基于ARM的嵌入式系统程序开发要点
时间:12-02
来源:互联网
点击:
因为嵌入式应用领域的多样性,每一个系统都具有各自的特点。在进行系统程序设计的时候,一定要进行具体分析,充分利用这些特点,扬长避短。
结合ARM架构本身的一些特点,在这里讨论几个常见的要点。
1.ARM 还是 Thumb?
在讨论 ARM 还是 Thumb 之前,先说明 ARM 内核型号和 ARM 结构体系之间的区别和联系。
如图-1所示,ARM 的结构体系主要从版本 4 开始,发展到了现在的版本 6,结构体系的变化,对程序员而言最直接的影响就是指令集的变化。结构体系的演变意味着指令集的不断扩展,值得庆幸的是 ARM 结构体系的发展一直保持了向上兼容,不会造成老版本程序在新结构体系上的不兼容。
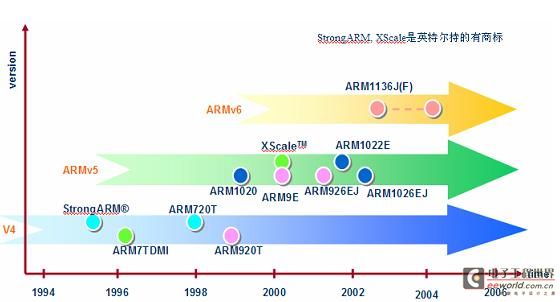
图-1 ARM 结构体系和处理器家族的演变发展
在图中的横坐标上,显示了每一个体系结构上都含有众多的处理器型号,这是在同一体系结构下根据硬件配置和存储器系统的不同而作的进一步细分。 需要注意的是通常我们用来区分 ARM 处理器家族的 ARM7、ARM9 或 ARM10,可能跨越不同的体系结构。
在ARM的体系结构版本4与5中, 还可以再细分出几个小的扩展版本: V4T、V5TE和V5TEJ,其区别如图-2中所示,这些后缀名也反映在各自拥有的处理器型号上面,可以进行直观的分辨。V6 结构体系因为包含了以前版本的所有特性,所以不需要再进行分类。
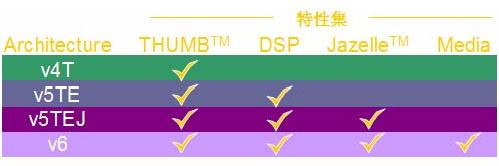
图-2 结构体系特征
上面介绍了整个 ARM 处理器家族的分布,主要是说明在一个特定的平台上编写程序的时候,一定要先弄清楚目标的特性和一些细微的差别,特别是需要具体优化特征的时候。
从 ARM 体系结构 V4T 以后,最大的变化是增加了一套 16 位的指令集——Thumb。到底在一个具体应用中要否采用 Thumb呢?首先我们来分析一下 ARM和 Thumb 各自的特点和优势。先看下面一张性能分析图:
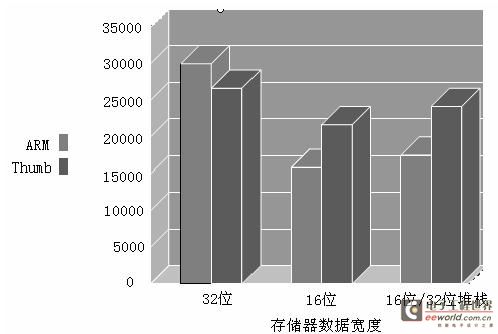
图-3 ARM 和 Thumb指令集的比较
图中的纵坐标是测试向量 Dhrystone 在 20MHz 频率下运行 1 秒钟的结果, 其值越大表明性能越好;横坐标是系统存储器系统的数据总线宽度。结果表明:
(a) 当系统具有32 位的数据总线宽度时,ARM 比 Thumb有更好的性能表现。
(b) 当系统的数据总线宽度小于32 位时,Thumb比 ARM 的性能更好。
由此可见, 并不是32位的ARM指令集性能一定强于16位的Thumb指令集,要具体情况具体分析。考察个中的原因,其实不难发现,因为当在一个 16 位存储器系统里面取1 条 32位指令的时候,需要耗费2 个存储器访问周期;比之 32位的系统,其速度正好大概下降一半左右。而 16 位指令在 32 位存储器系统或16 位存储器系统里的表现基本相同。正是存储器造成的系统瓶颈导致了这个有趣的差别。
除了在窄带宽系统里面的性能优势外, Thumb 指令的另外一个好处是代码尺寸。同样一段 C 代码,用 Thumb 指令编译的结果,其长度大约只占 ARM 编译结果的 65%左右,可以明显地节省存储器空间。在大多数情况下,紧凑的代码和窄带宽的存储器系统,还会带来功耗上的优势。
当然,如果在 32 位的系统上面,并且对系统性能要求很高的情况下,ARM是一个更好的选择。毕竟在这种情况下,只有 32 位的指令集才能完全发挥 32位处理器的优势来。
因此,选择 ARM 还是 Thumb,需要从存储器开销和性能要求两方面加以权衡考虑。
2.堆栈的分配
