在嵌入式多核集群中利用OCP处理高速缓冲器一致流量
传统上,多处理器系统中的存储器一致性都是通过总线侦听实现的,每个内核都与一个通用多层总线连接,能够侦听同级处理器的存储器存取流量,以调节每个高速缓冲器行的一致状态。这样,每个内核都在本地保持了L1高速缓冲器行的一致状态,并通过通用总线将状态的改变通知同级处理器。
SoC不断增加的面积和复杂性导致了多层总线基本哲学的改变,以利于采用集中流量路由的本地点对点连接。由于负载的减少和段长的缩短,这将有助于显著加速和推动现在的本地化总线段的改善。同时,也可以缓解总线争用问题,同时增加了本地化数据交换吞吐量。为了满足这一系统架构趋势,出现了OCP(开放内核协议)标准,进一步巩固了这一设计哲学。另外,IP供应商业务模式的出现催化了IP互连和设计方法的标准化,有利于在一个开放标准基础上实现设计的复用。
然而,与通过OCP互连段操控一样,本地化总线执行将整个多核集群上的处理器分拆开。一致方案不能直接基于总线侦听和依赖总线仲裁来确保存取排序,需要不同的通信方法来确保数据存取的一致性。在争用L1行数据请求排序的过程中,其他挑战也浮现出来。应对这些挑战的一种方法是给每个处理单元增加一致消息通信,如图1所示。这些消息提供了侦听型缓冲器一致的方法。
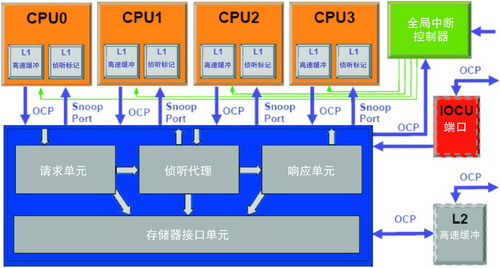
图 1 一致处理系统
一致消息包含了OCP协议中的一个新命令。处理器系统中的成员向一个集中一致管理器发送一致消息。该管理器提供存取排序(顺序化)和消息路由,为同级成员提供侦听型存取。这些同级成员将以其单独的L1行状态进行响应,并发出一个消息响应。根据这些响应,一致管理器发起对内核间一致数据的数据移动,将存取集中在更高级别的存储器层,如L2和L3高速缓冲器。I/O一致单元还可提供一种方式逐渐采用/逐渐淘汰数据进/出一致地址空间的数据,它是一致消息交换的一部分。
除了OCP协议中的新消息类命令外,还需要具体的处理器响应一致状态请求,因此它们不只是总线处理的发动者(主控)。一致处理系统满足这一要求的方法可能是通过提供一个OCP从端口来接收和响应一致管理器发送的消息。处理器的一致请求将利用OCP主端口。在处理集群内,内核间和一致管理器之间的一致消息交换被称为"干预"。处理器的OCP从端口接收干预,因此称为"干预端口"。
如图1所示,1004K系统的每个独立处理器都是基于我们多线程处理器架构的,可以在单标量、9级流水线范围内提供两个独立线程并处理上下文。复制的1级数据高速缓冲器标记阵列可同时用于存取CPU操作和干预查寻。一致处理系统可支持MESI型高速缓冲器行一致性。
处理系统一致管理器通过其请求单元-OCP从端口,在每个CPU和I/O一致单元的推动下,接收进入的消息并对其进行串化。串化的消息按照其地址空间和上下文,或使用"存储器接口单元"发送到更高级别的高速缓冲器层,或使用"侦听代理"发送至同级处理器和I/O一致单元。侦听代理发起OCP主处理(干预)来查寻每个处理器的一致L1高速缓冲器行状态。干预返回到消息发起者,称为自我干预,有助于发起者提供存取排序。对 CPU 发起的一致消息响应和数据响应是在"响应单元"内确立的,并发送到每个 CPU。
一致OCP命令
在1004K CPS中使用的OCP命令可以分成三类。
第一类是保持MESI型高速缓冲器行状态的一致消息。它们是CPU负载/存储操作的结果,能够发起CPU和/或存储器子系统之间的数据移动。CPS(一致处理系统)的所有同级CPU将接收由一个发起者发送的一致消息,并根据它们的高速缓冲器行一致状态做出响应。一致管理器将根据需要发起数据移动。
一致高速缓冲器操作指令用于一致地址空间内高速缓冲器行的维护。I/O流量将新的一致行带入该域,或将一致上下文从高速缓冲器行中移除。另外,还要进行存储器层的同步化操作。
第三类是非一致命令,在一致地址空间外的存储区中执行OCP主端口处理。它们代表了OCP读写命令。
一致消息
一致处理系统可能执行四个一致消息,这四个消息是由CPU负载/存储活动产生的L1高速缓冲器行状态变化导致的。发起的CPU将这个消息以OCP主端口命令发送。系统的同级CPU接收基于该行状态变化的干预,并以其本地高速缓冲器行状态进行响应。
第一种消息类型是CohReadOwn,表示在尝试修改高速缓冲器行时发生的高速缓冲器的不命中。同级内核遇到处于"修改"状态的该行时,会强制回写到存储器子系统中,并执行本地失效。作为优化,本地遇到的行数据将被转发到请求方 CPU,以降低存取延迟。请求方CPU将使该行作为"专有"行,并执行行修改指令。然后,高速缓冲器行状态将变成"修改过的"。在等待行重新填满的时候,请求方CPU将继续另一个线程的执行。
- 嵌入式智能设备的测试方法研究(11-29)
- 基于ARM的信号发生器人机交互系统设计(01-23)
- 采用C8051F020设计的嵌入式测试仪(01-17)
- 关于嵌入式智能设备的测试方法的研究(01-28)
- 基于μC/OS-II的电力参数监测仪设计(02-23)
- 基于嵌入式计算机PC/104的某火箭弹自动测试仪应用(03-15)