基于CUDA技术模拟雷达余辉的方法
3 采用CUDA技术来实现余辉效果
为了产生不同方位的扫描线,将方位、距离进行量化,由于扫描区域的分辨率为1 024×1 024,因此半径为512像素。由于扫描半径为512个像素,理论上只要角度量化数N大于3 217就不会出现显示死地址的现象[10],方位上量化为4 096个等分。这样初始生成一个4 096×512个像素的圆域。雷达P显中采用的是极坐标系,而在光栅显示器中采用的是直角坐标,通过坐标变换,将建立一张坐标变换表,如表1所示。
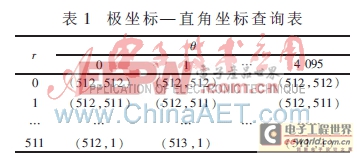
通过查表可以避免坐标变换带来的正余弦计算,方便地在极坐标和直角坐标间转换,从而节省大量的运算时间[11]。考虑到近距离区域,多个角度的距离单元会对应相同的像素点,首先为每个像素点定义一个属性的结构体:
typedef struct
{ WORD x;//屏幕直角坐标x
WORD y;//屏幕直角坐标y
WORD ScanlinePtIndex;//该点在扫描线上的
//距离索引
BYTE MapTo2Pt;//该点与同一条扫描上的
//点是否重合
BYTE RadEnd;//标记该条扫描线处理完毕
}RADIUSPOINT;
为圆域内的点分配内存空间:
RADIUSPOINT m_pRadPtToLintPtMap=new RADIUSPOINT[4 096×512]。
对于同一条扫描线上相邻的两点,如果直角坐标相同就把MapTo2Pt设为1,标记为相同的点;如果相邻两点的直角坐标不相同,则把距离索引值赋给ScanlinePtIndex,每条线最后一个点设置RadEnd为1来标记每条线处理已完毕。对于相邻两条线上的点,如果当前线上点与前一条线上相邻4个点的直角坐标相等,设置为m_pPixelOverlap[i]=1,否则设为0。
考虑到余辉呈指数型衰减,而指数运算需要花费大量的时间,对于计算机,其最快的操作是取值和赋值,为了提高光栅扫描雷达显示系统的实时性,需要提高单位时间内能够处理的像素点个数。于是对指数运算采用查表法以提高速度,维护一张按角度划分的指数型衰减因子表m_wAttenuation[4 096]以进行数值的取值和赋值操作。
同时还要建立一个Brightness[4 096×512]的亮度表,来存储每个像素对应的RGB颜色值。
以上这些工作在程序的初始化中即完成,一经完成即可在后续的程序中直接调用。
通过CUDA编程时,GPU可看作为可以并行执行非常多个线程的计算设备,执行并行计算的线程被组织成线程块(Block),每个线程块可以包含多达512个线程,而线程块又组成了栅格(Grid)。GPU可以支持成百上千万个并行线程,于是可以为每个像素点开一个线程,这样每个像素点可以并行处理,能极大地提高对整个屏幕像素的处理速度,为CPU留出足够多的时间去处理其他相关的任务。
定义线程块Block包含的线程维数:
dim3 threads(BLOCK_SIZE,BLOCK_SIZE);
定义栅格Grid包含的线程块数:
dim3 grid(Width/threads.x,Height/ threads.y);
每个像素点对应的线程处理工作如下:
由于某型雷达转速为10转/min,相当于每次更新的扫描线数应为4 096×10/60/1 000=0.683条/ms,像素处理在GPU中并行进行,对CPU的占用率几乎为零,所消耗的时间主要是Direct3D纹理的绘制和表面的翻转,大约为16 ms,因此每次更新的扫描线数目约为16×0.683=10.928,即每次更新11条。将当前要更新的扫描线上的像素点设为初始亮度,其后的每条扫描线上的像素点的亮度按与当前扫描线角度差m_anglediff取m_wAttenuation[m_anglediff]的亮度进行衰减。由于近距离区域多个角度的距离单元对应相同的像素点,因此中心部位被消隐的次数明显要比其他部位多,导致效果有些失真。于是需要对这些坐标相同的点进行处理,对于属性MapTo2Pt为1的点,比较坐标相同的点处于不同距离时的亮度,取其大者赋值给亮度表Brightness[4 096×512]。对于属性m_pPixelOverlap为1的点,比较处于各个角度时的亮度,取其大者赋值给亮度表。这样对于同一个点只显示一次且取其最亮者显示,较好地避免了中心部位被消隐次数过多的情况。
对于实现余辉等级的情况,只需要调制m_wAttenuation的大小就可以方便地调节余辉等级。如果需要提高转速,只需增大每次更新的扫描线数目即可,且基本不会影响程序运行速度。
通过CPU+GPU组合的方式模拟不同等级余辉效果如图1、图2所示,此时对应的CPU占用率几乎为零,如图3所示。该方法得到的余辉效果逼真、画面流畅、扫描速度达到了预定的10转/s的要求,且CPU占用率极低,并不妨碍CPU处理其他数据。


当把每次需要更新的扫描线数目增多时,由于GPU能并行高速处理每个像素点,扫描的速度能迅速提升而不影响显示画质,在程序调试时,可以验证当扫描速度到45转/min时,画面依然流畅且占用的系统资源少。
余辉实现的逼真程度很大程度上决定了雷达模拟器的效果,本文就当前余辉模拟存在的瓶颈提出了一种基于CUDA的解决方案,采用“CPU+DPU”编程的方法,很好地解决了数据吞吐量巨大的问题。此方法模拟的余辉易于与雷达回波信号叠加,便于程序的扩展,可以应用于模拟器的设计及雷达技术的研发。
- Windows CE 进程、线程和内存管理(11-09)
- RedHatLinux新手入门教程(5)(11-12)
- uClinux介绍(11-09)
- openwebmailV1.60安装教学(11-12)
- Linux嵌入式系统开发平台选型探讨(11-09)
- Windows CE 进程、线程和内存管理(二)(11-09)