在图-3 中,横坐标上还有一种情况,就是 16 位的存储器宽度,但是堆栈空间是 32 位的。这种情况下无论 ARM 还是 Thumb,其性能表现都比单纯的 16 位存储器系统情况下要好。这是因为 ARM 和 Thumb 其指令集虽然分 32 位和 16位,但是堆栈全部是采用32 位的。因此在 16 位堆栈和 32 位堆栈的不同环境下,其性能当然都会相差很多。这种差别还跟具体的应用程序密切相关,如果一个程
序堆栈的使用频率相当高,则这种性能差异很大;反之则要小一些。
在基于 ARM 的系统中,堆栈不仅仅被用来进行诸如函数调用、中断响应等时候的现场保护,还是程序局部变量和函数参数传递(如果大于4个)的存储空间。所以出于系统整体性能考虑,要给堆栈分配相对访问速度最快、数据宽度最大的存储器空间。
一个嵌入式系统通常存在多种多样的存储器类型。设计的时候一定要先清楚每一种存储器的访问速度,地址分配和数据线宽度。然后根据不同程序和目标模块对存储器的不同要求进行合理分配,以期达到最佳配置状态。
3.ROM 还是 RAM 在 0 地址处?
显然当系统刚启动的时候,0 地址处肯定是某种类型的 ROM,里面存储了系统的启动代码。 但是很多灵活的系统设计中, 0 地址处的存储器类型是可映射的。也就是说,可以通过软件的方法,把别的存储器(主要是快速的 RAM)分配以0 起始的地址。
这种做法的最主要目的之一是提高系统对中断的反应速度。因为每一个中断发生的时候,ARM 都需要从 0 地址处的中断向量表开始其中断响应流程,显然把中断向量表放在 RAM 里,比放在 ROM 里有更快的访问速度。因此,如果系统提供了这一类的地址重映射功能,软件设计者一定要加以利用。
下面是一个典型的经过 0 地址重映射之后的存储空间分布图,注意尽可能把速度要求最高的部分放置在系统里面访问速度最快、带宽最宽的 RAM 里面。

图-4 系统存储器分布的实例
4.存储器地址重映射(memory remap)
存储器地址重映射是当前很多先进控制器所具有的功能。在上一节中已经提到了 0 地址处存储器重映射的例子,简而言之,地址重映射就是可以通过软件配置来改变一块存储器物理地址的一种机制或方法。
当一段程序对运行自己的存储器进行重映射的时候,需要特别注意保证程序执行流程在重映射前后的承接关系。下面是一种典型的存储器地址重映射情况:
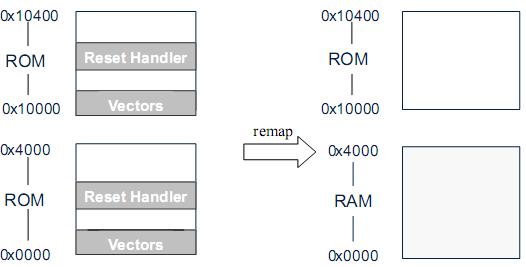
图-5 存储器重映射举例 1
系统上电后的缺省状态是 0地址上放有 ROM,这块 ROM 有两个地址:从0起始和从0x10000 起始,里面存储了初始化代码。当进行地址 remap以后,从 0起始的地址被定向到了 RAM 上,ROM 则只保留有唯一的从 0x10000 起始的地址了。
如果存储在 ROM 里的 Reset_Handler 一直在0 – 0x4000的地址上运行,则当执行完remap以后,下面的指令将从RAM 里预取,必然会导致程序执行流程的中断。根据系统特点,可以用下面的办法来解决这个问题:
(1) 上电后系统从 0 地址开始自动执行,设计跳转指令在 remap 发生前使 PC指针指向0x10000 开始的 ROM 地址中去,因为不同地址
指向的是同一块ROM,所以程序能够顺利执行。
(2) 这时候 0 - 0x4000的地址空间空闲, 不被程序引用, 执行remap后把 RAM引进。因为程序一直在 0x10000 起始的 ROM 空间里
运行,remap 对运行流程没有任何影响。
(3) 通过在 ROM 里运行的程序,对 RAM 进行相应的代码和数据拷贝,完成应用程序运行的初始化。
下面是一段实现上述步骤的例程:
-------------------------------------------------------------------------------------------------------
ENTRY
;启动时,从 0 开始,设法跳转到“真”的ROM 地址(0x10000 开始的空间里)
LDR pc, =start
;insert vector table here
…
Start ;Begin of Reset_Handler
