平台层次优化
ADSP-BF561相应的编程参考和硬件参考对其平台特性有详细介绍。一些平台自带的优化功能,如CACHE的开启和配置等不专门在此讨论。
(1)汇编代码编写
使用汇编优化有两个方法:对于LEAF函数(函数体中不再调用其余函数),采用整个函数完全用汇编指令重写的方式;而对于NONLEAF函数则可使用asm关键字,在C代码中嵌入汇编代码。在汇编代码的编写过程中一些情况会造成流水线stall,在编写汇编代码时要特别注意避免这些情况。IDE集成了PIPLELINEVIEWER工具,如图4所示。在编写完成汇编代码后,可使用该工具观察运行时流水线的情况。如果有stall等出现,会给出原因,优化人员根据工具分析结果重新更改代码,提高执行效率。

ADI公司提供的IDE具有非常灵活的设置,能根据用户的需要生成针对不同限制的代码。如内存有限,用户可以设置生成文件更小的代码;如果用户更注重运行速度,则设置编译器生成运行速度更快的代码,或是在其间取一个折中。
ADSP-BF561有专门用于处理视频相关的一些专用DSP指令(video pixel operations、vectoroperations等),这些专用指令通过SIMD技术或者操作专门硬件支持某些特殊运算(累加、多参数取均值,同时完成加减法等),以提高运行速度。如前文求SAD情况,汇编指令中有指令专门计算连续4个像素与另外连续4个像素之差的绝对值之和,结果与累加器的值相加。如果要隔点算(即取一半的点计算),反而需要增加指令后对数据进行下采样,既耗时而且不准确。所以采用计算一半像素点的策略并不适用于ADSP-BF561。编译器自动生成的代码中不会使用到这些专用指令。所以只能根据对算法的理解和对平台的熟悉程度来对算法进行汇编优化。
在编写汇编代码时还需注意部分寄存器的使用,如I0、I1,其值不仅用做地址索引,还会影响许多指令的计算结果。在使用这些寄存器时,一定要注意将其压栈或置为适当的值。此外,关于数据的载入,一般应遵循对齐原则,但在做运动估计计算匹配准则函数时,这样的要求往往达不到。故如能将两者分开来计算,将更能提高效率。
此外,应尽量合理地使用寄存器,多使用并行指令也能提高代码的执行效率。
(2)分级存储器结构
ADSP-BF561处理器采用改进的哈佛结构和分级的存储器结构。Level1(L1)存储器以全速运行,只有很少的延迟。在L1级,指令存储器存放指令。两个数据存储器存放数据,一个专用的临时数据存储器存放堆栈和局部变量信息。由多个L1 存储器组成的模块,可进行SRAM和CACHE的混合配置。存储器管理单元(MMU)提供存储器保护功能,对运行于内核上的独立任务,可保护系统寄存器免于意外的存取。L1存储器是ADSP-BF561处理器内核中性能最高、最重要的存储器。通过外部总线接口单元(EBIU),片外存储器可以由SDRAM、FLASH和SRAM 进行扩展,可以访问多达132MB的物理存储器。根据这样的特点,将执行率更高的代码放入L1指令缓存中,能使代码更快地运行。IDE提供了Profile工具,能在运行时统计各个函数所占的CYCLE数和占总CYCLE数的百分比。通过将X264中比较耗时的部分算法代码,如模式选择部分代码放入L1指令空间,能进一步提升运行效率。Profile工具统计结果同样也是选择需要使用汇编优化函数的依据,IDE可根据Profile结果对代码进行优化。X264代码Profile统计结果与测试数据有很大关系,选用更类似以后应用场所的数据作为测试数据,能使统计结果更接近以后的应用环境。为达到比较准确的统计结果,最好在Simulation阶段进行统计。虽然这样非常耗时,但为得到一个准确的统计作为参考依据是值得的。此外CACHEVIEWER工具能提供运行时CACHE的使用情况,使用它来分析CACHE的使用,对于提高代码运行效率很有用处。
DSP ADI 总线 嵌入式 编码器 滤波器 解码器 电源管理 USB 电子 相关文章:
- 全面解读 嵌入式DSP上的视频编解码(08-19)
- 基于ADSP-TS201S的图像采集处理系统(08-12)
- 基于Blackfin533的H.264编码(08-18)
- 图形液晶显示模块在嵌入式系统中的应用(09-02)
- 基于DSP和FPGA的电视观瞄系统设计(09-02)
- TI手提多媒体设备解决方案(09-23)