视频监控系统及其在Blackfin上的应用及优势
,通过在目标跟踪器和目标分类器之间进行双向信息交互,来同时有效地提高目标的跟踪精度和分类性能。
在特定情况下需要对跟踪目标从类型细化到个体。这需要对目标的行为进行分析和理解。行为理解的关键问题是如何从学习样本中获取参考行为序列,并且学习和匹配的行为序列必须能够处理在相似的运动模式类别中空间和时间尺度上轻微的特征变化。
3. 智能视频监控系统实施的难点和Blackfin的优势
尽管已经取得了巨大进展,智能视频分析领域仍然没有公认的最优方法。其自身研究内容的复杂性,使得研究方法和工具多样,算法复杂度高,适用范围有限,没有鲁棒性、准确度、速度都符合需求的普遍方法。同时,视频监控系统的网络化和分布式处理的要求,以及大规模工程安装对成本、体积和功耗的限制,使得运算能力和带宽都在不断提高的嵌入式处理器成为视频监控系统的主流选择。而非标准化的智能视频分析,正是DSP的用武之地。
Blackfin处理器是ADI与INTEL联合研制的会聚式处理器,它的MSA(Micro Signal Architecture)架构兼具MCU的控制能力和DSP的高速运算能力。MCU和DSP融入同一个内核,只需要同一套开发工具和同一套指令集。与DSP加ARM的芯片架构相比,具有软硬件实现简单的优势。Blackfin支持ThreadX,Nucleus,uCOS-II,uCLinux等十多种嵌入式操作系统,为客户提供熟悉的软件架构基础。Blackfin为高强度,高数据率的数字和媒体处理做了专门优化,是理想的视频处理器,而且具有极高的性价比。它的低功耗特性非常适合外壳体积小的IP摄像头产品。
Blackfin的几十个DMA通道和可灵活配置的Cache很好地满足了视频监控系统对大运算量,高数据吞吐率的要求。十级流水线使得Blackfin有很强的指令并行执行能力。零开销循环控制指令让系统中的大量循环跳转不再消耗任何处理器的时钟周期。利用这些优势,real解码器的idct4×4算法在Blackfin上速度提高了7倍。
频数据有其自身的特性。在不同颜色空间,表示象素的每个分量通常都是8位宽度。Blackfin的4个视频算术运算单元和视频象素指令集大大加速了视频运算速度。一条视频象素操作指令可以在一周期之内完成4对视频数据分量的加法运算,减法运算,加减混合运算,取平均值,或者相减并求绝对值等11种视频象素运算。这些运算在编解码算法中的运动估计、loop filter和智能视频分析的各种算法中大量应用。在智能视频分析的一些基础算子中,例如直方图统计,中值运算,Sobel运算,形态学中的膨胀运算等都可以利用Blackfin的MIN, MAX指令来消除条件跳转,节省处理器周期。不仅如此,Blackfin还支持13种非视频数据的向量运算。适当设计数据结构,在前背景分离,阈值计算和更新等多个环节都可以运用Blackfin的特色指令让智能视频分析算法更迅捷。这些本身就很有效的指令中,大部分指令都能够并行执行,使得Blackfin的处理能力再加倍。
4.智能视频监控系统的实例
清华大学自动控制系在视觉分析领域有长期的研究和积累。结合ADI的优势,双方在Blackfin BF561双核处理器上实现了智能视频监控系统。ADI提供高质量高性能的H.264编码算法,清华大学自动控制系则在BF561上实现了自动跟踪算法。系统框图如图1所示。
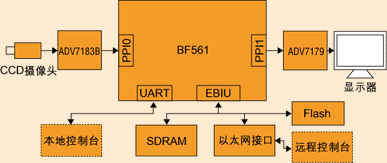
图1:基于BF561的智能监控终端框图
H.264编码算法模块是ADI为Blackfin客户提供的免费软件模块之一,目前已经有基于BF53x和BF561两个系列的芯片的实现。它支持完全动态的参数配置,用户可在系统运行时根据场景和网络带宽的变化改变编码的码率、帧率、关键帧间隔、量化值等等。从80KBb的CDMA网络到3Mb的DVR系统都能使用同一套函数库达到理想的编码质量。具有很强的适应性和灵活性。
清华大学自动控制系的智能跟踪算法采用单高斯背景建模的背景减除方法进行运动检测,在目标分类阶段,结合了基于运动特性的分类和基于形状信息的分类两种方法,利用人体、车辆的长宽比例、梯度直方图和运动周期性等对运动物体进行分类。在对同类目标跟踪时,采用基于区域的算法,判断连续的各帧之间运动物体的质心位移方向和距离。基于上述三个阶段的算法,系统还能实现人群跟踪,入侵检测,人、车数量统计,遗留物体检测,摄像头非法遮挡和移位报警等功能。
系统中,BF561的Core A用于实现H.264编码算法,Core B用于智能视频分析。Core A上同时运行uCos II操作系统以及RTP和TCP/IP协议栈。YUV4:2:2视频帧通过PPI(并行外设接口)以DMA的方式传送到SDRAM缓冲区。Core A和Core B共享帧缓冲区。Core B首先启动memory DMA把视频帧的Y(亮度)
视频 相关文章:
- 虚拟远端采样控制器惠及视频安保(10-26)
- 手机播放高清视频最优化设计应用(11-11)
- 浅析视频监控存储设备应用特点(06-02)
- 视频监控技术在安防中的应用发展(06-05)
- 视频监控的存储系统及RAID等级应用(07-23)
- 数字调音台在整合视频会议系统中的应用(11-25)