; 进行 remap设置
LDR r1, =Ctrl_reg ;假定控制 remap的寄存器
LDR r0, [r1]
ORR r0, r0, #Remap_bit ;假定对控制寄存器进行 remap设置
STR r0, [r1]
;接下去可以进行从 ROM 到 RAM 的代码和数据拷贝
-------------------------------------------------------------------------------------------------------
除此之外,还有另外一种常见的remap方式,如下图:
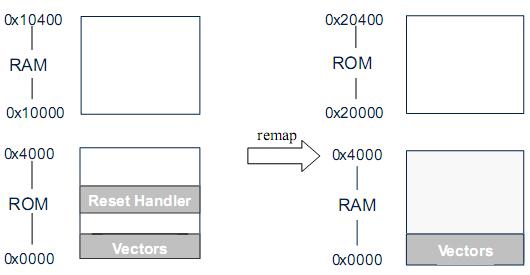
图-6 存储器重映射举例 2
原来 RAM 和 ROM 各有自己的地址, 进行重映射以后 RAM 和 ROM 的地址都发生了变化,这种情况下,可以采用以下的方案:
(1) 上电后,从 0 地址的 ROM 开始往下执行。
(2) 根据映射前的地址,对 RAM 进行必要的代码和数据拷贝。
(3) 拷贝完成后,进行 remap操作。
(4) 因为 RAM 在 remap 前准备好了内容,使得 PC 指针能继续在 RAM 里取到正确的指令。
不同的系统可能会有多种灵活的 remap方案,根据上面提到的两个例子,可以总结出最根本的考虑是: 要使程序指针在 remap以后能继续往下得到正确的指令。
5. 根据目标存储器系统分散加载映像(scatterloading)
Scatterloading 文件是 ARM 的工具链里面的一个特性,作为程序编译过程中给连接器使用的一个参数,用来指定最终生成的目标映像文件运行时的分布状态。如果用户程序映像只是如图7 所示的最简状态,所有的可执行代码都集合放置在一起,那么可以不使用 Scatterloading 文件,直接用连接器的命令行选项就能够完成设置:
RO = 0x00000:表示映像的第一条指令开始地址;
RW = 0x10000:表示变量区的起始地址,变量区一定要位于 RAM 区。
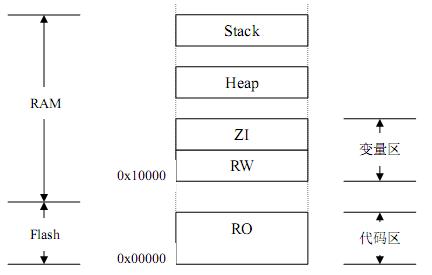
图-7 简单的映像分布举例
但是一个复杂的系统可能会把映像分割成几个部分。如图 8,系统中存在多种类型的存储器,不能的代码部分根据执行性能优化的考虑分布与不同的地方。

图-8 复杂的映像分布举例
这时候不能通过简单的 RO、RW 参数来完成实现上述配置,就要用到scatterloading 文件了。在 scatterloading文件里,可以给编译出来的各个目标模块指定运行地址,下面的例子是针对图8 的。
FLASH 0x20000 0x8000
{
FLASH 0x20000 0x8000
{
init.o (Init, +First)
* (+RO)
}
32bitRAM 0x0000
{
vectors.o (Vect, +First)
handlers.o (+RO)
}
STACK 0x1000 UNINIT
{
stackheap.o (stack)
}
:
:
16bitRAM 0x10000
{
* (+RW,+ZI)
}
HEAP 0x15000 UNINIT
{
stackheap.o (heap)
}
}
关于 scatterloading文件的详细语法,请参阅 ARM 公司的相关手册。
引证文献
1. 辛鑫.蒙建波.罗根 由 C到ARM汇编指令及程序优化 [期刊论文] -单片机与嵌入式系统应用2007(06)
2. 杨志强 嵌入式系统设计与发展 [期刊论文] -青海师范大学学报(自然科学版)2005(03)
3. 邓海峰.余慧英.袁可风 一种嵌入式图像处理平台的设计与实现 [期刊论文] -计算机应用2005(z1)
4. 刘志勇 基于ARM的无线视频传输硬件系统的初步研究与开发 [学位论文] 硕士2005
5. 刘峰雷 ARM9在新一代元件参数分析仪中的应用 [学位论文] 硕士2005
