话说STM32F4系列的总线矩阵与访问调度

可能不少人见过STM32F4系列的内部系统架构框图。大致如下图,该图很重要,不可视而不见。
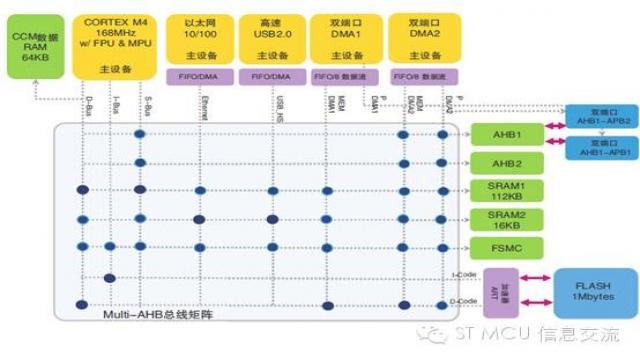
图中纵横交错的就是多层AHB总线矩阵,负责把上方黄色主设备跟右边绿色从设备互联起来。所谓AHB主设备是指CPU或DMA[通用DMA或专用DMA],由它们启动总线访问,即读写操作。那些响应主设备读写访问的设备就是AHB从设备,比如存储器、各类外设等。
因为总线矩阵的存在,使得多个主设备可以并行访问不同的从设备,增强了数据传输能力,提升了访问效率,同时也改善了功耗性能。
不过,虽然总线矩阵使得多个主设备可以并行访问不同的从设备,但在每个预定的时间内,只有一个主设备拥有总线控制权。如果有多个主设备同时出现总线请求时就得进行仲裁。所以总线矩阵里还有个AHB总线仲裁器,它保证每个时刻只有一个主设备通过总线矩阵对从设备进行访问。(注1)
为了确保每个主设备访问从设备的延迟尽量短,在总线矩阵里实行循环调度优先级方案:
• 循环调度仲裁策略使总线带宽合理分配。
• 限定最大延时。
• 循环调度以1 次传输为单位。
当多个AHB 主设备试图同时访问同一个AHB从设备时,总线矩阵仲裁器介入以解决访问冲突。在下面的例子中CPU 和DMA1 均试图访问SRAM1 以读取数据。
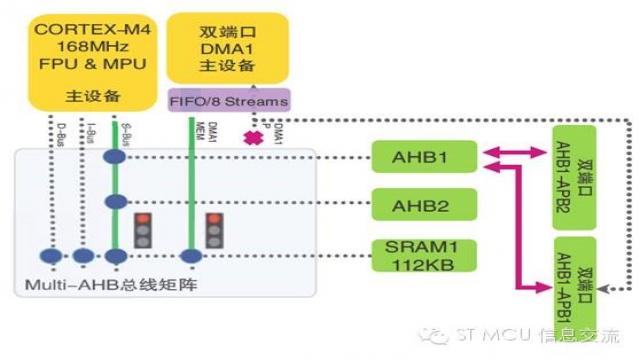
如上述示例总线访问请求同时发生的情况下,就需要总线矩阵仲裁。为了解决这种问题,需要应用循环调度策略:如果本次最后赢得总线控制权的主设备是CPU,则在下一次访问中DMA1将赢得总线控制权并首先访问SRAM1。CPU 随后方可有权访问SRAM1。
这就表明,一个主设备的传输延时取决于其它等待请求访问AHB 从设备的主设备数量。下面的例子是五个主设备试图同时访问SRAM1的情形:
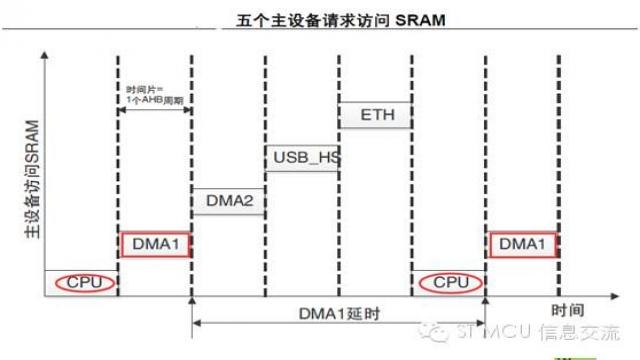
DMA1再次获得总线矩阵访问权并访问SRAM1 的延时等于其它等待请求的所有主设备的执行时间之和。
我们再来看看进行总线矩阵仲裁可能导致的DMA传输延时最差情况。
主设备DMA端口进行一次数据传输会遭遇的延时取决于其它主设备的传输类型和长度。比如,我们结合上面的DMA1 & CPU 的例子,它们并行访问SRAM。 DMA传输延时将随着CPU 数据传输事务长度而变化。如果总线访问首先给予CPU 且不是执行单次数据加载/存储,DMA 访问SRAM 的等待时间可能从一个AHB 周期(单次数据加载/ 存储时间)延长为N 个AHB 周期,这里N 为CPU 数据传输事务中数据的数量。
