Hot Chips 2017——人工智能近期的发展及其对计算机系统设计的影响(附PPT资料下载)
需要的图之后,还需要打开一个会话(Session)来运行整个计算图。在会话中,我们可以将所有计算分配到可用的 CPU 和 GPU 资源中。
如下所示代码,我们声明两个常量 a 和 b,并且定义一个加法运算。但它并不会输出计算结果,因为我们只是定义了一张图,而没有运行它:
a=tf.constant([1,2],name="a")b=tf.constant([2,4],name="b")result = a+bprint(result)#输出:Tensor("add:0", shape=(2,), dtype=int32) 下面的代码才会输出计算结果,因为我们需要创建一个会话才能管理 TensorFlow 运行时的所有资源。但计算完毕后需要关闭会话来帮助系统回收资源,不然就会出现资源泄漏的问题。下面提供了使用会话的两种方式:
a=tf.constant([1,2,3,4])b=tf.constant([1,2,3,4])result=a+bsess=tf.Session()print(sess.run(result))sess.close#输出 [2 4 6 8]with tf.Session() as sess: a=tf.constant([1,2,3,4]) b=tf.constant([1,2,3,4]) result=a+b print(sess.run(result)) #输出 [2 4 6 8]
TensorFlow + XLA 编译器

XLA(Accelerated Linear Algebra)是一种特定领域的编译器,它极好地支持线性代数,所以能很大程度地优化 TensorFlow 的计算。使用 XLA 编译器,TensorFlow 的运算将在速度、内存使用和概率计算上得到大幅度提升。
-
XLA 编译器详细介绍: https://www.tensorflow.org/performance/xla/
-
XLA 编译器开源代码: https://github.com/tensorflow/tensorflow/tree/master/tensorflow/compiler

TensorFlow 的优势
高性能机器学习模型
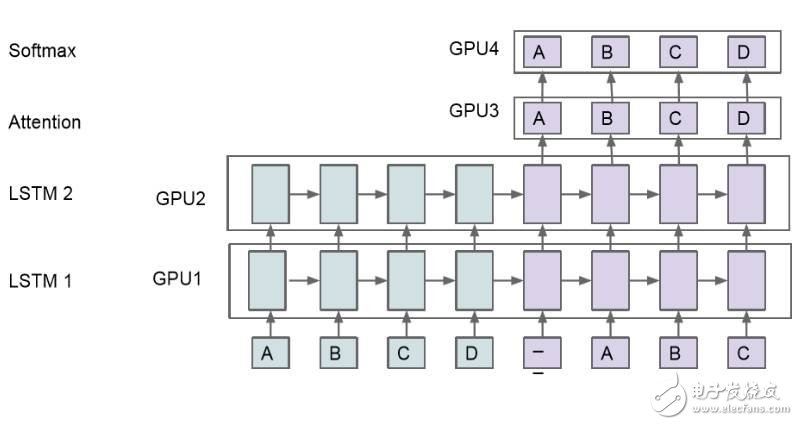
对于大型模型来说,模型并行化处理是极其重要的,因为单个模型的训练时间太长以至于我们很难对这些模型进行反复的修改。因此,在多个计算设备中处理模型并取得优秀的性能就十分重要了。如下所示,我们可以将模型分割为四部分,运行在四个 GPU 上。
高性能强化学习模型
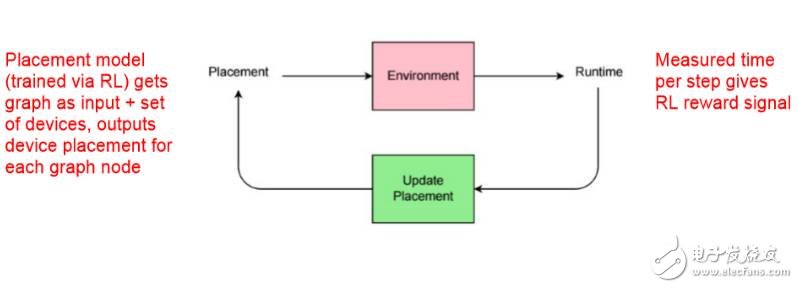
通过强化学习训练的 Placement 模型将图(graph)作为输入,并且将一组设备、输出设备作为图中的节点。在 Runtime 中,给定强化学习的奖励信号而度量每一步的时间,然后再更新 Placement。
通过强化学习优化设备部署(Device Placement Optimization with Reinforcement Learning,ICML 2017)
-
论文地址:https://arxiv.org/abs/1706.04972
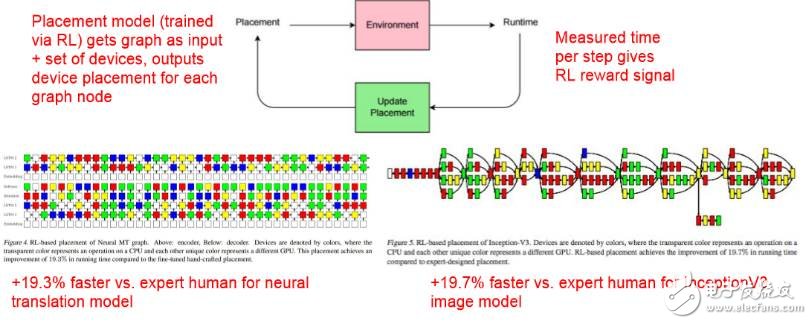
通过强化学习优化设备部署
降低推断成本
开发人员最怕的就是「我们有十分优秀的模型,但它却需要太多的计算资源而不能部署到边缘设备中!」
Geoffrey Hinton 和 Jeff Dean 等人曾发表过论文 Distilling the Knowledge in a Neural Network。在该篇论文中,他们详细探讨了将知识压缩到一个集成的单一模型中,因此能使用不同的压缩方法将复杂模型部署到低计算能力的设备中。他们表示这种方法显著地提升了商业声学模型部署的性能。
-
论文地址:https://arxiv.org/abs/1503.02531
这种集成方法实现成一个从输入到输出的映射函数。我们会忽略集成中的模型和参数化的方式而只关注于这个函数。以下是 Jeff Dean 介绍这种集成。

