基于云计算的工厂信息监测系统设计
云计算(Cloud Computing)是一种基于网络的计算方式。通过这种方式,共享的软硬件资源和信息可以按需提供给计算机和其他设备。云计算是网格计算(Crid Computing)、分布式计算(Distributed Computing)、并行计算(Parallel Computing)、效用计算(UtilityComputing)网络存储(Network Storage Technologies)、虚拟化(Virtualization)、负载均衡(Load Balance)等传统计算机技术和网络技术发展融合的产物。它旨在通过网络把多个成本相对较低的计算实体整合成一个具有强大计算能力的系统,并借助基础设施即服务(IaaS),平台即服务PaaS)和软件即服务(SaaS)等先进的商业模式,把强大的计算能力分布到终端用户手中。文中将提出一种基于云计算,客户端基于Android平台的,通过无线局域网连接云端服务器的工厂信息监测系统。
1 研究背景
随着科技的进一步发展,现代化的管理开始应用于工厂的各个部门,工厂对设备信息的监测成为工厂管理的一个重要组成部分。工厂生产中设备的检测活动直接涉及产品的质量与工厂的运行安全,是工厂现代化管理的重要内容。目前,工厂的设备信息监测依然使用落后的纸质表格,纸质表格可扩展性差,不能进行实时监控,管理人员不能及时获得检测数据。同时纸张不具有重复使用性,而且在一些精密化高的工厂中需要使用价格高昂的特殊纸张,这样造成人力和物力资源的浪费。
文中将云计算概念引入工厂信息监测系统,可以实现在不改变现有设备的情况下,通过建立工厂内部的云计算平台,充分整合信息监测体系,提高工厂信息监测以及管理效率,构建一个低成本的工厂信息监测系统。运用云计算的方式实现资源的统一调度,使管理者可以从全局的高度掌握工厂的实时状况,保证生产高效、安全、有序地进行。
2 云计算概述
2.1 云计算体系结构
云计算平台是一个强大的"云"网络,连接了大量并发的网络计算和服务,并可利用虚拟化技术扩展每个服务器的能力,将各自的资源通过云计算平台结合起来,提供超级计算和存储能力。通用的云计算体系结构如图1所示。
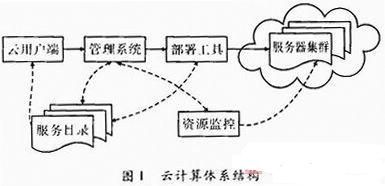
其中云计算体系结构中各部分的主要功能如下:
(1)云用户端。为云用户提供请求服务的交互界面,也是用户使用云的入口。用户通过Web浏览器可以注册、登录及定制服务、配置和管理用户。打开应用实例与本地操作桌面系统一样。
(2)服务目录。云用户在取得相应权限后可以选择或定制的服务列表,也可以对已有服务进行退订的操作,在云用户端界面生成相应的冈标或列表的形式展示相关的服务。
(3)管理系统和部署工具。提供管理和服务。能管理云用户,能对用户授权、认证、登录进行管理,并可以管理可用计算资源和服务,接收用户发送的请求,根据用户请求并转发到相应的程序,调度资源,智能地部署资源和应用,动态地部署、配置和回收资源。
(4)监控。监控和计量云系统资源的使用情况,以便做出迅速反应,完成节点同步配置、负载均衡配置和资源监控,确保资源能顺利分配给合适的用户。
(5)服务器集群。虚拟的或物理的服务器,由管理系统管理,负责高并发量的用户请求处理、大运算量计算处理、用户Web应用服务,云数据存储时采用相应数据切割算法,采用并行方式上传和下载大容量数据。
用户可通过云用户端从列表中选择所需的服务,其请求通过管理系统调度相应的资源,并通过部署工具分发请求、配置Web应用。
2.2 云计算的实现
2.2.1 MapReduce算法
MapReduce是一种由Google开发的基于Java、Python、C++的编程工具和编程模型,用于大规模数据集的并行运算,是云计算的核心技术。它是一种分布式运算技术,也是简化的分布式编程模式,适合用来处理大量数据的分布式运算,并用于解决问题的程序开发模型。
它的概念"Map(映射)"和"Reduce(化简)",和他们的主要思想,都是从函数式编程语言里借鉴来,具有从欠量编程语言里的特性。它方便了编程人员在不熟悉分布式并行编程的情况下,可将自己的程序运行在分布式系统上。当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce函数,用来保证所有映射的键值对中的每一个共享相同的键组。
2. 2.2 Hadoop架构
在Google发表MapReduce后,2004年开源社群用Java搭建出一套Hadoop框架,用于实现MapReduce算法。该框架能够把应用程序分割成许多很小的工作单元,每个单元可以在任何集群节点上执行或重复执行。此外,Hadoop还提供一个分布式文件系统GFS(Google File System),是一个可扩展、结构化、具备日志的分布式文件系统,支持大型、分布式大数据量的读写操作,其容错性较强。而分布式数据库(BigTable)是一个有序、稀疏、多维度的映射表,有良好的伸缩性和高可用性,用来将数据存储或部署到各个计算节点上。Hadoop框架具有高容错性及对数据读写的高吞吐率,能自动处理失败节点,图2所示为Google Hadoop架构。
- Facebook实验室曝光:测试APP有“妙招”(06-14)