如何调试复杂的实时嵌入式系统?
时间:05-20
来源:EDN
点击:
内存和寄存器的数据讹误
大多数的嵌入式系统都采用了平面化的内存模式,也并没有内存管理单元(MMU),于是没有硬件支持的内存保护机制。即使采用能提供这种功能的处理器,也需要由开发商来实现对某些内存区域的保护。进程和线程将对其它进程和线程的内存空间有完全的访问权限。这可能会造成下面所描述的、各种类型的内存讹误问题。
堆栈溢出
运行时堆栈是在函数调用进程中所使用的一种暂存空间,用于存储局部变量。硬件寄存器指针(SP)将跟踪堆栈指针的地址。如果你在高级的语言中编程,如C语音,则编译器所生成的代码将使用与C语言运行时间模型相一致的堆栈。运行时间模式定义了变量是如何存储在堆栈中的以及编译器将如何使用堆栈。局部的变量被放置在当前的堆栈中。下面给出的例子描述了在堆栈上采用的某些关键性的内存。
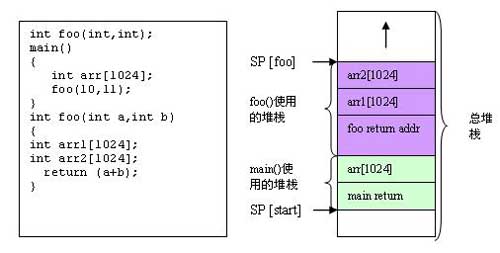
当堆栈指针超出了其所指定的边界时,就会出现堆栈溢出。这将造成内存的讹误,并最终造成系统的失效。在上述的实例中,如果总的堆栈内存区不足以容纳所有的局部变量,堆栈溢出就会发生。
调试的一个技巧就是,如果你担心溢出,一个好的做法,就是将堆栈安排在内存边界上,这样,如果在调试过程中出现了溢出,则仿真器将触发一个硬件异常提示。
开发商可以采用的一个技巧是,如果你担心堆栈的溢出,你就应当考虑把它放在有效的内存的边界上。这样,当堆栈溢出时,设备将报告硬件异常,而不是造成其它内存空间的讹误。
在独立运行的应用中,运行时间堆栈可能就已经够用。然而,在使用任何一种实时操作系统时,每个线程和过程都将有自己的堆栈。考虑到性能方面的原因,大多数嵌入式实时操作系统的堆栈尺寸都是事先确定的,无法在运行中动态扩展。这意味着,如果针对特定的线程/进程所选用的堆栈尺寸不恰当的话,堆栈溢出就会发生。
如果应用大量使用局部变量(如阵列和大的结构),则将不得不按比例为其分配堆栈的空间。人们可以利用malloc() 来分配内存,或者将其设置为静态的全局变量,具体是何种方法,则取决于实际应用。
有些实时操作系统可能会提供调试功能,例如保护位,以形成对堆栈溢出的防护。这些操作系统要么记录关于堆栈溢出的错误信息,要么提交一个异常报告,以便动态地增加堆栈。最起码当前的大多数实时操作系统都能报告堆栈以及已经被线程和进程所采用的堆栈的情况。
在任何中断驱动的系统中,堆栈的分配方式都必须考虑到中断服务例程所采用的空间。如果中断例程的设计目标是使用当前的执行对象栈,则在这种情况下,每一个线程或进程所拥有的最小的堆栈尺寸都应大于或者等于执行对象所要求的堆栈尺寸加上所有中断例程累积起来所需要的最大的堆栈尺寸。
嵌入式系统开发商必须掌握各种应用链接库。例如,第三方的库可能会认定堆栈上为其提供了空间。
中断服务例程代码编写时所出的问题:
在嵌入式系统中,一般情况下,出于性能方面的考虑,中断服务例程是以汇编形式编写的。中断本质上是异步的,在应用执行中的任何时刻都有可能出现。汇编层次上的中断例程最常见的问题,是寄存器的讹误。在中断服务例程中所采用的寄存器所存储的数据,在寄存器被使用之前都必须被保存,而在从中断服务例程返回之前,这些数据将被恢复。开发商必须了解状态寄存器的情况,而任何一种ALU的操作都会改变其状态。在这种情形中,ISR应该保存其状态并进行恢复,仿佛它是一个已被使用的寄存器一般。
