周立功来讲解哈希表的实现
9 memcpy(p_mem + sizeof(slist_node_t), key, p_hash -> 9 memcpy(p_mem + sizeof(slist_node_t), key, p_hash -> key_len); // 存储关键字
10 memcpy(p_mem + sizeof(slist_node_t) + p_hash->key_len, value, p_hash->value_len); // 存储记录
11 return slist_add_head(&p_hash -> p_head[idx], (slist_node_t *)p_mem); // 将结点加入链表
12 }程序分配了一个结点的空间,该结点的空间需要存储一个slist_node_t类型链表结点,便于添加结点到链表中,存储长度为p_hash->key_len的关键字,存储长度为p_hash->value_len的记录值,详见图3.26,其内存的大小为:
sizeof(slist_node_t) + p_hash -> key_len + p_hash -> value_len

图3.26 结点存储空间
由于结点空间的首部用于存储结点slist_node_t的值以组织链表。因此需要将结点添加到链表中时,直接将p_mem转换为slist_node_t*类型使用即可,通用链式哈希表的结构示意图详见图3.27。
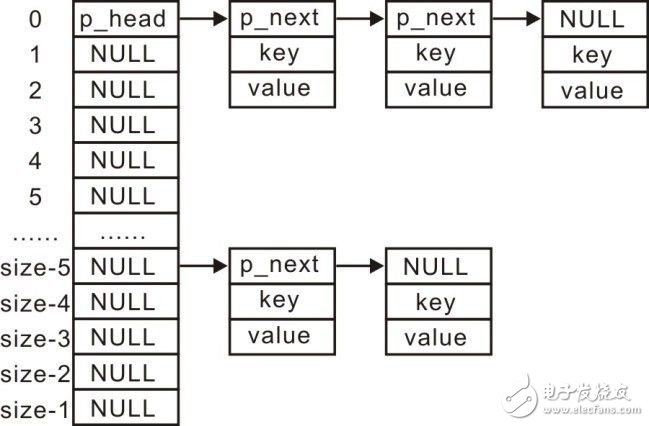
图3.27 通用的链式哈希表结构示意图
与图3.25中管理学生记录的链式哈希表结构示意图对比发现,它们表达的含义是完全一致的,仅仅是具体类型变为了更加通用的void *类型。
3. 查找记录
hash_db_search()接口通过关键字查找与之对应的记录,查找记录时,需要指定关键字信息,同时还需要使用一个指向记录的指针获取查找到的记录值,其函数原型(hash_db.h)如下:
int hash_db_search(hash_db_t *p_hash,const void *key, void *value);
虽然参数与添加记录是完全一样的,但value表示的含义却不一样,此处的value是输出参数,用于得到查找到的记录值。而添加记录函数中的value是输入参数,提供需要存储的记录值。由于此处的value指向指向的值是需要被改变的(改变为查找到的记录值),因此,其不能增加const修饰符。以查找ID为201444700239的学生记录为例,使用范例如下:
student_t stu;
unsigned char id[6] = {0x20, 0x14, 0x44, 0x70, 0x02, 0x39};
if (hash_db_search(&hash_students, id, &stu) == 0) {
// 查找到该学号的学生记录
} else {
// 查找失败,未找到该学号的学生记录
}在该函数的实现中,首先需要使用哈希函数找到关键字对应的记录在哈希表中的索引,以确定该条记录所在链表的表头,然后遍历链表的各个结点,将提供的关键字与结点中存储的关键字比对,直到找到关键字完全一致的记录(查找成功)或链表遍历结束(查找失败)。找到该记录对应的结点后,将结点中存储的value值拷贝到参数value指针指向的空间中即可。函数实现的范例详见程序清单3.65。
程序清单3.65 查找记录函数范例程序
1 // 寻找结点的上下文(仅内部使用)
2 struct _node_find_ctx {
3 void *key; // 查找关键字
4 unsigned int key_len; // 关键字长度
5 slist_node_t *p_result; // 用于存储查找到的结点
6 };
7
8 // 遍历链表的回调函数,查找指定结点
9 static int __hash_db_node_find (void *p_arg, slist_node_t *p_node)
10 {11 struct _node_find_ctx *p_info =
- 电源软启动的实用设计技巧(07-16)
- 周立功:动态分布内存——malloc()函数与calloc()函数(07-22)
- 周立功“程序设计与数据结构”:深度解剖动态分布内存的free()函数与realloc()函数(07-25)
- 周立功教你学程序设计技术:做好软件模块的分层设计,回调函数要这样写(07-30)
- 周立功教你学C语言编程:教你数组是如何保存指针的(07-31)
- 算法的泛化问题,这些坑你可能都经历过!|周立功教你学软件设计(08-01)