音乐识别锁软硬件完整方案
波。因为最高基音频率为450Hz,所以将上限频率设为900Hz可以保留语音的一、二次谐波,下降频率为60Hz是为了滤除50Hz的电源干扰。
以上几种方法都是对语音信号本身求相应的函数。本系统采用的基音估计方法是:首先对带通滤波后的短时语音信号进行线性预测,求取预测残差;再对残差信号求自相关函数,找出第一最大峰值点的位置,即得到该段语音的基音估计值。实验表明,通过残差求取的基音轨迹比直接通过语音求取的基音轨迹效果更好,如图2所示。图2中横坐标为语音帧数,纵坐标为8000/f,其中f为基音频率。
5,模式匹配
目前针对各种特征参数提出的模式匹配方法的研究越来越深入。典型的方法有:矢量量化方法、高斯混合模型方法、隐马尔可夫模型方法、动态时间规整(DTW)方法和人工神经网络方法。
这些方法都有各自的优点和缺点。其中DTW算法对于较长音乐的识别,模板匹配运算量太大,但对短音乐(有效音乐长度低于3s)的识别既简单又有效,而且并不比其他方法识别率低,特别适用于短语音、与文本有关的音乐识别系统。本系统采用端点松驰两点的(DTW)算法,端点松驰引起的计算量增加并不大,还可以放松对端点检测的精度要求。
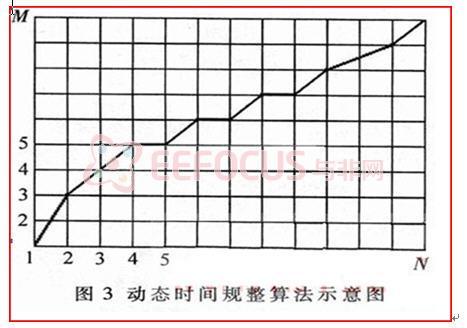
动态时间规整(DTW)算法基于动态规划的思想,解决了音乐不同时期音质长短、音速不一样的匹配问题。DTW算法用于计算两个长度不同的模板之间的相似程度,用失真距离表示。假设测试模板和参考模板分别用T和R表示,按时间顺序含有N帧和M帧的语音参数(本系统为12维LPCC参数),失真距离越小,表示T、R越接近。把测试模板的各个帧号n=1~N在一个二维直角坐标系中的横轴上标出,把参考模板的各帧号m=1~M在纵轴上标出,如图3所示。通过这些表示帧号的整数坐标画出纵横线即形成网络,网格中的每一个交叉点(n,m)表示测试模板中某一帧与参考模式中某一帧的交会点,对应两个向量的欧氏距离。DTW算法可以归结为寻找一条通过此网格中若干交叉点的路径,使得该路径上节点的距离和(即失真距离)为最小。对于端点松弛的情况,路径搜索原理相同,只是增加了搜索路径。
(二) 硬件系统
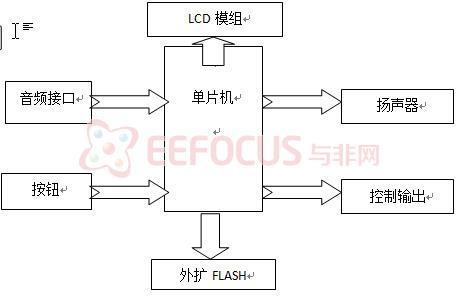
音纹电子门锁系统的核心是音乐识别模块。包括按键输入、音乐信号采集、音乐信号处理、FLASH存储扩展、扬声器输出、控制输出以及LCD模组等。音乐识别模型的原理框图如图4所示。其核心为音乐信号处理。
音乐识别模块各组成部分完成的功能如下:
(1)按键输入部分:共有数字键、训练键、删除键、确认键和取消键等按键,用于密码输入时的各项操作。其中训练键为隐藏部分,在外部无法直接看到。采用不同的按键输入,按键顺序随时改变,因此,从某种意义上来讲又成为了一种密码。
(2)语音信号采集部分:特定语音芯片
(3)FLASH存储扩展部分:用于存储音乐的个性特征参数参考模板。
(4)扬声器输出部分:扬声器
(5)控制输出部分:用单片机I/O口控制门锁控制电机。
(6)LCD模组部分:用以显示系统的工作状态,以及操作提示。
(三)工作模式
音乐识别模块有三种工作模式:训练模式、认证模式,这两种模式都可通过工作模式按键选择。
(1)训练模式,音乐的声音通过音频线进入语音信号采集前端电路。第一次语音输入时,由单片机对采集的语音信号进行处理,提取音乐的个性特征参数,并存储到外扩的FLASH内,形成音乐特征参数模板。每个密码可以进行三次训练,第二语音输入时,提取的个数特征参数与由第一次语音输入形成的特征参数模板进行匹配,在匹配距离小于模板更新阈值时,将音乐特征参数模板更新为两次特征参数的平均值。第三次语音输入时,提取的个性特征参数与由第一、二次语音输入形成的特征参数模板进行匹配,在匹配距离小于模板更新阈值时,将音乐特征参数模板更新为三次特征参数的平均值,形成最后的该音乐的特征参数模板。训练模式只有识别程序的拥有者可见。
(2)认证模式,同样通过音频线录入音乐的声音,再由单片机对采集的语音信号进行处理,将提取的音乐特征参数与存储在外扩FLASH内的特征参数模板进行匹配,匹配距离小于认证阈值时,通过认证;然后再判断匹配距离是否小于认证模式下的模板更新阈值,决定是否对模板进行更新。
另外,由于单片机的可重复编程功能,如果有必要,此音纹识别系统可以再加入密码输入等安全认证措施。但考虑到本音纹识别本身具有较高的安全性,加入密码输入没有太大的意义,在这里我们并没有加入此功能。
(四)总结
音纹识别不仅使用方便,安全,而且还具有以下特性:用户接受程度高,由于不涉及隐私问题,用户无任何心理障碍;声音输入设备造价低廉,
- LPC2292的μC/OS-II硬件抽象层构建(04-26)
- 基于WinCE6.0的LPC3250串口驱动程序开发(01-05)
- 基于DSP芯片TMS320C5409的语音实时变速系统(07-23)
- 基于ARM的低功耗语音去噪系统设计(11-13)
- 基于模型的无刷电机控制代码快速生成(01-24)
- 图解ADS+JLINK调试ARM(03-01)