多核处理器构架的高速JPEG解码算法
形和多媒体数据的处理速度,处理器着重于扩展其并行处理数据的能力。这样的扩展主要表现在两个方面:一方面使用VLlW构架的处理器核(这样的处理器核一次最多能够并行执行8条指令,这样的并行性主要由编译器支持,这是一种指令的并行性);另一方面使用多核处理器(CMP)的构架,使针对应用划分的任务能够真正并行地运行在多个处理器核上。(这样的并行性需要由应用支持,通过恰当的划分任务来实现)
3 JPEG解码算法在多核处理器上的实现
针对FRl000处理器的特点,需要对JPEG图像的解码划分为适当的可以并行执行的任务进行处理。比较直观的想法是,将JPEG图像划分为4个部分,分别在4个处理器核上进行解码。但由于JPEG图像的数据流是变长编码,根据现有的数据流,难以将其划分为4个能并行解码的图像。(这样的划分付出的时间代价过大)
根据前面所叙述的JPEG图像解码原理可以看出,解码的基本单位是MCU,因此在第一步熵解码之后生成的MCU是可以并行解码的最小单元。因此对一个JPEG图像在多核处理器上进行并行解码的关键在于,将此,JPEG图像所包含的MCU负载均衡地分配到各个处理器核上进行并行解码处理。
由此,处理方法有两种:一种是以一个MCU作为任务分配的单位,由PM通过熵解码生成MCU,然后将MCU均匀地分配到各个处理器核(PE)上,由各个处理器核在完成MCU的解码之后再写入到位图的相应位置。这样做的好处有两点:①可以做到很好的负载均衡,使每一个处理器核都承担几乎相同的负载。②可以使熵解码和MCU的解码并行进行。但这种做法的一个很大问题在于处理器核之间通信所消耗的时间代价过大。因为这可以抽象为一种生产者与消费者的模型,生产者在每次生产出一个MCU的时候都需要与消费者进行一次通信或者说更新消费者端的数据输入。经过实测以后发现,这种做法所带来的通信开销过大,占到解码程序运行时间的20%以上。这种做法的另外一个问题在于内存的读写,由于各个处理器核需要交错地写入内存的同一块区域,导致对于此块内存的写入不能使用写回(copy back)模式。因为如果各个处理器核使用写回模式,会导致各个处理器核中cache的数据与内存中的数据不一致而出现错误。
另外一种处理方式是通过划分图像块来实现的。由于MCU是与原始位图由上到下、由左到右一一对应的,因此将JPEG图像按高度等分为4个图像块,而这样的图像块的高度必须为MCU的整数倍。然后由各个处理器核分别解码各个图像块,在指定的内存区域写入解码结果以拼接为一幅完整的原始位图。
这种处理方式的关键在于,每个处理器核怎样快速地定位到自己需要解码的那部分图像块。由于JPEG是变长编码,所以不存在一个O(1)的算法使之能够通过一定的偏移量进行定位,但可以修改熵解码部分的代码,使其能够跳过不必要的解码,快速定位到需要处理的区域。具体来说,定位的过程实际上就是对MCU进行计数的过程,定位时没有必要保存MCU的内容,只需要对解出来的MCU进行计数。由于MCU与原始位图的一一对应关系,所以可以通过对MCU的计数来定位到需要处理的区域。具体换算公式如下:

其中Height表示图像高度,Width表示图像宽度,PEID表示每个处理器核所对应的编号(1~4)。
各处理器核的解码流程如图4所示。
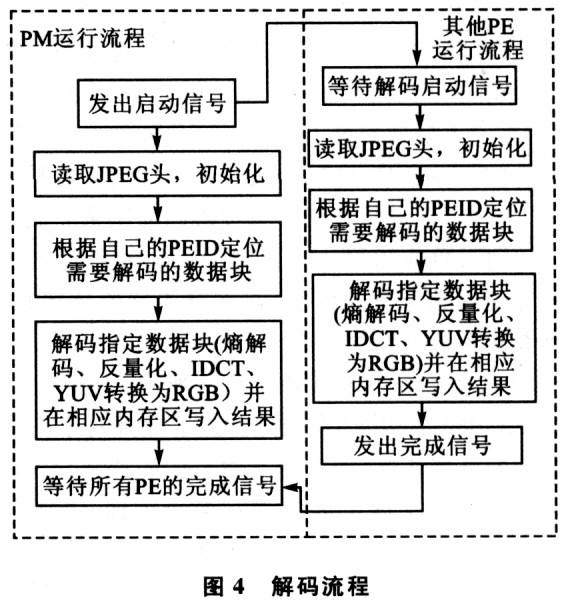