CPU 锁定AHB 总线以保持其访问总线的所有权,减少了多次加载/ 存储操作过程中的延时以及进入中断的延时。这提高了固件的响应能力,但是可能导致DMA 数据传输事务的延迟。
DMA1 与CPU 并行访问SRAM 的延时取决于传输类型:
• 中断(上下文保护)发起的CPU 传输:8 个AHB 周期;
• LDM/STM 指令发起的CPU 传输:14 个AHB 周期(注2)
---在多达14 个寄存器与存储器之间进行传输;
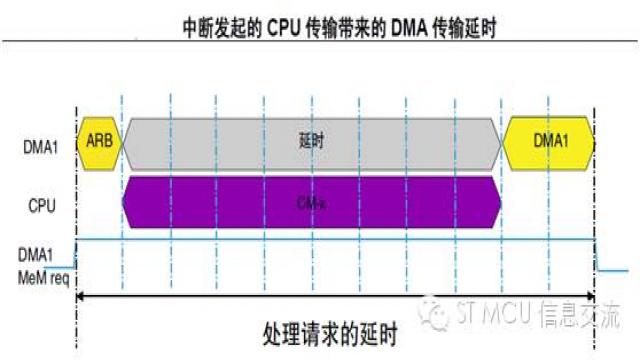
上图详细描述了一个因中断进入而导致DMA多周期传输延迟的情形。DMA 存储器端口被触发,发出存储器访问请求。经过仲裁, AHB 总线未授权DMA1 存储器端口访问,而由CPU 来访问总线。可以看到在服务DMA 请求之前有一段额外的延时。这段中断发起的CPU 传输,耗时为8 个AHB 周期。
不难理解,当同时对一个从设备进行寻址且数据传输事务长度不是一个数据单元时,其他主设备(如DMA2,USB_HS, Ethernet…)也会碰到类似情形。所以,为了提高DMA 对总线矩阵的访问性能,要尽量回避总线竞争。
以上内容主要取材于ST官方应用笔记文档AN4031的一部分。该笔记里除了上述内容外,还对STM32F2/F4的DMA传输路径、DMA传输时间的估算、DMA编程都有较为细致的介绍。我这里算是抛砖引玉,有兴趣的话可以去www.stmcu.com.cn 的设计资源区搜索下载AN4031。
(注1)并非所有主设备访问从设备都得经过总线矩阵,细心的人可能看到了有些主设备与从设备间有直通通道。细节详见STM32芯片相关参考手册。
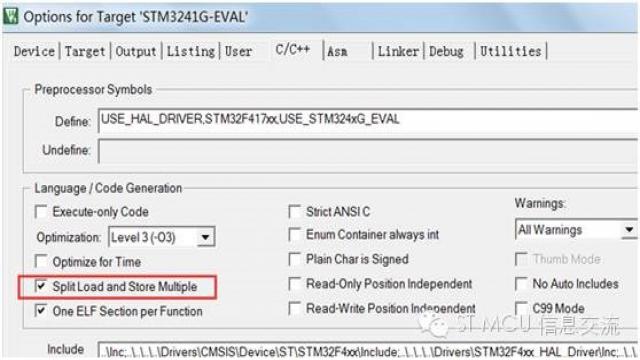
(注2) 通过配置编译器,将加载/ 存储多重指令分解为单个加载/ 存储指令,可以降低由LDM/STM 发起的传输的延时。
- 从入门到开发,STM32F407单片机全中文教程(06-04)
- STM32F407单片机使用攻略:中文手册、实战问答20篇(06-04)
- STM32F4入手调试USART,ADC-DMA(12-02)
- 接触STM32F407芯片的总结(12-01)
- 使用STM32F4XX自带数学库“arm_math.h“(11-27)
- STM32F4入门前的热身之一:认识stm32F4 Cortex-M4(11-27)