6. 王雷 基于ARM微处理器的应用研究 [学位论文] 硕士2005
7. 韩冰 车流量检测信号处理系统设计 [学位论文] 硕士2005
结合ARM架构本身的一些特点,在这里讨论几个常见的要点。
1.ARM 还是 Thumb?
在讨论 ARM 还是 Thumb 之前,先说明 ARM 内核型号和 ARM 结构体系之间的区别和联系。
如图-1所示,ARM 的结构体系主要从版本 4 开始,发展到了现在的版本 6,结构体系的变化,对程序员而言最直接的影响就是指令集的变化。结构体系的演变意味着指令集的不断扩展,值得庆幸的是 ARM 结构体系的发展一直保持了向上兼容,不会造成老版本程序在新结构体系上的不兼容。
图-1 ARM 结构体系和处理器家族的演变发展
在图中的横坐标上,显示了每一个体系结构上都含有众多的处理器型号,这是在同一体系结构下根据硬件配置和存储器系统的不同而作的进一步细分。 需要注意的是通常我们用来区分 ARM 处理器家族的 ARM7、ARM9 或 ARM10,可能跨越不同的体系结构。
在ARM的体系结构版本4与5中, 还可以再细分出几个小的扩展版本: V4T、V5TE和V5TEJ,其区别如图-2中所示,这些后缀名也反映在各自拥有的处理器型号上面,可以进行直观的分辨。V6 结构体系因为包含了以前版本的所有特性,所以不需要再进行分类。
图-2 结构体系特征
上面介绍了整个 ARM 处理器家族的分布,主要是说明在一个特定的平台上编写程序的时候,一定要先弄清楚目标的特性和一些细微的差别,特别是需要具体优化特征的时候。
从 ARM 体系结构 V4T 以后,最大的变化是增加了一套 16 位的指令集——Thumb。到底在一个具体应用中要否采用 Thumb呢?首先我们来分析一下 ARM和 Thumb 各自的特点和优势。先看下面一张性能分析图:
图-3 ARM 和 Thumb指令集的比较
图中的纵坐标是测试向量 Dhrystone 在 20MHz 频率下运行 1 秒钟的结果, 其值越大表明性能越好;横坐标是系统存储器系统的数据总线宽度。结果表明:
(a) 当系统具有32 位的数据总线宽度时,ARM 比 Thumb有更好的性能表现。
(b) 当系统的数据总线宽度小于32 位时,Thumb比 ARM 的性能更好。
由此可见, 并不是32位的ARM指令集性能一定强于16位的Thumb指令集,要具体情况具体分析。考察个中的原因,其实不难发现,因为当在一个 16 位存储器系统里面取1 条 32位指令的时候,需要耗费2 个存储器访问周期;比之 32位的系统,其速度正好大概下降一半左右。而 16 位指令在 32 位存储器系统或16 位存储器系统里的表现基本相同。正是存储器造成的系统瓶颈导致了这个有趣的差别。
除了在窄带宽系统里面的性能优势外, Thumb 指令的另外一个好处是代码尺寸。同样一段 C 代码,用 Thumb 指令编译的结果,其长度大约只占 ARM 编译结果的 65%左右,可以明显地节省存储器空间。在大多数情况下,紧凑的代码和窄带宽的存储器系统,还会带来功耗上的优势。
当然,如果在 32 位的系统上面,并且对系统性能要求很高的情况下,ARM是一个更好的选择。毕竟在这种情况下,只有 32 位的指令集才能完全发挥 32位处理器的优势来。
因此,选择 ARM 还是 Thumb,需要从存储器开销和性能要求两方面加以权衡考虑。
2.堆栈的分配
在图-3 中,横坐标上还有一种情况,就是 16 位的存储器宽度,但是堆栈空间是 32 位的。这种情况下无论 ARM 还是 Thumb,其性能表现都比单纯的 16 位存储器系统情况下要好。这是因为 ARM 和 Thumb 其指令集虽然分 32 位和 16位,但是堆栈全部是采用32 位的。因此在 16 位堆栈和 32 位堆栈的不同环境下,其性能当然都会相差很多。这种差别还跟具体的应用程序密切相关,如果一个程
序堆栈的使用频率相当高,则这种性能差异很大;反之则要小一些。
