基于TMS320C64x DSPs的MPEG-4实时编码器设计与实现
2 采用预测技术的运动估计算法
运动估计是MPEG-4编码中计算量最大的一部分,占据整个编码时间的50%以上。各种快速运动估计算法也成为近年来研究的热点。本文通过实验证明,采用预测技术的运动估计不但可以大大缩短计算时间,而且也有助于提高图像的质量。
宏块(Macro Block)的运动矢量(Motion Vector)在时间和空间都具有相关性,预测的原理就是利用当前帧和参考帧内相邻位置宏块的MV来预测当前宏块的MV。下面详述本文所采用的预测算法。
(1)确定当前宏块MV的7个候选值PreMV1~7。
如图3所示。PreMV1=(0,0);PreMV4取当前宏块左边相邻宏块的MV值;PreMV5取上边相邻宏块的MV值;PreMV6取右上方相邻宏块的MV值;PreMV2=mid{PreMV4, PreMV5, PreMV6},即取三者的中值;PreMV3取参考帧相同位置宏块的MV值;PreMV7取参考帧右下方相邻宏块的MV值。
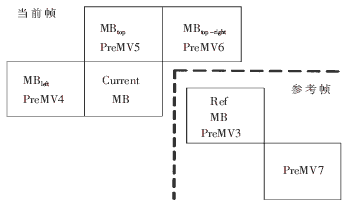
图3 预测运动矢量示意图
(2)确定筛选候选值的依据--SAD(绝对误差和)的门限值ThreshSAD。
SAD是确定最佳匹配块的准则。门限值ThreshSAD是指这样一个值:如果参考帧内某一宏块和当前宏块的SAD小于ThreshSAD,则当前宏块的MV值就可取作二者之间的位移。因此,ThreshSAD就可作为筛选7个候选值的依据。
由于SAD在空间上的相关性,ThreshSAD由相邻宏块的SAD值来确定:
ThreshSAD=Min{SADleft,SADtop,SADtop_left}
其中,SADleft、SADtop、SADtop-right分别为MBleft、MBtop、MBtop-right和其对应匹配块的SAD值,ThreshSAD取三者的最小值。
(3)从7个候选值中选出当前宏块的MV值。
按照PreMV1~7的顺序,依次计算当前宏块和7个匹配块的SAD值。如果有SAD值小于ThreshSAD,即停止计算,选用对应的PreMV作为当前宏块的MV值;如果7个SAD值均大于ThreshSAD,则采用运动搜索来确定当前宏块的MV值。该运动搜索并不以MV=(0,0)为中心,而是以对应SAD值最小的PreMV为中心,搜索采用简化的菱形算法。
对标准视频序列foreman.cif(352×288)进行编码(码率300kbps),测得表1所示数据。采用预测的运动估计算法利用视频序列在时间和空间上的相关性,无需对每个宏块都进行运动搜索,而且其搜索中心点也同样利用了相关信息,搜索算法也可进一步简化,因此大大减少了运动估计的计算量;同时,预测有助于提高图像质量,直接进行快速运动搜索通常会带来局部最小的问题,从而影响图像质量,而PreMV1~7取自位于当前宏块周围各个方向的宏块的MV值,避免陷入局部最小。
表1 预测技术对运动搜索性能的提高
| 采用预测 | 平均每个宏块所需的 SAD值计算次数 | 峰值信噪比PSNR(dB) | 平均帧率(fps) |
| 是 | 5 | 33.16 | 120 |
| 否 | 15 | 33.23 | 95 |
3 基于C64x CPU的软件优化技术
为了提高代码的执行效率,必须充分利用C64x CPU的VLIW和流水线结构对其进行优化,使程序无冲突地并行执行。MPEG-4编码程序中包含大量的循环体,例如计算SAD值、量化、DCT、半像素插值、运动补偿和构建重建帧等。这些循环体代码并不复杂,但执行次数频繁,占据了编码的绝大部分时间,因此循环体的优化是重点。本文所采取的代码优化分为C语言优化和编写线性汇编两个步骤,主要从消除数据相关性、数据打包和循环体的软件流水三个方面进行优化。
3.1 针对C语言的优化
C代码的优化主要依靠开发环境CCS的编译器完成,编程者需要合理选择编译选项,并利用特定的关键字和指令向编译器提供优化信息。例如关键字restrict用来消除数据间的相关性,编译器从而可以安排语句的并行执行;内联函数_nassert有助于数据的打包处理;宏指令#pragma MUST_ITERATE告诉编译器有关循环迭代次数的信息,编译器会根据这一信息进行软件流水。
3.2 用线性汇编改写关键代码
线性汇编是TMS320C6000特有的一种编程语言,介于高级语言和汇编语言之间。它可以指定指令用到的寄存器和功能单元,更易于对数据的打包处理。
线性汇编代码的并行处理和软件流水由汇编优化器完成,编程者需要熟悉C64x DSP的CPU结构和指令集,认真设计代码并充分利用编译器的反馈信息合理修改代码,才能写出高质量的线性汇编。本设计中程序主框架采用C语言编写,其它各关键部分的代码采用线性汇编实现。表2是代码优化前后的效率对比,表2中所列各代码段均针对8×8宏块进行处理。
表2 各关键代码优化前后消耗指令周期数对比
| 代码段 | 未优化 | C优化后 | 线性汇编优化后 |
MPEG-4 相关文章:
- 大规模IPTV点播系统解决方案(08-18)
- 数字音视频编解码技术标准AVS(08-19)
- 数字电视与数字电视编码技术的发展简介(08-19)
- IPTV编解码标准综述(08-26)
- IPTV洋标准暗藏高额专利费(08-29)
- 三重播放网络环境下验证IPTV服务质量(10-15)