数据仓库系统实现之挖掘Web日志
多的附加信息如用户机器名、内部IP名来标示用户,从而能识别通过同一代理服务器上网的不同用户。方法二是指不同的IP地址代表不同的用户。方法三要求根据网络拓朴结构分析Web日志文件中的用户请求,构造用户浏览网页的路径,通过一些启发式规则来识别用户。由于本文用到的日志属性信息较多,包括浏览器和操作系统属性,所以系统采用基于IP地址和浏览器的方法进行用户识别,即不同的IP地址和浏览器类型代表不同的用户,并在数据库的表UserTbl以及表IDTbl中添加一个域userID,用于存储进行识别后的用户标识。具体的过程如图4所示:
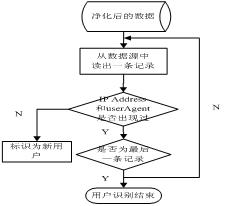
图4 用户识别流程图
4.2.3 会话识别
会话是指用户在访问网站期间从进入网站到离开网站所进行的一系列活动。要构造一个会话就是将每个用户的活动日志按照某种方法映射到会话中的过程。识别会话的方法主要有两种:基于时间的启发式方法和基于引用的启发式方法。前者利用会话的时间特性来构造会话候选集合;后者根据用户浏览特性和网页间链接关系确定用户会话集。
本文采用基于时间的启发式方法进行会话识别,即同一用户依次发出相邻的页面请求之间的时间间隔如不超过时间阈值,那么这两个页面请求属于同一个会话将时间阀值设定为20分钟。在数据库表中添加一个域sessionID,用于存储进行识别后的会话标识。进行会话识别的具体流程如图5所示。
5 Web日志数据仓库逻辑建模
要建立Web日志数据仓库,首先要进行逻辑建模。数据仓库一般有两种逻辑模式:星型模式和雪花模式。
星型模式是一种关系型数据库结构,其典型形式是由中间的一个主表和围绕在其周围的一组小表组成,中间的主表称为"事实表",外围的小表称为"维度表"。事实表中存储数值型度量指标和连接到维度表的外键,它包含了描述特定商业事件的数据,例如产品销售、网站访问情况等;维度表中存储用于描述事物的文本属性信息及连接到事实表的主键,它包含了用于参考存储在事实表中数据的数据,如时间、地理位置等。雪花模式是星型模式的变种,将一个或多个维表分解成多个表,每个表都有连接到主维度表而不是事实数据表的相关性维度表。
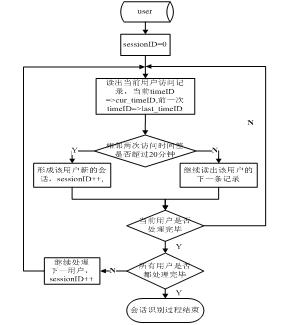
图5 会话识别流程图
根据分析主题的需要,Web日志数据仓库采用常用的星型模式,在SQL Sever 2000提供的Analysis Services平台下实现。结果如图6,它包括一个大的事实表和一组小的维表,事实表为FactTbl表,维度表为UserTbl、TimeTbl、PathTbl 以及ProtocolTbl,其中FactTbl表是由关系数据库中IDTbl表转换而来。
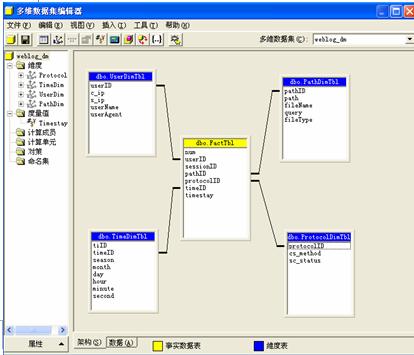
图6 Web日志数据仓库多维逻辑模型
在关系数据库中对IDTbl表进行聚集计算,可得到用户一次会话中每个页面的停留时间timestay,并通过离散化技术将timestay属性转化为每一页面的平均访问次数,定义为visit属性。关于这一过程,Cooley等在文献 [5] 中给出了详细步骤。将这两个属性及IDTbl表其它属性一起添加到FactTbl表,即形成了数据仓库的事实表,其中timestay和visit作为事实表的度量值,即希望在数据仓库中能查看并可以预测的数据。
6、结论
综上所述,实现一个Web日志数据仓库原型系统有两个关键点:预处理和逻辑建模。本文在解析Web日志时采取的一些预处理方法事实证明收到了良好的效果,可比较精确地识别用户及会话;在进行逻辑建模时采用星型逻辑模型,运用大量的冗余维度数据进行设计,大大提高了信息的检索性能。同时,文章实现了一个数据仓库原型系统,该系统简单实用,对原始的Web日志信息进行了维度上的分类,便于从特定时间段、特定用户等角度来实现对Web日志数据的进一步挖掘。
该系统尚存在一些不足之处,还有很多地方需要改进。例如在预处理阶段可以考虑将Web 页面结构和 Web 日志结合起来构造用户访问会话,减小会话集中出现的错误,使得模式发现阶段的结果更加准确和可信。并且可以将单纯的Web日志与其他用户信息数据结合分析,这样可以更好地发现用户行为模式。
- 惠普针对Web2.0等新应用发布超大容量刀片NAS(04-10)
- 抽象派 Web3.0 (01-30)
- 06年下半年Web2.0创投总量环比下降30%(01-05)
- 思科1.35亿收购Reactivity 强化XML专用设备(01-23)
- IBM旗下商业门户软件首次集成Google 应用(02-16)
- Web操作系统热门 Google微软即将面对强大对手 (02-19)