基于树形检测器的多标志识别

内层循环结束
p(Selectedidx)=1
将p和其局部最小fp值插入列表;
外层循环结束
输出列表中最小fp值对应的比特串。
有了生成的二叉树和soft cascade结构,本文基本上完成了多类台标的检测和识别。其中一个重要参数是soft cascade的长度,如果选择较短的cascade,检测器看上去更接近并行cascade结构的检测器;如果选择较长的cascade,分叉树可能要面对很难区分的负样本,从而降
低检测性能。本文中,尝试了很多种不同长度的soft cascade,然后挑选性能最好的一个。算法2如下:
算法2混合分叉树分类器
输入:训练好的soft cascade结构,查询树,N类正样本数据集S,还有一个数量很大的背景图像集B;
输出:一个混合分叉树分类器
(1)初始化:分叉树的根节点用soft cascade结构替代;
(2)树的节点训练:
a.从S集和B集中,挑选出所有可以通过分叉树当前节点E的父节点的样本,确保正负样本集p和n的规模相当;
b.如果背景图像集规模不够,终止该节点E的分叉,将E设为叶子节点;
(3)在查询树中搜索当前节点:
a.如果找到了,就根据查询节点集合将正样本集分成两部分,然后用Vector Boosting训练一个节点分类器。
b.否则,就用Gentle Adaboost训练一个强分类器。
(4)对于当前节点E的每个孩子节点,循环使用步骤(2)和(3)进行训练生成。
3 实验方案和结果
本文收集了6类台标集合,每一类包含了200张图像。而台标图像就是从这些图像中裁剪出来的,然后缩放成24×24像素大小的块,作为正样本集。负样本集则是从将台标区域掩盖掉后的图像上收集的。首先进行了一个实验,来解释WFS树的不同设计方案将会对算法性能带来怎样的影响,然后研究了soft cascade长度带来的影响,最后拿随机生成的树与本文的树进行对比。
本文首先使用了文献中提到的方法训练一个普通检测器,然后将其791个弱分类器组成了soft cascade。本文用这个soft cascade对一组测试图像进行了测试,统计结果表示每幅图像通过的平均特征数约为8。在实验中,作者发现这个长度值设置在平均特征数的1倍和2倍之间比较合适。
本文使用了上述正样本数据集和规模为1200的负样本数据集来构建查询树。最终生成的分叉树如图3所示。
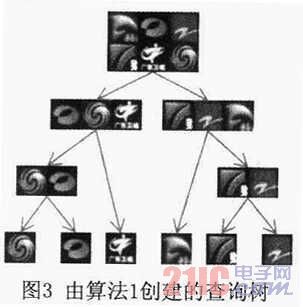
正如分叉树所示的,越相似的台标,它们在树里的位置越近。同时,本文也随机地生成了另一个查询树。使用这两棵树和同样的训练数据集,本文训练了两个WFS树检测器。
3.1 soft cascade的长度
当选择好查询树,本文就可以开始训练检测器了。作者尝试了不同的soft cascade的长度。本文调整叶子节点上分类器的阈值,确保两个检测器拥有相同的分类结果。
3.2 检测器的精确度
在本文的框架里,第一部分是整个结构的核心。在soft cascade中设置不同的alpha参数值,然后对将作为根节点分类器的soft casca-de尝试不同的长度。接着,调整每个叶子节点分类器上的阈值,可以得到如图4的ROC曲线。本文的soft cascade加WFS树结构的台标检测精确度要优于Huang的WFS树。与此同时,本文框架使用的特征数也比Huang的要少。 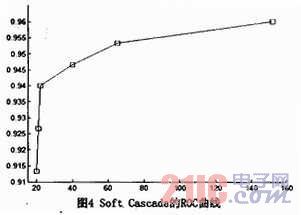

对于识别同一家电视台的不同频道,本文也采用了改进后的WFS结构。本文收集了9个不同的CCTV频道中央一至中央九,训练了一个CCTV系列检测器,它可以检测并识别出CCTV标志及其右侧区域里的数字符号。本文实验的结果数据如表1:
4 结语
本文实现了一个基于多层树形分类器结构的多台标识别方法,此方法具有对多类别标志识别的通用性。本文虽然在检测样本的平均特征数上有进一步减少,提高了算法的速度,并且在分叉树的叶子每个节点上增加了一个单类别cascade,降低了误检率。但是这种查询树结构在增加新类型台标时,需要重新生成和训练,花费大量时间。如果能找到一种增量学习算法,在增加新类别时,只需要对原有的查询树做局部修改,而不用全盘推翻重新计算,则该框架将更具实用性。