基于中英文数字语音登陆系统的仿真研究
引言
语言是人与人之间在日常交往中最直接也是最强大的工具,然而我们并不满足于人与人之间的对话,而是通过语音识别技术来实现人机对话,语音识别技术的终极目标就是能够让人类与计算机进行自由地交谈。随着语音识别技术的逐渐成熟及近些年来已经取得的进步,英文数字语音识别在其发展的20多年间已达到了很高的识别率,汉语数字语音识别也经过多年研究在PC平台和实验室条件下达到了高性能,但中英文混合连续数字语音识别还有待进一步研究,张晴晴等人研究的中英双语混合语音识别的识别率为16.8%,远低于理想中的识别率。为使识别效果达到可实用的水平,本系统首先从基本的中英文数字语音识别出发,从而为相应的登录注册系统做出一些尝试。
本文研究的中英文连续数字语音识别,包含中文0-10和英文zero-ten的数字语音识别,其中包括对语音信号的预处理、特征参数提取、中英文声学模型与语言模型的训练及模版匹配等,适合于研究数字语音登录系统,比如用户用中英文任何语言念学号或是身份证号就能登陆,免去书写的麻烦,同时也对后续研究中英文混合连续语音识别奠定了基础。
语音识别原理
根据对说话人说话方式的要求,语音识别可以分为孤立字(词)语音识别系统,连接字语音识别系统以及连续语音识别系统;根据对说话人的依赖程度,语音识别可以分为特定人和非特定人语音识别系统;根据词汇量大小,又可以分为小词汇量、中等词汇量、大词汇量以及无限词汇量的语音识别系统。不同的语音识别系统,其目的和功能各不相同,但它们所采用的基本框架大体一致,语音识别基本流程如图1。
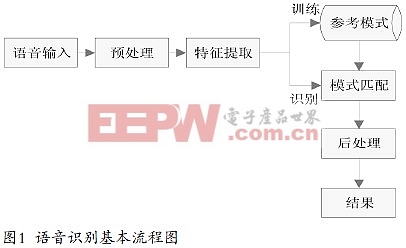
语音识别的过程,其本质就是模式匹配的过程。语音信号经过预处理、语音信号的特征提取、声学模型的训练与模式匹配后,经过处理输出识别结果。其中:
1)预处理是对输入的原始语音信号进行处理,滤除掉其中不重要的信息和背景噪声,并进行语音信号的端点检测、语音分帧以及预加重等处理。
2)特征提取主要负责计算语音的声学参数,并进行特征的计算,以便提取出反映信号特征的关键特征参数,从而用于后续处理。因Mel频率倒谱系数(MFCC)具有良好的抗噪性和鲁棒性,故本文采用MFCC提取特征参数。
3)训练阶段是用户通过输入若干次训练语音后,经预处理和特征提取后得到特征矢量参数,建立或修改训练语音的参考模式库。
4)识别阶段是将输入的语音提取特征矢量参数与参考模式库中的模式进行匹配,得出最终的识别结果。

- 基于TMS320VC5509A的语音识别与控制系统(06-17)
- 基于DSP的声控电子记事本的设计与实现(09-22)
- 孤立词语音识别系统的DSP实现(04-28)
- 语音识别及其定点DSP实现(06-14)
- 说话人识别算法的定点DSP实现(03-18)
- 基于ATK的实时语音识别系统在家庭监护机器人中的应用实现(04-28)