粗粒度的时空计算
统一设计的。 首先,阵列数据及其特例(标量数据和向量数据)在MATLAB语言中已有明确的表示[9] 。阵列数据就是C语言中的Data Array(数据阵列/数组),是用来表示同一类型的标量数据的集合的。因此,阵列语言的数据表示和类型,可以与C语言的相同而统一的。在阵列语言中,阵列数据采用了与MATLAB或C语言类似的顺序描述方法。 二是阵列数据的计算,与数学语言的矩阵加减法计算一样,是对其标量数据元素进行的。计算的操作类型及其表示符号均可以与C语言中的相同而统一的,只需要补充支持实现几何变换的播送(broadcast)等3个操作及其操作符。 三是由于控制语句是时间一维的,阵列语言的控制语句是可以与标量语言(例如C语言)的控制语句相同而统一的。而计算语句则应由标量语句上升到由不同标量语句元素(statement elements)组成的阵列语句。标量语句元素的设计是可以与C语言的标量语句的设计相同而统一的。阵列语句的描述可以像C语言的Data Array那样,采用先行后列,并从第一行开始顺序描述的程序设计方法。使阵列语言统一了标量语言,继承顺序程序设计的特点,建立了阵列语言的程序设计的确定性。 阵列计算机 最近,人们分析发现,自1985年以来,计算机体系结构革新与芯片技术进步对计算机性能的贡献是相当的[10] 。现在的芯片制造技术,已经可以研制粗粒度计算的二维的阵列处理器(Array Processor)和三维(时间1维+空间2维)的阵列存储器(Array Memory)。例如,Intel公司80个处理元的TeraScale Processor计划的系统芯片[11] 。支持粗粒度时空计算的阵列计算机,可以是由指令存储器、阵列处理器和阵列存储器组成的。其实,冯.诺依曼体系结构的Flynn分类,以单指令流多数据流的SIMD(Single Instruction Multiple Data)体系结构,可以在阵列处理器上实现DLP计算模式的数据粗粒度的计算。以多指令流单数据流的MISD(Multiple Instruction Single Data)和多指令流多数据流MIMD(Multiple Instruction Multiple Data)体系结构,可以设计相应的阵列指令(array instruction),在阵列处理器上实现OLP计算模式的操作粗粒度的计算。 阵列语言中顺序描述的阵列数据和阵列语句的阵列表示,是通过存储到阵列存储器中而自动完成的。存放在阵列存储器中的阵列数据和阵列指令,是分别由指令存储器中的操作指令和调用指令控制读出,在阵列处理器上执行的。从时间上来看,操作指令/调用指令是一条接一条地顺序执行的;从空间上来看,阵列存储器中的阵列数据/阵列指令都是在单指令的控制下,有效地完成数据/操作粗粒度的时空计算。与标量计算机类似,阵列计算机的ISA也是作为更高抽象层次的接口,使阵列语言的程序设计不必了解ISA的实现细节,能从算法解决问题的方式中直觉地产生出来。成为一种确定而可预测的过程,可促进粗粒度时空计算的软件繁荣。 结束语 不断提高计算机的能力是支持数学上的infinite的技术途径之一。现在已有由十几万芯片组成的千万亿次超级计算机,但其功耗就已达到2MW左右,使机房面积比庞然大物的电子管计算机的机房面积还大10倍,约700平米。有专家认为,2017年可能实现的Eflops超级计算机的核心处理器的数量大概在1000万到1亿个之间,这就遭遇到了能源使用问题。 计算机的功耗是由芯片的功耗和芯片之间互连线的功耗组成的。为了实现航空航天图像处理计算机的小型化,早在1987年,休斯公司就开发了圆片级的硅直通技术(TSV, Through Silicon Via)。现在,IBM公司针对超级计算机的能源使用问题,也研发了TSV技术,使芯片之间的距离只有几微米,缩短了1000倍。甚至有人预测2023年到2062年之间,新型芯片和纳米技术将使超级计算机的体积缩小到一块方糖那么大,再没有各种电缆,也不需要散热[12] 。而粗粒度的阵列计算机的规则性是适合于TSV技术的。 参考文献: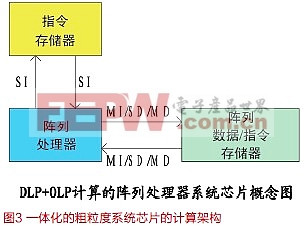
[1]Zukav G. The Dancing Wu Li Masters. New York: William Morrow and Company,1979 (中译本:像物理学家一样思考.廖世德,译.海口:海南出版社,2011)
[2]Reilly E. Milestones in Computer Science and Information Technology. America: Greenwood Publishing Group, 2003
[3]Flynn M J. Very high speed computing systems. Proceeding of IEEE, 1966, 54(12):1901-1909
[4]Marowkia A. Back to Thin-Core Massively Parallel Processors. Computer, 2011, 44(12):49-54
[5]Kahle J. The Cell Processor Architecture//Proceedings of the 38th Annual IEEE/ACM International Symposium on Microarchitecture. Barcelona, Spain, 2005:3
[6]Keckler S W, et al. GPUs and the Future of Parallel Computing. IEEE MICRO, 2011, 31(5):7-17
infinite 计算模式 DLP 201303 相关文章:
- 德州仪器(TI)——基于DLP技术的工业应用解决方案(03-24)
- 实现新一代汽车抬头显示系统(02-20)
- 基于STM32单片机的DLP驱动电路研究(04-28)
- 基于STM32单片机的DLP驱动电路的研究(02-23)
- STM32系列MCU解决方案展示(03-29)
- 基于FPGA的模拟视频转SDI的转换器设计与实现(03-21)