在基于 ARM 的系统中,堆栈不仅仅被用来进行诸如函数调用、中断响应等时候的现场保护,还是程序局部变量和函数参数传递(如果大于4个)的存储空间。所以出于系统整体性能考虑,要给堆栈分配相对访问速度最快、数据宽度最大的存储器空间。
一个嵌入式系统通常存在多种多样的存储器类型。设计的时候一定要先清楚每一种存储器的访问速度,地址分配和数据线宽度。然后根据不同程序和目标模块对存储器的不同要求进行合理分配,以期达到最佳配置状态。
3.ROM 还是 RAM 在 0 地址处?
显然当系统刚启动的时候,0 地址处肯定是某种类型的 ROM,里面存储了系统的启动代码。 但是很多灵活的系统设计中, 0 地址处的存储器类型是可映射的。也就是说,可以通过软件的方法,把别的存储器(主要是快速的 RAM)分配以0 起始的地址。
这种做法的最主要目的之一是提高系统对中断的反应速度。因为每一个中断发生的时候,ARM 都需要从 0 地址处的中断向量表开始其中断响应流程,显然把中断向量表放在 RAM 里,比放在 ROM 里有更快的访问速度。因此,如果系统提供了这一类的地址重映射功能,软件设计者一定要加以利用。
下面是一个典型的经过 0 地址重映射之后的存储空间分布图,注意尽可能把速度要求最高的部分放置在系统里面访问速度最快、带宽最宽的 RAM 里面。
图-4 系统存储器分布的实例
4.存储器地址重映射(memory remap)
存储器地址重映射是当前很多先进控制器所具有的功能。在上一节中已经提到了 0 地址处存储器重映射的例子,简而言之,地址重映射就是可以通过软件配置来改变一块存储器物理地址的一种机制或方法。
当一段程序对运行自己的存储器进行重映射的时候,需要特别注意保证程序执行流程在重映射前后的承接关系。下面是一种典型的存储器地址重映射情况:
图-5 存储器重映射举例 1
系统上电后的缺省状态是 0地址上放有 ROM,这块 ROM 有两个地址:从0起始和从0x10000 起始,里面存储了初始化代码。当进行地址 remap以后,从 0起始的地址被定向到了 RAM 上,ROM 则只保留有唯一的从 0x10000 起始的地址了。
如果存储在 ROM 里的 Reset_Handler 一直在0 – 0x4000的地址上运行,则当执行完remap以后,下面的指令将从RAM 里预取,必然会导致程序执行流程的中断。根据系统特点,可以用下面的办法来解决这个问题:
(1) 上电后系统从 0 地址开始自动执行,设计跳转指令在 remap 发生前使 PC指针指向0x10000 开始的 ROM 地址中去,因为不同地址
指向的是同一块ROM,所以程序能够顺利执行。
(2) 这时候 0 - 0x4000的地址空间空闲, 不被程序引用, 执行remap后把 RAM引进。因为程序一直在 0x10000 起始的 ROM 空间里
运行,remap 对运行流程没有任何影响。
(3) 通过在 ROM 里运行的程序,对 RAM 进行相应的代码和数据拷贝,完成应用程序运行的初始化。
下面是一段实现上述步骤的例程:
-------------------------------------------------------------------------------------------------------
ENTRY
;启动时,从 0 开始,设法跳转到“真”的ROM 地址(0x10000 开始的空间里)
LDR pc, =start
;insert vector table here
…
Start ;Begin of Reset_Handler
; 进行 remap设置
LDR r1, =Ctrl_reg ;假定控制 remap的寄存器
LDR r0, [r1]
ORR r0, r0, #Remap_bit ;假定对控制寄存器进行 remap设置
STR r0, [r1]
;接下去可以进行从 ROM 到 RAM 的代码和数据拷贝