如果中断例程是用C语言编写 的,它们的开发也是为了使用当前的堆栈,则开发商就应该针对堆栈溢出情况进行防护,即每个线程都应该拥有足够多的堆栈,来满足中断或者嵌套的中断堆栈的要求。最好的做法,就是让中断例程的规模尽可能小,推迟处理过程,交给一个线程或者优先级较低的中断。在开发过程中,开发商可以在中断的开始和结束部分添加诊断功能,对基础的架构中的寄存器的状态进行比较。
中断嵌套可以让一个高优先级的中断抢先于低优先级的中断例程执行。开发商应该考虑到堆栈要求的峰值,并为其分配充足的空间(考虑最差的情况,即你的系统中的每一个中断都被一个优先级更高的中断所抢先)。
而操作内存映射寄存器(MMR)时,人们常常采用在线汇编以改善性能。例如,你在屏蔽中断时,可能希望直接设定中断屏蔽寄存器(IMASK)而不是执行RTOS所提供的应用软件编程接口(API)。例如原子增加或减少操作常常是用汇编语言编写的。在C函数中,这些宏汇编可能会被调用,在这种情况下,编译器可能不了解在宏汇编中所使用的
寄存器。因此这会导致寄存器的讹误。有些编译器具有汇编的扩展版,可以将关于这些函数的更多的信息传递给编译器,例如已被使用的寄存器、代码在内存中的位置等等。这将使得编译器可以生成恰当的代码。
有时,某些函数是以汇编语言编写的,将被C函数所调用。如果汇编代码并未按照C函数运行时间调用规范来编写,即按照编译器所要求的那样进行,则会导致参数传递(argument passing)无效和讹误。例如,C函数运行时间模型可以规定前两个参量必须通过寄存器R0和R1来传递,则汇编的实现方式就必须按照这种语法来编写。在另一种情况下,运行时间模型可能需要存储堆栈上的函数的返回地址。如果汇编的实现方法并不符合运行时间模型,则它可能会搅乱某些 寄存器,并带来系统的故障。如果开发商使用混合模式的语言来避免这种类型的问题的话,开发商就必须清楚运行时间模型。
大多数的嵌入式系统都采用了平面化的内存模式,也并没有内存管理单元(MMU),于是没有硬件支持的内存保护机制。即使采用能提供这种功能的处理器,也需要由开发商来实现对某些内存区域的保护。进程和线程将对其它进程和线程的内存空间有完全的访问权限。这可能会造成下面所描述的、各种类型的内存讹误问题。
堆栈溢出
运行时堆栈是在函数调用进程中所使用的一种暂存空间,用于存储局部变量。硬件寄存器指针(SP)将跟踪堆栈指针的地址。如果你在高级的语言中编程,如C语音,则编译器所生成的代码将使用与C语言运行时间模型相一致的堆栈。运行时间模式定义了变量是如何存储在堆栈中的以及编译器将如何使用堆栈。局部的变量被放置在当前的堆栈中。下面给出的例子描述了在堆栈上采用的某些关键性的内存。
当堆栈指针超出了其所指定的边界时,就会出现堆栈溢出。这将造成内存的讹误,并最终造成系统的失效。在上述的实例中,如果总的堆栈内存区不足以容纳所有的局部变量,堆栈溢出就会发生。
调试的一个技巧就是,如果你担心溢出,一个好的做法,就是将堆栈安排在内存边界上,这样,如果在调试过程中出现了溢出,则仿真器将触发一个硬件异常提示。
开发商可以采用的一个技巧是,如果你担心堆栈的溢出,你就应当考虑把它放在有效的内存的边界上。这样,当堆栈溢出时,设备将报告硬件异常,而不是造成其它内存空间的讹误。
在独立运行的应用中,运行时间堆栈可能就已经够用。然而,在使用任何一种实时操作系统时,每个线程和过程都将有自己的堆栈。考虑到性能方面的原因,大多数嵌入式实时操作系统的堆栈尺寸都是事先确定的,无法在运行中动态扩展。这意味着,如果针对特定的线程/进程所选用的堆栈尺寸不恰当的话,堆栈溢出就会发生。
如果应用大量使用局部变量(如阵列和大的结构),则将不得不按比例为其分配堆栈的空间。人们可以利用malloc() 来分配内存,或者将其设置为静态的全局变量,具体是何种方法,则取决于实际应用。
