基于16位单片机的语音电子门锁系统
生物识别技术[2]是利用人体生物特征进行身份认证的一种技术,是目前公认的最为方便与安全的识别技术。由于每个人的生物特征具有与其他人不同的惟一性和在一定时期内不变的稳定性,不易伪造和假冒,所以利用生物识别技术进行身份认定,安全、准确、可靠。
在生物识别领域中,声纹识别,也称为说话人识别,以其独特的方便性、经济性和准确性等优势受到世人瞩目,并日益成为人们日常生活和工作中重要且普遍的安全认证方式。声纹识别是一种根据说话人语音波形中反映说话人生理和行为特征的语音参数,自动识别说话人身份的技术。
声纹识别技术可分为两类,即说话人辨认和说话人确认。前者用以判断某段语音是若干人中的哪一个所说的,是多选一的问题;而后者用以确认某段语音是否是指定的某个人所说的,是一对一判别的问题。从另一方面,声纹识别又有与文本有关和与文本无关两种,根据特定的任务和应用,应用范围不同。与文本有关的声纹识别系统要求用户按照规定的内容发音,每个人的声纹模型逐个被精确地建立,而识别时也必须按规定的内容发音,因此可以达到较好的识别效果;而与文本无关的识别系统则不规定说话人的发音内容,模型建立相对困难,但用户使用方便,应用范围较宽。
本文介绍的语音电子门锁是一种在凌阳16位单片机SPCE061A上实现的与文本有关的说话人确认系统。该系统主要由说话人识别模块、门锁控制电机以及门锁等部分组成。在训练时,说话人的声音通过麦克风进入说话人语音信号采集前端电路,由语音信号处理电路对采集的语音信号进行特征化和语音处理,提取说话人的个性特征参数并进行存储,形成说话人特征参数数据库。在识别时,将待识别语音与说话人特征参数数据库进行匹配,通过输出电路控制门锁电机,最终实现对门锁的控制。
1 算法原理
说话人识别算法原理框图如图1所示。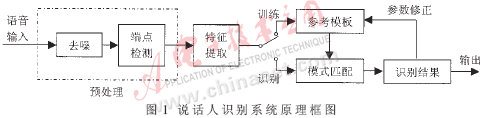
1.1 预处理
(1)去噪
对麦克风输入的模拟语音信号进行量化和采样,获得数字化的语音信号;再将含噪的语音信号通过去噪处理,得到干净的语音信号后并通过预加重技术滤除低频干扰,尤其是50Hz或60Hz的工频干扰,提升语音信号的高频部分,而且它还可以起到消除直流漂移、抑制随机噪声和提升清音部分能量的作用。
(2)端点检测
本系统采用语音信号的短时能量和短时过零率进行端点检测。语音信号的采样频率为8kHz,每帧数据为20ms,共计160个采样点。每隔20ms计算一次短时能量和短时过零率。通过对语音信号的短时能量和短时过零率检测可以剔除掉静默帧、白噪声帧和清音帧,最后保留对求取基音、LPCC等特征参数非常有用的浊音信号。
1.2 特征提取
在语音信号预处理后,接着是特征参数的提取。特征提取的任务就是提取语音信号中表征人的基本特征。
1.2.1 特征参数的选取
选取的特征必须能够有效地区分不同的说话人,且对同一说话人的变化保持相对稳定,同时要求特征参数计算简便,最好有高效快速算法,以保证识别的实时性。
说话人特征大体可归为下述几类:
(1)基于发声器官如声门、声道和鼻腔的生理结构而提取的参数。如谱包络、基音、共振峰等。其中基音能够很好地刻画说话人的声带特性,在很大程度上反映了人的个性特征。
(2)基于声道特征模型,通过线性预测分析得到的参数。包括线性预测系数(LPC)以及由线性预测导出的各种参数,如线性预测倒谱系数(LPCC)、部分相关系数、反射系数、对数面积比、LSP线谱对、线性预测残差等。根据前人的工作成果和实际测试比较,LPCC参数不但能较好地反映声道的共振峰特性,具有较好地识别效果,而且可以用比较简单的运算和较快的速度求得。
(3)基于人耳的听觉机理,反映听觉特性,模拟人耳对声音频率感知的特征参数。如美尔倒谱系数(MFCC)等。MFCC参数与基于线性预测的倒谱分析相比,突出的优点是不依赖全极点语音产生模型的假定,在与文本无关的说话人识别系统中MFCC参数能够比LPCC参数更好地提高系统的识别性能[3]。
此外,人们还通过对不同特征参量的组合来提高实际系统的性能。当各组合参量间相关性不大时,会有较好的效果,因为它们分别反映了语音信号的不同特征。
在计算机平台的仿真实验中,通过各种参数的实际比较,采用MFCC参数比采用LPCC参数有更好的识别效果。但在SPCE061A平台上做实时处理时,与LPCC系数相比,MFCC系数计算有两个缺点:一是计算时间长;二是精度难以保证。由于MFCC系数的计算需要FFT变换和对数操作,影响了计算的动态范围;要保证系统识别的实时性,就只有牺牲参数精度。而LPCC参数的计算有递推公式,速度和精度都可以保证,识别效果也满足实际需要。