-------------------------------------------------------------------------------------------------------
除此之外,还有另外一种常见的remap方式,如下图:
图-6 存储器重映射举例 2
原来 RAM 和 ROM 各有自己的地址, 进行重映射以后 RAM 和 ROM 的地址都发生了变化,这种情况下,可以采用以下的方案:
(1) 上电后,从 0 地址的 ROM 开始往下执行。
(2) 根据映射前的地址,对 RAM 进行必要的代码和数据拷贝。
(3) 拷贝完成后,进行 remap操作。
(4) 因为 RAM 在 remap 前准备好了内容,使得 PC 指针能继续在 RAM 里取到正确的指令。
不同的系统可能会有多种灵活的 remap方案,根据上面提到的两个例子,可以总结出最根本的考虑是: 要使程序指针在 remap以后能继续往下得到正确的指令。
5. 根据目标存储器系统分散加载映像(scatterloading)
Scatterloading 文件是 ARM 的工具链里面的一个特性,作为程序编译过程中给连接器使用的一个参数,用来指定最终生成的目标映像文件运行时的分布状态。如果用户程序映像只是如图7 所示的最简状态,所有的可执行代码都集合放置在一起,那么可以不使用 Scatterloading 文件,直接用连接器的命令行选项就能够完成设置:
RO = 0x00000:表示映像的第一条指令开始地址;
RW = 0x10000:表示变量区的起始地址,变量区一定要位于 RAM 区。
图-7 简单的映像分布举例
但是一个复杂的系统可能会把映像分割成几个部分。如图 8,系统中存在多种类型的存储器,不能的代码部分根据执行性能优化的考虑分布与不同的地方。
图-8 复杂的映像分布举例
这时候不能通过简单的 RO、RW 参数来完成实现上述配置,就要用到scatterloading 文件了。在 scatterloading文件里,可以给编译出来的各个目标模块指定运行地址,下面的例子是针对图8 的。
FLASH 0x20000 0x8000
{
FLASH 0x20000 0x8000
{
init.o (Init, +First)
* (+RO)
}
32bitRAM 0x0000
{
vectors.o (Vect, +First)
handlers.o (+RO)
}
STACK 0x1000 UNINIT
{
stackheap.o (stack)
}
:
:
16bitRAM 0x10000
{
* (+RW,+ZI)
}
HEAP 0x15000 UNINIT
{
stackheap.o (heap)
}
}
关于 scatterloading文件的详细语法,请参阅 ARM 公司的相关手册。
引证文献
1. 辛鑫.蒙建波.罗根 由 C到ARM汇编指令及程序优化 [期刊论文] -单片机与嵌入式系统应用2007(06)
2. 杨志强 嵌入式系统设计与发展 [期刊论文] -青海师范大学学报(自然科学版)2005(03)
3. 邓海峰.余慧英.袁可风 一种嵌入式图像处理平台的设计与实现 [期刊论文] -计算机应用2005(z1)
4. 刘志勇 基于ARM的无线视频传输硬件系统的初步研究与开发 [学位论文] 硕士2005
5. 刘峰雷 ARM9在新一代元件参数分析仪中的应用 [学位论文] 硕士2005
6. 王雷 基于ARM微处理器的应用研究 [学位论文] 硕士2005
7. 韩冰 车流量检测信号处理系统设计 [学位论文] 硕士2005
ARM系统程序开发要 相关文章:
- Windows CE 进程、线程和内存管理(11-09)
- RedHatLinux新手入门教程(5)(11-12)
- uClinux介绍(11-09)
- openwebmailV1.60安装教学(11-12)
- Linux嵌入式系统开发平台选型探讨(11-09)
- Windows CE 进程、线程和内存管理(二)(11-09)