Cortex-M3内核浮点型运算的研究与实现
摘要:通过分析Cortex-M3内核的结构与浮点型格式,充分利用Cortex-M3内核中的分支预测、单周期乘法、硬件除法等众多功能强大的特性,使用Thumb-2指令集实现了单精度浮点型的加、减、乘、除与比较运算,并给出了加减法运算的流程图和除法运算的源程序。
关键词:Cortex-M3内核;浮点型;速度
引言
在一些较为复杂的运算中,经常需要处理取值范围大、精度高的浮点型数据。但一般的低端嵌入式内核中没有浮点型硬件运算器,因此处理语音信号等数据比较困难。本文提出了一种基于Cortex-M3内核的浮点型运算的处理方法。
1 Thumb-2指令集与COrtex-M3内核结构
Thumb-2指令集具有以下优点:许多指令(包括乘法相关指令、突破性的32位硬件除法指令等)都是单周期的,并且位段处理指令取指都按32位处理。
Cortex-M3是一个32位处理器内核,采用哈佛结构,拥有独立的指令总线和数据总线,可以让取指与数据访问并行不悖。它具有如下特点:功耗低,有睡眠、停机和待机3种模式;实时性好;响应中断快,而且响应中断所需的周期数是确定的;采用Thumb-2指令集,使得代码
密度和执行效率更高。
2 浮点数的格式
IEEE的浮点型数据标准规定,浮点数具有单精度(4字节)、双精度(8字节)和扩展精度(10字节)三种浮点型格式。在实际的应用中,使用最多的是单精度浮点数,格式如下:
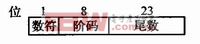
浮点数表示为:X=MsEsEm-1…E1E0 M-1M-2…M-n。IEEE标准规定:阶码用移码;尾数的符号位用1表示负数,0表示正数;尾数的数据位用原码表示,并且隐藏了第24位(即M-1),M-1为1,所以尾数是大于等于0.5小于1的小数。
阶码用移码表示、尾数用原码表示浮点数的好处:
①浮点数据零的所有位均为零。
②2个浮点数比较大小时,可不必区分阶码位和数据位,视为有符号32位整型数据比较。
3 浮点型运算的具体实现
3.1 加减运算
Cortex-M3是32位的内核,可以把单精度浮点数存储为32位的有符号整数,这样便于比较运算。加减运算的流程如图1所示。

3.2 乘法运算
对于浮点型乘法运算,因为Cortex-M3内核支持单周期乘法指令,所以运算速度比较快。运算流程与加减运算相似,不同之处有:阶码相加最高位取反得结果的阶码;尾数不用正负号调整,直接相乘,而尾数的符号位异或即可得结果的符号位;两个24位尾数相乘的结果为48位,尾数规格化的时候,判断第48位是否为1,如果为1则阶码加1,如果为O则第47位一定为1,阶码不必调整。
3.3 除法运算
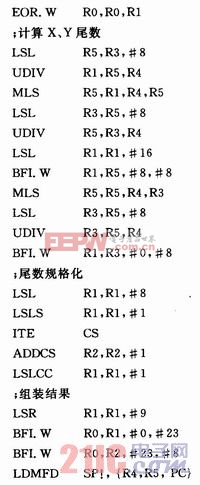
除法运算中,提取阶码、重现尾数、提取尾数以及尾数符号位的操作与乘法运算相同,因此除法运算过程与乘法运算过程的基本相似,只是计算X、Y尾数的商有所不同。
计算商的方法为:先把X的尾数左移8位,与Y的尾数相除得结果Z1,并计算出余数W1=X-Z1*Y;W1先左移8位,与Y的尾数相除得结果Z2,并计算出余数W2=W1-Z2*Y;W2左移8位,与Y的尾数相除得结果Z3。调整Z1、Z2、Z3并组装成24位或25位尾数。除法运算的源程序如下:
3.4 浮点型数据比较
从浮点型数据存储的格式来看,可以把浮点数按照有符号整型数据来比较大小。比较的结果:相等输出O,大于输出1,小于输出-1。
4 测试结果
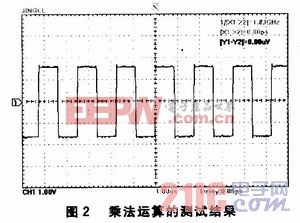
利用基于Cortex-M3内核的STM32F103VET6处理器测试浮点型运算的速度,处理器的工作频率为72 MHz,测试的方法为:每完成一次浮点型运算,处理器的一引脚变化一次电平。经测试,变化一次电平耗时153ns。图2、图3是对乘法运算和除法运算的测试结果。从图中可以看出,乘法的运算速率约为0.717μs/次,除法的运算速率约为0.957μs/次。可见,运算速率比较高,精度较高,可以满足实际应用要求。

结语
测试结果表明,在Cortex-M3内核上实现浮点型运算,可以达到所要求的精度,运算速度较快,具有较高的实时性。本文提出的浮点型运算的处理方法在基于Cortex-M3内核的处理器上有着较高的应用价值。希望对从事这方面的人员有所帮助。
- “节能之星”EFM32应用方案——手持式激光测距仪(06-25)
- 智能电表设计方案、案例及方案对比(04-07)
- 基于Kinetis微控制器的三相电表设计(11-10)
- 基于Cortex-M3的微控制器热电偶测量系统(01-15)
- Cortex-M3的次声波输气管道泄漏检测系统(08-08)
- “节能之星”EFM32应用方案-手持式激光测距仪(07-27)