有些实时操作系统可能会提供调试功能,例如保护位,以形成对堆栈溢出的防护。这些操作系统要么记录关于堆栈溢出的错误信息,要么提交一个异常报告,以便动态地增加堆栈。最起码当前的大多数实时操作系统都能报告堆栈以及已经被线程和进程所采用的堆栈的情况。
在任何中断驱动的系统中,堆栈的分配方式都必须考虑到中断服务例程所采用的空间。如果中断例程的设计目标是使用当前的执行对象栈,则在这种情况下,每一个线程或进程所拥有的最小的堆栈尺寸都应大于或者等于执行对象所要求的堆栈尺寸加上所有中断例程累积起来所需要的最大的堆栈尺寸。
嵌入式系统开发商必须掌握各种应用链接库。例如,第三方的库可能会认定堆栈上为其提供了空间。
中断服务例程代码编写时所出的问题:
在嵌入式系统中,一般情况下,出于性能方面的考虑,中断服务例程是以汇编形式编写的。中断本质上是异步的,在应用执行中的任何时刻都有可能出现。汇编层次上的中断例程最常见的问题,是寄存器的讹误。在中断服务例程中所采用的寄存器所存储的数据,在寄存器被使用之前都必须被保存,而在从中断服务例程返回之前,这些数据将被恢复。开发商必须了解状态寄存器的情况,而任何一种ALU的操作都会改变其状态。在这种情形中,ISR应该保存其状态并进行恢复,仿佛它是一个已被使用的寄存器一般。
如果中断例程是用C语言编写 的,它们的开发也是为了使用当前的堆栈,则开发商就应该针对堆栈溢出情况进行防护,即每个线程都应该拥有足够多的堆栈,来满足中断或者嵌套的中断堆栈的要求。最好的做法,就是让中断例程的规模尽可能小,推迟处理过程,交给一个线程或者优先级较低的中断。在开发过程中,开发商可以在中断的开始和结束部分添加诊断功能,对基础的架构中的寄存器的状态进行比较。
中断嵌套可以让一个高优先级的中断抢先于低优先级的中断例程执行。开发商应该考虑到堆栈要求的峰值,并为其分配充足的空间(考虑最差的情况,即你的系统中的每一个中断都被一个优先级更高的中断所抢先)。
而操作内存映射寄存器(MMR)时,人们常常采用在线汇编以改善性能。例如,你在屏蔽中断时,可能希望直接设定中断屏蔽寄存器(IMASK)而不是执行RTOS所提供的应用软件编程接口(API)。例如原子增加或减少操作常常是用汇编语言编写的。在C函数中,这些宏汇编可能会被调用,在这种情况下,编译器可能不了解在宏汇编中所使用的
寄存器。因此这会导致寄存器的讹误。有些编译器具有汇编的扩展版,可以将关于这些函数的更多的信息传递给编译器,例如已被使用的寄存器、代码在内存中的位置等等。这将使得编译器可以生成恰当的代码。
有时,某些函数是以汇编语言编写的,将被C函数所调用。如果汇编代码并未按照C函数运行时间调用规范来编写,即按照编译器所要求的那样进行,则会导致参数传递(argument passing)无效和讹误。例如,C函数运行时间模型可以规定前两个参量必须通过寄存器R0和R1来传递,则汇编的实现方式就必须按照这种语法来编写。在另一种情况下,运行时间模型可能需要存储堆栈上的函数的返回地址。如果汇编的实现方法并不符合运行时间模型,则它可能会搅乱某些 寄存器,并带来系统的故障。如果开发商使用混合模式的语言来避免这种类型的问题的话,开发商就必须清楚运行时间模型。
- 基于MPC755的嵌入式计算机系统设计(05-10)
- 为什么嵌入式开发人员要使用FPGA(05-13)
- VxWorks几种常用的延时方法介绍(05-16)
- VxWorks实时操作系统下MPC8260ATM驱动的实现(11-11)
- VXWORKS内核分析(11-11)
- 嵌入式实时操作系统设计探讨(10-15)