高性能32位移位寄存器单元的设计
类指令的实现
在我们设计的这片CPU中,需要对INTEL的 X86系列移位类指令进行兼容。因此移位寄存器单元需要在周围译码和锁存单元的配合下,要能在一个指令节拍内实现ROL,ROR,RCL,RCR, SHL,SHR,SAR,其中RCL,RCR实现了带标志位C的移位(指令说明见文献[4])。因此需由处理器的控制单元在每类移位指令移位之前进行指令的预处理。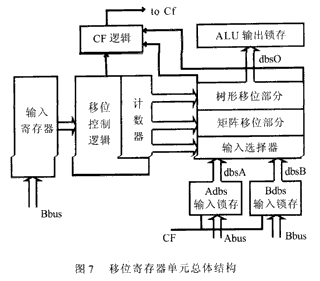
4.1 移位寄存器单元总体结构
最终设计出的移位寄存器单元总体结构如图7 所示,其中其核心部分的矩阵-树状结构的移位寄存器就是使用上一节所描述的结构。记数器中的数据(sh4~sh0)在移位上一拍由Bbus写入,并进行译码,其中低两位(sh1,sh0)直接送树状结构移位部分,高三位(sh4,sh3,sh2)经过译码产生8位控制信号送入矩阵移位部分。Abus和Bbus输入锁存器能锁存32位数据输入,并根据不同指令的要求进行操作,对指令进行预处理。移位结果送ALU输出锁存器,并对CF寄存器进行设置。
4.2 指令的预处理
由于要对实现带进位CF的移位并在移位操作后对CF进行设置,在一般情况下这需要CPU的控制单元提供多周期指令节拍来实现。在本设计中,将 Abus和Bbus输入锁存器设计为能根据不同的指令实现清0和带CF左移一位或右移一位的操作,以便为移位做好数据上的准备,使输入数据的0~32位移位能在一个指令周期内完成。对不同的指令具体设置情况如图8所示。图中CF表示为进位标志位;len为操作数长度(如32位数据); n为移位数;DATA表示输入锁存输出的数据为操作数据本身; 0表示输入锁存输出的数据为0;CF:DATA(-1)表示输入锁存输出的数据为操作数带CF右移一位;DATA(-1):CF表示输入锁存输出的数据为操作数带CF左移一位;SIGN_EXT表示输入锁存输出的数据为操作数带符号扩展。横线下为移位前Abus和Bbus锁存器中数据预处理完后的格式,横线上方位移位完成后数据输出及进位CF所处位置。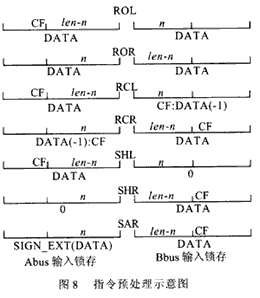
例:RCL AX , CL 指令
设AX=0001H , CL="3" , CF="1"
Abus锁存器输出数据为操作数本0001H; Bbus锁存器输出的数据为操作数带CF右移一位为1000H;
在输出中,CF在输出结果的最左端为0。
5 验证及结论
通过verilog的行为仿真及starsim的时序仿真显示,性能完全符合要求。对比INTEL X86指令集中移位类指令标准执行周期为4~7个机器周期,本设计移位类指令平均执行时间为2个指令周期,因此大大提高了移位类指令执行效率。移位寄存器作为CPU中执行单元的专用硬件,其性能的好坏直接影响到CPU处理移位类指令的速度和效率。本文采用的矩阵-树状结构移位寄存器,配合指令预处理技术,能有效实现32位数据的移位操作,并兼容INTEL X86系列的所有移位类指令还可作为通用硬件方便地移植到其他指令级别的CPU设计之中。
- DSP与单片机通信的多种方案设计(03-08)
- SoC前段(ARM)嵌入式系统开发实作训练(上) (02-28)
- 如何采用FPGA协处理器实现算法加速(04-29)
- 嵌入式系统中“软外设”的研究 (07-12)
- 彻底看穿双核CPU Intel与AMD多核处理器剖解 (07-12)
- 基于自适应DVFS的SoC低功耗技术研究(06-19)