训练模型的几个趋势
1. 大型、稀疏激活式模型
之所以想要训练这种模型是想要面向大型数据集的大型模型容量,但同时也想要单个样本只激活大型模型的一小部分。
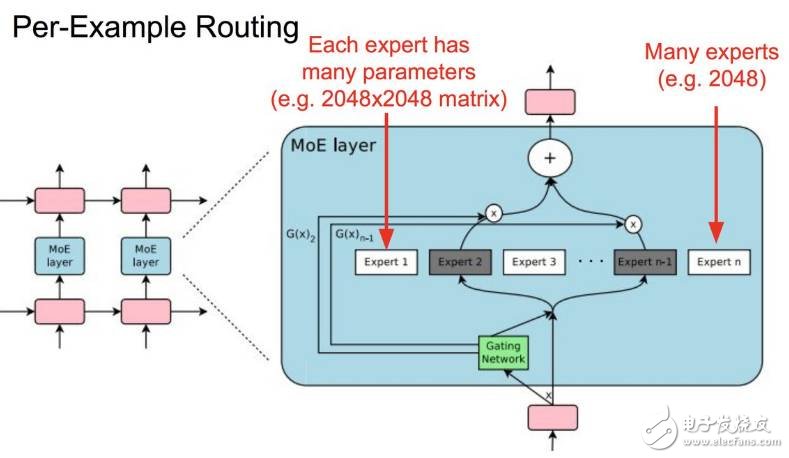
逐个样本路径选择图
这里,可参考谷歌 Google Brain ICLR 2017 论文《OUTRAGEOUSLY LARGE NEURAL NETWORKS: THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER》。
2. 自动机器学习
Jeff Dean 介绍说,目前的解决方式是:机器学习专家+数据+计算。这种解决方案人力的介入非常大。我们能不能把解决方案变成:数据+100 倍的计算。
有多个信号让我们看到,这种方式是可行的:
-
基于强化学习的架构搜索
-
学习如何优化
如 Google Brain ICLR 2017 论文《Neural Architecture Search with Reinforcement Learning》,其思路是通过强化学习训练的模型能够生成模型。
在此论文中,作者们生成了 10 个模型,对它们进行训练(数个小时),使用生成模型的损失函数作为强化学习的信号。

在 CIFAR-10 图像识别任务上,神经架构搜索的表现与其他顶级成果的表现对比如上图所示。
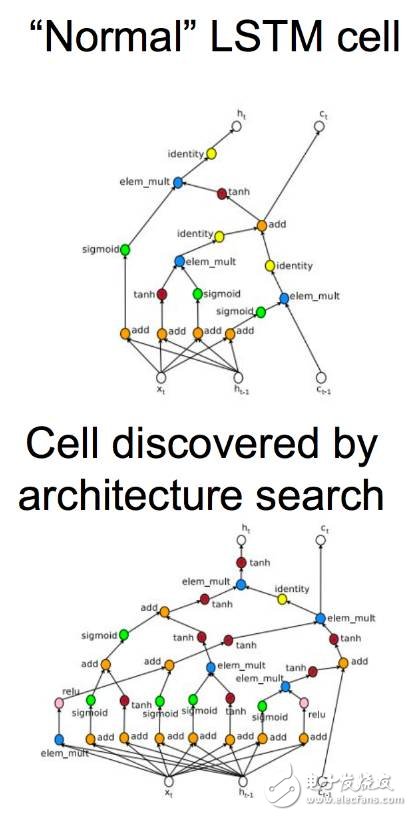
上图是正常的 LSTM 单元与架构搜索所发现的单元图。
此外,学习优化更新规则也是自动机器学习趋势中的一个信号。通常我们使用的都是手动设计的优化器,如下图所
- 大联大友尚集团推出基于Fairchild器件的LED照明电源解决方案(11-19)
- AI/机器学习/深度学习三者的区别是什么?(09-10)
- 阿里AI LABS与庆科信息联合推出儿童语音智能解决方案(04-05)
- 盘点人工智能技术的应用领域(05-01)
- foxmail如何设置有自定义背景的邮件模版(04-11)
- 电脑组建RAID 0的要诀(03-01)