改善嵌入式系统实时效能的新途径
在这个日趋复杂的世界,对于嵌入式处理器的要求也愈来愈高。去年也许使用128k的程序及4个实时处理绪列便足以执行应用程序,但是今年的产品规格已将所需内存提升为两倍,中断处理提高为三倍。要处理的信息本质似乎非常稳定-其实远比您想象的还要多!去年的微控制器必须在两个通讯总线上处理25笔4位的讯息,而今年已经必须要在4个通讯总线上处理200笔4位的讯息。在面对这种不断升高的工作负荷时,自然倾向寻求更强大的处理器来执行工作。一般来说处理器效能的传统趋势是提升速度及数据总线,所以一个8位处理器可从8MHz提升到16MHz,一个16位的装置升级为一个32位的装置。但是,两种作法都必须付出应用上的成本。更快的装置可能消耗更多的电力,而且较不符合EMC的要求,更大的位宽度则会造成先前的软件投资优势尽失,并导致更多的冗余(例如使用32位的缓存器来处理4位的资料)。
飞思卡尔半导体(前身为Motorola半导体产品部门)了解这个持续的趋势,因此在其新研发的S12X架构中采用创新的方法,可兼顾效能的提升与向后兼容性,并专注在效能提升的问题。这个新设计可在需要之处提升处理器的效能,也就是能实时处理信息。
动态内存存取(DMA)
改善系统实时效能的一个熟知的方法是,额外提供一个逻辑模块,在事件发生时产生响应,并允许处理器在较方便的时间来处理信息。这个DMA控制器通常将传送到模块的信息复制到内存(RAM),并允许已处理的信息自动从内存移到外部外围装置。所有这些工作皆独立于目前的CPU活动-详见图1。这种方式肯定有所助益,但其效益仅限于延迟必然发生的事件-CPU还是得在某一时间处理信息。S12X采用一个根本的方法,即提供「智能型DMA」控制器,不只移动资料,同时直接执行所有的处理工作。如图2所示,这个新的XGate可以从外围装罝撷取信息,连同其它资料(例如内存中的资料)一并处理,然后传送到另一个外围装置,其间完全不需CPU的介入。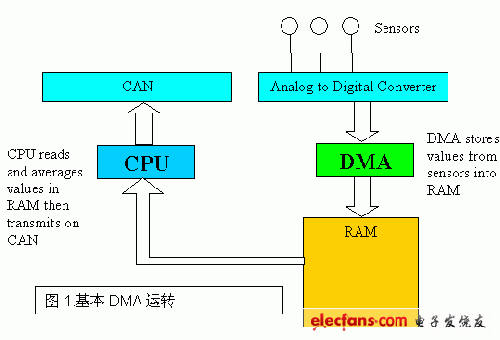
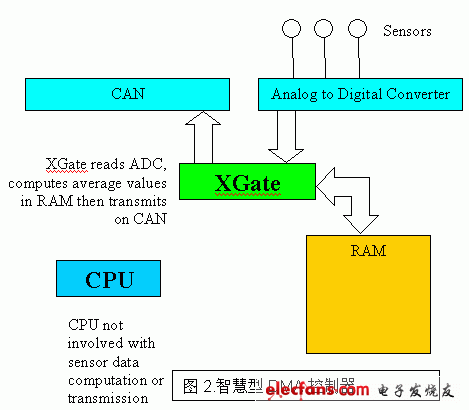
XGate控制器已完全整合到新推出的MC9S12XDP512微控制器-畅销的飞思卡尔半导体S12家族最新成员。XGate是一个可程序的16位RISC核心,极适用于实时及DMA类型运作。与S12X装置的整合意谓从微控制器的任何一个外围装置传来的中断都可以由主CPU或XGate处理。XGate可以:(1)读写所有外围装置及内存:(2)读取闪存(flash)中的信息。
可设定以执行复杂的工作
为了让XGate达到最大效能,其主要程序通常储存位于内存中。这使得80MHz的时脉可应用于控制器,相对于S12X CPU只需使用40MHz。而且,S12X架构不同于传统的DMA,可保证XGate每一个CPU周期至少可存取内存一次。
XGate编程
如要让「智能型DMA」更为实用,必须使它容易编程。在理想的环境下,软件工程师应该能够导入以C语言编写的既有程序代码,并针对DMA重新组译。基于这个原因,XGate选择16位RISC机器作为程序撰写模式,并有适用于C语言程序的指令集。
一般的系统完整性检查系透过CRC16计算,也就是对一组资料模块进行多项式计算,并透过产生最终检核码的值,来确认内存内容符合预期。这种算法可利用周期性的中断来呼叫。飞思卡尔S12 MCU的这种算法之典型建置如图3所示。在S12X上,此一算法可在XGate定期重新组译及执行,其好处是系统设计者可在CPU上执行更多处理,却不会降低系统检查的效益。XGate不仅释放CPU给其它活动,同时还使这个简单算法的执行时间,获得了4倍的惊人改善。这也让设计者可以在相同期间所执行的CRC演算次数高4倍,藉此改善系统的自我检查能力。值得注意的是,这项革命性的架构方法,仅透过简单的重新组译及重新导向周期性的中断,便可带来这些重大的优点。
S12X的自动化应用
大多数汽车应用对实时效能的要求都很高,通常超过模块的实际功能。例如汽车的仪表板必须可以显示车辆目前的状态,同时可接收并处理从传感器传来的实时讯息。由于XGate不仅可以接收这项信息,还可予以格式化并储存,因此CPU可用来响应驾驶人互动的时间便大量增加,更可减少显示器可能出现的噪声干扰。
根据广泛使用的S12架构,这种双重方法的好处就非常明显了。
大多数现代化汽车都是利用通讯网关来允许不同的通讯网路互传讯息。此外,网关还可以执行其它功能。XGate可以在大约4μs内执行一个典型的网关工作(检查CAN ID,储存于内存,然后复制到传送缓冲器(transmit buffer)中),而S12需9μs。这表示使用XGate,CPU可储存高于9us的中断。对一个具有5个CAN网络完全满载的非常忙碌连接网关而言,它可节省超过20%的CPU处理能力,却仅用到XGate的10%。
对于一个更复杂的网关而言,要将个别位字段或讯号在多个CAN上进行路由传送,XGate的处理速
- AT91系列ARM硬件设计笔记(09-19)
- 内嵌TCP/IP协议的CDMA无线终端(03-26)
- 如何采用FPGA协处理器实现算法加速(04-29)
- 基于MPC8260和FPGA的DMA接口设计(04-26)
- 基于ARM和CDMA的远程视频监控系统(04-27)
- 通过架构改进提高微控制器处理效率(01-11)