本系统采用了基音周期和线性预测倒谱系数(LPCC)共同作为说话人识别的特征参数。
1.2.2 LPCC参数的提取
基于线性预测分析的倒谱参数LPCC可以通过简单的递推公式由线性预测系数求得。递推公式如下: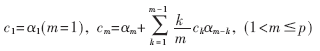
其中p为LPC模型的阶数,也是模型的极点个数。
(1)LPC模型阶数p的确定
为使模型假定更好地符合语音产生模型,应该使LPC模型的阶数p与共振峰个数相吻合,其次是考虑声门脉冲形状和口唇辐射影响的补偿。通常一对极点对应一个共振峰,10kHz采样的语音信号通常有5个共振峰,取p=10,对于8kHz采样的语音信号可取p=8。此外为了弥补鼻音中存在的零点以及其他因素引起的偏差,通常在上述阶数的基础上再增加两个极点,即分别是p=12和p=10。实验表明,选择LPC分析阶数p=12,对绝大多数语音信号的声道模型可以足够近似地逼近。p值选得过大虽然可以略微改善逼近效果,但也带来一些负作用,一方面是加大了计算量,另一方面有可能增添一些不必要的细节。
(2)线性预测系数的求取
自相关解法主要有杜宾(Durbin)算法、格型(Lattice)算法和舒尔(Schur)算法等几种递推算法。其中杜宾算法是目前最常用的算法,而且在求取LPC系数时计算量也最小,本系统采用该递推算法[4]。
1.2.3 基音参数的提取
基音估计的方法很多,主要有基于短时自相关函数和基于短时平均幅度差函数(AMDF)等基音估计方法。
(1)基于短时自相关函数的基音估计[4]
短时自相关函数在基音周期的整数倍位置存在较大的峰值,只要找出第一最大峰值的位置就可以估计出基音周期。
(2)基于短时平均幅度差函数(AMDF)的基音估计[4]
基于短时平均幅度差函数(AMDF)在基音周期的整数倍位置存在较大的谷值,找到第一最大谷值的位置就可以估计出基音周期。这种方法的缺点是当语音信号的幅度快速变化时,AMDF函数的谷值深度会减小,从而影响基音估计的精度。
实际上第一最大峰(谷)值点的位置有时并不能与基音周期吻合,第一最大峰(谷)值点的位置与短时窗的长度有关且会受到共振峰的干扰。一般窗长至少应大于两个基音周期,才可能获得较好的估计效果。语音中最长基音周期值约为20ms,本系统在估计基音周期时窗长选择40ms。为了减小共振峰的影响,首先对语音进行频率范围为[60,900]Hz的带通滤波。因为最高基音频率为450Hz,所以将上限频率设为900Hz可以保留语音的一、二次谐波,下限频率为60Hz是为了滤除50Hz的电源干扰。
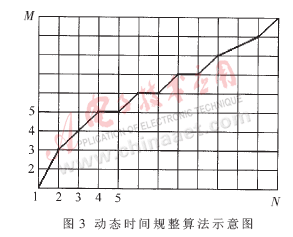
以上两种方法都是对语音信号本身求相应的函数。本系统采用的基音估计方法是:首先对带通滤波后的短时语音信号进行线性预测,求取预测残差;再对残差信号求自相关函数,找出第一最大峰值点的位置,即得到该段语音的基音估计值。实验表明,通过残差求取的基音轨迹比直接通过语音求取的基音轨迹效果更好,如图2所示。图2中横坐标为语音帧数,纵坐标为8000/f,其中f为基音频率。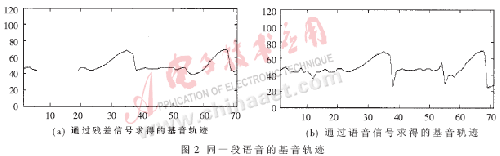
1.3 模式匹配
目前针对各种特征参数提出的模式匹配方法的研究越来越深入。典型的方法[4]有:矢量量化方法、高斯混合模型方法、隐马尔可夫模型方法、动态时间规整(DTW)方法和人工神经网络方法。
这些方法都有各自的优点和缺点。其中DTW算法对于较长语音的识别,模板匹配运算量太大,但对短语音(有效语音长度低于3s)的识别既简单又有效,而且并不比其他方法识别率低,特别适用于短语音、与文本有关的说话人识别系统。本系统采用端点松弛两点的(DTW)算法,端点松弛引起的计算量增加并不大,还可以放松对端点检测的精度要求。
动态时间规整(DTW)算法基于动态规划的思想,解决了说话人不同时期发音长短、语速不一样的匹配问题。DTW算法用于计算两个长度不同的模板之间的相似程度,用失真距离表示。假设测试模板和参考模板分别用T和R表示,按时间顺序含有N帧和M帧的语音参数(本系统为12维LPCC参数),失真距离越小,表示T、R越接近。把测试模板的各个帧号n=1~N在一个二维直角坐标系中的横轴上标出,把参考模板的各帧号m=1~M在纵轴上标出,如图3所示。通过这些表示帧号的整数坐标画出纵横线即形成网格,网格中的每一个交叉点(n,m)表示测试模板中某一帧与参考模式中某一帧的交会点,对应两个向量的欧氏距离。DTW算法可以归结为寻找一条通过此网格中若干交叉点的路径,使得该路径上节点的距离和(即失真距离)为最小[4]。对于端点松弛的情况,路径搜索原理相同,只是增加了搜索路径。