这种处理方式的问题在于,每一个处理器核都需要花费额外的时间来定位需要解码的数据块;但实测以后发现,定位操作所消耗的时间只占5%左右。因为在FRl000平台上,大量的解码时间消耗主要在于IDCT变换和YUV到RGB的颜色空间转换上面。这种处理方式降低了通信的时间消耗,在一幅JPEG的图像解码中只需要两次处理器核之问的通信。这种处理方式的另外一个好处在于,每一个PE在写入结果的位图数据时可以对内存的写入采用写回(copy back)模式,只需要在图像块交界的地方作刷新cache的操作就可以保证结果的正确性。在随后的关于优化的讨论中可以看到,这种方式对于提高解码的速度起着相当重要的作用。
4 优化
一般来说,一个程序在多核处理器上的运行时间除上在其中一个单核处理器上的运行时间称为多核并行度(MP)。在有4个处理器核的FRl000处理器上,MP的极限值(存在必要的通信开销)应该为25%。但根据图3的解码流程,实测的MP只有43%左右。进一步分析后发现,由于多个处理器核沿相同的流程进行解码,从而在相同的时间里对内存有大量并发的读写操作,而这样的并发操作导致对于内存的读写成为系统的瓶颈。在单核上需要16~20个周期的1行cache读入操作,在多个处理器核同时运行时,需要30~40个周期才能完成。
优化主要从两个方面进行:
①尽量减少对内存的读写操作。一般的JPEG解码程序,会以行为单位保存熵解码后的中间结果,也就是使用存储1行MCU的空间作为临时缓冲区。这样的临时缓存区是随着图像行的宽度增大而增大的,当图像的宽度变大到一定程度的时候,这样的临时缓存将很可能大到没有办法驻留在cache中,cache不命中从而导致大量的内存读写和对于cache的置换。优化后将其改为熵解码完一个MCU后,立即作反量化、IDCT和颜色空间变换,直至写入位图。这样只需要一个MCU大小的临时缓存。可以保证这样的缓冲一直保存在cache中,从而避免大量的读写内存的操作。但这样的方式需要恰当的判断边界条件,如前所述,由于图像的长宽不一定是MCU的整数倍,所以在最下一行和最右一列有填充数据,需要在解码的时候丢弃掉。
②恰当地选择内存的读写模式。由于整个解码程序中,在最后写入位图时需要大量地写入内存的操作。如果使用写透(write through)模式,每次均同时写入cache和内存,这样必然会造成大量的内存读写操作。所以在写入位图的区域使用写回模式,这样只需要在每次cache行置换的时候需要写入内存,极大地减少了对于内存的读写操作。但需要注意的是,在多核处理器的环境下,必须保证该内存区域和各个处理器核上的cache数据之间的一致性。这需要恰当地划分各个处理器核的内存读写区域,并且在读写各个区域交界的地方时用指令刷新相应的cache行。
值得注意的是,在多核处理器的构架上,由于多个处理器会并行访问内存,所以内存很容易成为瓶颈,在涉及大量内存操作的图像处理程序方面表现得尤为突出。因此对于程序的优化应该着重将注意力放在对于内存的读写优化方面。
- 基于LPC2292的手持JPEG图像显示器设计(10-28)
- 多核嵌入式处理技术推动汽车技术发展(11-18)
- 多核处理器的九大关键技术(03-02)
- 多核处理器设计的九大关键问题(03-16)
- 借力big.LITTLE设计架构 多核处理器强效又省电(11-19)
- 多核处理器将如何改变电源管理?(11-19)