从硬件引申出内存屏障,带你深入了解Linux内核RCU
针对这种情况,硬件设计者对软件工程师还是给予了必要的同情。他们会对系统进行稍许的改进,如下图:
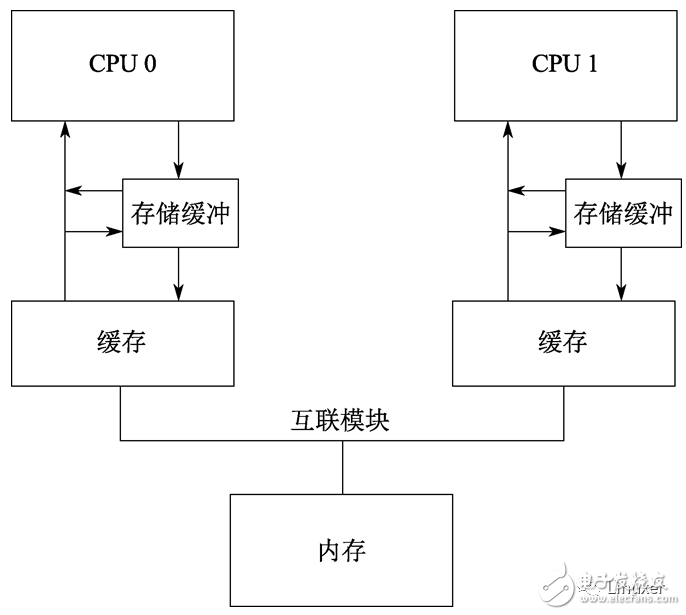
在调整后的架构中,每个CPU在执行加载操作时,将考虑(或者嗅探)它的Writebuffer。这样,在前面执行顺序的第8步,将在存储缓冲区中为"a"找到正确的值1 ,因此最终的"b"值将是2,这正是我们期望的。
Write buffer带来的第二个困扰,是违反了全局内存序。考虑如下的代码顺序,其中变量"a"、"b"的初始值是0。
1 void foo(void)
2 {
3 a = 1;
4 b = 1;
5 }
6
7 void bar(void)
8 {
9 while (b == 0) continue;
10 assert(a == 1);
11 }
假设CPU 0执行foo(),CPU1执行bar(),再进一步假设包含"a"的缓存行仅仅位于CPU1的缓存中,包含"b"的缓存行被CPU 0所拥有。那么操作顺序可能如下:
1.CPU 0 执行a = 1。缓存行不在CPU0的缓存中,因此CPU0将"a"的新值放到Write buffer,并发送一个"读使无效"消息。
2.CPU 1 执行while (b == 0) continue,但是包含"b"的缓存行不在它的缓存中,因此它发送一个"读"消息。
3.CPU 0 执行 b = 1,它已经拥有了该缓存行(换句话说,缓存行要么已经处于"modified",要么处于"exclusive"状态),因此它存储新的"b"值到它的缓存行中。
4.CPU 0 接收到"读"消息,并且发送缓存行中的最近更新的"b"的值到CPU1,同时将缓存行设置为"shared"状态。
5.CPU 1 接收到包含"b"值的缓存行,并将其值写到它的缓存行中。
6.CPU 1 现在结束执行while (b ==0) continue,因为它发现"b"的值是1,它开始处理下一条语句。
7.CPU 1 执行assert(a == 1),并且,由于CPU 1工作在旧的"a"的值,因此断言验证失败。
8.CPU 1 接收到"读使无效"消息,并且发送包含"a"的缓存行到CPU 0,同时在它的缓存中,将该缓存行变成无效。但是已经太迟了。
9.CPU 0 接收到包含"a"的缓存行,并且及时将存储缓冲区的数据保存到缓存行中,CPU1的断言失败受害于该缓存行。
请注意,"内存屏障"已经在这里隐隐约约露出了它锋利的爪子!!!!

三、使无效队列又是为了解决什么问题?

一波未平,另一波再起。
问题的复杂性还不仅仅在于Writebuffer,因为仅仅有Write buffer,硬件还会形成严重的性能瓶颈。
问题在于,每一个核的Writebuffer相对而言都比较小,这意味着执行一段较小的存储操作序列的CPU,很快就会填满它的Writebuffer。此时,CPU在能够继续执行前,必须等待Cache刷新操作完成,以清空它的Write buffer。
清空Cache是一个耗时的操作,因为必须要在所在CPU之间广播MESI消息(使无效消息),并等待对这些MESI消息的响应。为了加快MESI消息响应速度,CPU设计者增加了使无效队列。也就是说,CPU将接收到的使无效消息暂存起来,在发送使无效消息应答时,并不真正将Cache中的值无效。而是等待在合适的时候,延迟使无效操作。
下图是增加了使无效队列的系统结构:

将一个条目放进使无效队列,实际上是由CPU承诺:在发送任何与该缓存行相关的MESI协议消息前,处理该条目。在Cache竞争不太剧烈的情况下,CPU会很出色地完成此事。
使无效队列带来的问题是:在没有真正将Cache无效之前,就告诉其他CPU已经使无效了。这多少有一点欺骗的意思。然而现代CPU确实是这样设计的。
这个事实带来了额外的内存乱序的机会,看看如下示例:
假设"a"和"b"被初始化为0,"a"是只读的(MESI"shared"状态),"b"被CPU 0拥有(MESI"exclusive"或者"modified"状态)。然后假设CPU 0执行foo()而CPU1执行bar(),代码片段如下:
1 void foo(void)
2 {
3 a = 1;
4 smp_mb();
5 b = 1;
6 }
7
8 void bar(void)
9 {
10 while (b == 0) continue;
11 assert(a == 1);
12 }
操作顺序可能如下:
1.CPU 0执行a = 1。在CPU0中,相应的缓存行是只读的,因此CPU 0将"a"的新值放入存储缓冲区,并发送一个"使无效"消息,这是为了使CPU1的缓存中相应的缓存行失效。
2.CPU 1执行while (b == 0)continue,但是包含"b"的缓存行不在它的缓存中,因此它发送一个"读"消息。
3.CPU 1接收到CPU 0的"使无效"消息,将它排队,并立
- 工控机在IC卡加油工程中的应用(05-13)
- 联网汽车为什么选择Linux开源平台?(07-10)
- 多网络和Linux代理的Android无线远程控制系统(02-02)
- 基于嵌入式Linux的家居监控系统设计(02-22)
- 基于嵌入式Linux系统的导航软件设计思路(03-17)
- 新型嵌入式机器视觉系统的设计研究(04-21)