基于arm架构单片机的hadoop服务器尝试
从淘宝上面买了一个arm的单片机,上面有一颗基于ARMv7架构的单核cpu,1G内存,4G存储。但是最主要的,是上面有网卡接口,虽然是100M的,但这让构建集群成为了一个可能。另外这个比树莓派更好的是,上面有sata硬盘的接口,这样,存储的问题也可以解决。虽然我现在手里没有sata 2.5寸的硬盘,但是起码给了个想象的空间。

很小的一块板子,表就是casio的ef339,去年博客大赛的奖品,也是我唯一的一块表,而且我不担任任何公职,也不是党员,不要平我祖坟。
关于操作系统方面,cubieboard本身内置android 4.0.4,连上HDMI在电视上刷微博很爽,40寸的大pad,谁有?但是android不是我们所需要的,可以用linaro系统,for arm的ubuntu。从网上找了一个国外网友自制的linaro server版,用工具烧进TF(microSD)卡。不比自己本身的android启动速度快,这个启动速度比较慢。不过要做好心理准备,TF卡一旦烧了操作系统img上去,就再也不能当存储用了。
昨天晚上在家通过网线用apt-get install 了openjdk6,也下载好了hadoop-1.0.4。今天在公司利用午休时间配置了单机的hadoop环境。并跑了一下pi任务,结果比我想象的要好,先看几张图吧,最后写上测试数据和对比测试数据。
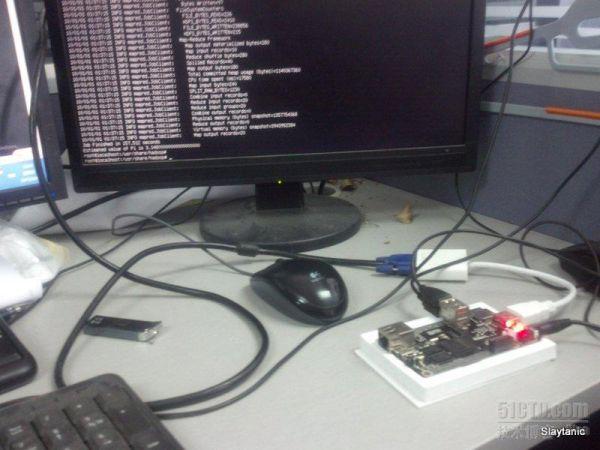
开机启动图

因为公司绑定mac,所以没有联网,懒得去找ops做mac绑定了。
测试命令,启动10个map,每map投掷100次飞镖,计算pi值。因为主要是看cpu计算能力,sd卡当存储,肯定拼不过sata硬盘的速度。下图有cpu信息和操作系统的信息。

cpu信息大图

连线图,本身采用HDMI作为显示输出,还得去找HDMI转VGA的转换头。
arm hadoop服务器大小,比中南海略大。

最后让我们回到数据上来,琢磨这种方式其实我最关心的是性价比,主要看多少颗arm v7可以顶一颗intel cpu。因为除去这一点,硬盘,内存等等都是必不可少的开销,用哪种架构都是一样的。而性价比主要就集中在cpu单价和能耗上。
在64位arm没有出来以前,就拿arm v7说事吧。
用台式机里的intel做虚拟机单核1G内存做了个对比,Hadoop pi 任务对比数据如下。
首先intel和arm的hadoop配置相同,都是hadoop官网的单机,单复制块默认配置,HEAPSIZE均设置为128M。
午休时间有限,只做了pi的测试。而且没有服务器上的虚拟机,没法测试至强CPU的性能,台式机做个大概的参考好了。
测试命令:sudo -u hadoop hadoop jar hadoop-example-1.0.4.jar pi 10 100
| 第一次 | 第二次 | 第三次 | |
| intel i3 2100 1core centos | 82.064s | 75.992s | 81.971s |
| arm v7 1core ubuntu | 173.46s | 157.165s | 168.397s |
读写存储的效率对比,分别顺序读写200M文件。
intel+机械硬盘 200M写,500M读
arm+sd卡 60M写,60M读,可见读写硬盘intel占大便宜了,不过因为没有外挂硬盘,所以也不知道arm读写效率如何。sd卡就别想了,太慢了,尽管这个SD卡已经算快的了。
且不论读写磁盘操作的差距,仅以这个作为计算能力的差距参考,可以看到,大概2-3颗arm v7可以抵的上intel i3 2100里面的一个核,那么大概12颗可以超越一颗i3 2100。i3 2100的功耗每小时大概在50-60瓦左右,而12颗arm v7的功耗每小时不到4瓦。
在我写这篇作文的时候,i3 2100 大约600多一颗,12颗arm v7大约40美元,折合起来不到300。所以无论从能耗还是价格上看,arm cpu还是具备一定优势的。只是现在64位cpu没出来,做hadoop服务器没有什么计算优势,但是拿来当webserver或者存储服务器还是绰绰有余的。
不过我个人觉得,未来用arm服务器做hadoop服务器还是极具诱惑的。无论从能耗还是采购成本上,arm都很低廉,至少在我来看,还是很性感的。
arm架构单片机hadoop服务 相关文章:
- Windows CE 进程、线程和内存管理(11-09)
- RedHatLinux新手入门教程(5)(11-12)
- uClinux介绍(11-09)
- openwebmailV1.60安装教学(11-12)
- Linux嵌入式系统开发平台选型探讨(11-09)
- Windows CE 进程、线程和内存管理(二)(11-09)