ARM汇编编程基础之二-流水线对PC值的影响
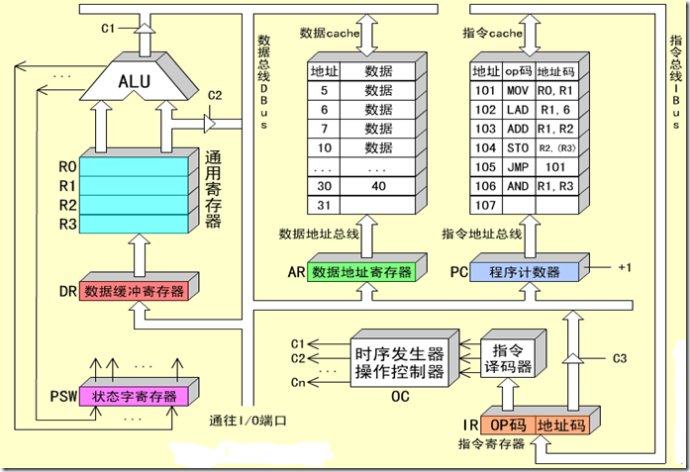
从上图中我们看到CPU内部有3个主要组成部分:指令寄存器,指令译码器,指令执行单元(包括ALU和通用寄存器组)。
CPU在执行1条指令的时候,主要有3个步骤:取指(将指令从内存或指令cache中取入指令寄存器);译码(指令译码器对指令寄存器中的指令进行译码操作,从而辨识出该指令是要执行add,或是sub,或是其它操作,从而产生各种时序控制信号);执行(指令执行单元根据译码的结果进行运算并保存结果)
现在我们假设一下:CPU串行执行程序(即:执行完1条指令后,再执行下一条指令);指令执行的3个步骤中每个步骤都耗时1秒;整个程序共10条指令。那么,这个程序总的执行时间是多少呢?显然,是30秒。但这个结果令我们非常不满意,因为它太慢了。有没有办法让它座上京津高铁提速3倍呢?当然有!仔细观察上图,我们发现:取指阶段占用的CPU硬件是指令通路和指令寄存器;译码阶段占用的CPU硬件是指令译码器;执行阶段占用的CPU硬件是指令执行单元和数据通路。三者占用的CPU硬件完全不同,这样就使得如下的操作得以进行:在对第1条指令进行译码的时候,可以同时对第2条指令进行取指操作;在对第1条指令进行执行的时候,可以同时对第2条指令进行译码操作,对第3条指令进行取指操作。显然,这样就可以将该程序的运行总时间从30秒缩减为12秒,提速近3倍。上面所述并行运行指令的方式就被称为流水线操作。可见:流水线操作的本质是利用指令运行的不同阶段使用的CPU硬件互不相同,并发的运行多条指令,从而提高时间效率。
流水线的引入,的确提高了CPU运行指令的时间效率,但却为我们的汇编程序编写引入了新的问题。请看下面的分析:
寄存器PC的值是即将被取指的指令的地址,正常情况下,在该条指令被取入CPU后执行期间,PC的值保持不变,在该条指令执行完成的时间点上,硬件会自动将PC的值增加一个单位的大小,这样PC就指向了下一条将被取指和执行的指令。而在引入流水线后,PC值的情况发生了变化,假定第1条指令的内存地址为X,则在时刻T,PC的值变为X,并在时刻T至时刻T+1期间维持不变;在时刻T+1,PC的值变为X+1个单位,并在时刻T+1至时刻T+2期间维持不变;在时刻T+2,PC的值变为X+2个单位,并在时刻T+2至时刻T+3期间维持不变;在时刻T+3,PC的值将变为X+3个单位。由此可见,在第1条指令的执行阶段,PC的值不再是该指令在内存中的位置,而是该指令在内存中的位置+2个单元。对于ARM指令集而言,每条指令的长度为32bit,占4byte,所以1条指令在内存中需要4byte存储。因此,我们的结论是:
指令执行时,PC的值 = 当前正在执行指令在内存中的地址 + 8
请牢记以上结论。虽然目前我们并不明白这个结论有何作用,但在后续的课程中,特别是通过查看反汇编代码的方式理解伪指令和编译器行为的时候,这个结论将会很有帮助。
最后说明一点:其实ARM现在的CPU的流水线级数早已经突破了3级。但我仍然以3级流水线来进行讲解,是因为:1、较之多级流水线,3级流水线最简单,因此也最便于初学者理解;2、虽然存在多种级别的流水线,但ARM出于统一和前后兼容的考虑,PC的值 = 当前正在执行指令在内存中的地址 + 8这个结论在所有的流水线级别上都是相同的。作为编程人员而言,我们只需要知道这个结论即可。
致谢:感谢安博中程的Michael Tang为本文制作了示意图。
ARM汇编编程流水线PC 相关文章:
- Windows CE 进程、线程和内存管理(11-09)
- RedHatLinux新手入门教程(5)(11-12)
- uClinux介绍(11-09)
- openwebmailV1.60安装教学(11-12)
- Linux嵌入式系统开发平台选型探讨(11-09)
- Windows CE 进程、线程和内存管理(二)(11-09)