LabVIEW设计模型——顺序模型之数据流
在LabVIEW中,数据由前面的节点流向后面的节点,程序随着数据的流动而执行。这就形成了一个自然的顺序结构。

上图就是一个典型的由数据流控制的顺序模型。Simulate Signal节点产生一个波形数据,然后数据沿连线流动到Spectral Measurements节点做频谱分析,分析得到的频谱数据沿连线流动到Write To Measurement File节点,将节点存储到数据文件。整个程序,随着数据的流动一步一步的执行,形成了一个完美的顺序模型。
如果两个节点之间没有数据联系,我们也想要他们顺序执行怎么办呢?那就要利用错误簇和条件结构。
错误簇,是LabVIEW设置的特殊的数据结构,由status(错误状态)、code(错误代码)、source(错误信息)三部分组成。它是用来在节点之间传输错误信息的。(如下图所示)
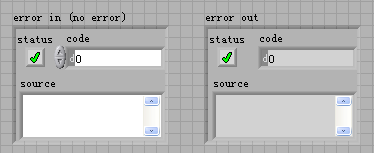
其实,错误簇除了可以传递错误信息以外,还有一个重要的功能就是通过错误簇中数据的流动来确定程序的执行顺序。当节点含有错误簇端子时,我们就要把前一个节点的error out端子和后一个节点的error in端子连接起来,已确定执行的顺序,以及保证错误信息的传递。
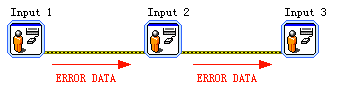
上图所示的VI由3个用户输入节点构成。三个节点之间本没有数据联系,也就是说执行顺序不确定。但是,通过错误簇的连接使它们形成了数据依赖,从而能够顺序执行。
如果在节点中没有错误簇,有该如何用数据流来确定执行顺序呢?看看下面的例子:
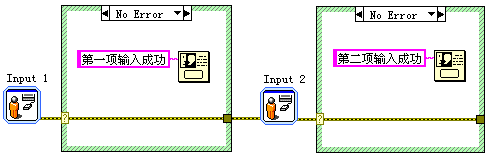
程序由两个用户输入节点和两个对话框节点构成。我们需要第一个用户输入节点执行完毕后,由第一个对话框节点来提示输入成功,第二组输入节点和对话框同理。由于对话框节点并没有错误簇端子,于是就使用了两个条件结构来放置两个对话框节点。错误数据从两个条件结构中穿过,来保证程序的顺序执行。
值得一提的是,条件结构的所有分支都需要连接错误信息,否则LabVIEW会报错。
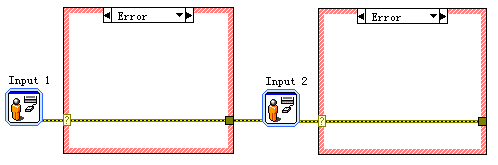
P.S. 由于错误簇有以上种种的用途,所以在我们写一定要在所有的子VI中加入错误簇,即使子VI中没有错误要处理,也要加上error in和error out两个端子。
好了,利用数据流来确定执行的顺序的方法就写这么多吧。
LabVIEW设计模型顺序模型数据 相关文章:
- 频宽、取样速率及奈奎斯特定理(09-14)
- 为什么要进行信号调理?(09-30)
- IEEE802.16-2004 WiMAX物理层操作和测量(09-16)
- 为任意波形发生器增加价值(10-27)
- 基于PCI 总线的高速数据采集系统(09-30)
- 泰克全新VM6000视频测试仪助力数字电视等产品测试 (10-06)