ARM处理器的浮点运算单元(FPU)
Float Point Unit,浮点运算单元是专用于浮点运算的协处理器,在计算领域,例如三角函数以及时域频域变换通常会用到浮点运算。当CPU执行一个需要浮点数运算的程序时,有三种方式可以执行:软件仿真器(浮点运算函数库)、附加浮点运算器和集成浮点运算单元。 区别于以往的ARM9处理器,目前基于ContexTM构架的ARM处理均集成了浮点运算单元。如下图Toradex ARM核心板产品所示,Nvidia TegraTM 2, TegraTM 3和 NXP/Freescale i.MX 6集成了VFPv3浮点运算单元。NXP/Freescale i.MX 7 集成了VFPv4浮点运算单元。ARM 浮点架构 (VFP) 为半精度、单精度和双精度浮点运算中的浮点操作提供硬件支持。它完全符合 IEEE 754 标准,并提供完全软件库支持,与 NEONTM 多媒体处理功能结合使用时,可增强图像应用程序的性能(如缩放、2D 和 3D 转换、字体生成和数字过滤)。
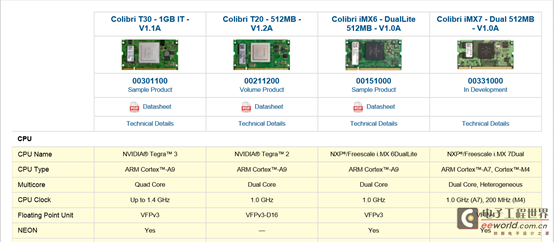
基于Toradex Colibri T20 和 Colibri/Apalis T30使用FPU
Colibri T20 核心板带有一个 VFPv3-D16 浮点运算单元(不带 NEON) ,而 Colibri T30 和Apalis T30 带有一个VFPv3-D32 (含有 NEON),通过以下的配置,将能够有效的提高浮点运输的效率,运算量愈大愈明显。
./ Windows CE 编译器的浮点优化
在 Visual Studio 2008环境中,你可以直接为上述核心板生成含有浮点处理器加速的代码,请在您的工程中按照以下步骤进行:
对于 WinCE 6:
打开 "Project" 菜单并选择 "Properties".
选择 "Configuration Properties : C/C++ : Advanced".
改变 "Enable floating point emulation" 为 "No".
改变 "Compile for architecture"为 "ARM5T /QRarch5t".
选择 "Configuration Properties : C/C++ : Command Line : Additional Options".
添加 "/QRfpe-"to the set of options.
关闭对话框并选择"OK".
对于 WinCE 7:
打开"Project"菜单并选择"Properties".
选择 "Configuration Properties : C/C++ : Command Line : Additional Options".
添加 "/QRfpe-" to the set of options.
关闭对话框并选择"OK".
请注意,这些功能在Visual Studio 2005 不能被实现。
./ 性能比较举例
通过Mark Riordan benchmark program我们做了一个简单c代码的性能比较程序。我们计算了这个循环所需要的时间如下,时间越短性能越好:
Module | Time | Compile Settings |
Colibri PXA320 806MHz | about 3400 ms | VS08 WinCE 6 Release 默认配置. |
Colibri T20 1.0GHz | about 545 ms | VS08 WinCE 6 Debug默认配置. |
Colibri T20 1.0GHz | about 315 ms | VS08 WinCE 6 Release默认配置. |
Colibri T20 1.0GHz | about 80 ms | VS08 WinCE 6/7 Release settings编译器的浮点优化打开 |
Colibri T20 1.0GHz | about 80 ms | Linux optimized GCC settings编译器的浮点优化. |
Colibri T30 1.3GHz | about 60 ms | VS08 WinCE 6/7 Release settings编译器的浮点优化打开 |
ARM处理器浮点运算单元FP 相关文章:
- Windows CE 进程、线程和内存管理(11-09)
- RedHatLinux新手入门教程(5)(11-12)
- uClinux介绍(11-09)
- openwebmailV1.60安装教学(11-12)
- Linux嵌入式系统开发平台选型探讨(11-09)
- Windows CE 进程、线程和内存管理(二)(11-09)