中文语音处理在数字助听器中的开发
时间:01-15
来源:互联网
点击:
|
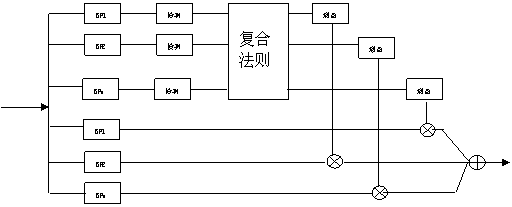
图 1 辅音增强系统
2) 重音 (Stress)
组成一段语流的各音节声音响亮程度并不完全相等。有的音节在语流中听起来声音比其他音节响亮,这就是重音音节。有的重音和语义、语法有密切关系,如汉语普通话中的词重音。词重音出现在词中,是由于词的含义不同,重读音节的位置也不同。如 “ 技术 ” 和 “ 计数 ” ,重音分别在第一音节和第二音节。这种语意的区别是通过 “ 超音段特征 ” 来表达的。
在汉语中,重音对韵律特征参数的影响倍受关注。语流中 “ 韵律特征 ” ( prosodic feature )是通过音高、音长和音强的变化,即 “ 超音段特征 ” 表现出来。从语图上观察,音域明显扩张重音的特点。高明明对普通话语句汇总强调重音的声学表现进行了研究,指出:
( 1 ) “ 音高升高是普通话语句中强调重音的重要韵律特征 ” 。
( 2 )音高和时长对于强调重音的实现具有同样重要的作用。它们之间的关系是对立互补的。
语音合成的经验告诉我们,音高是调节重音最有效的手段,所以强化重音的方法主要是提高音高。
3) 声调 (Tone and Internation)
一个音节除了包括由元音和辅音按时间顺序排列成系列的音质单位以外,还必须包括一定的音高、音强和音长。在一些语言里,音高在音节中起的作用可以说是和元音、辅音同样重要,这种能区别音节的意义的音高就是 “ 声调 ” 。根据声调的有无可以把世界上的语言分为声调语言和非声调语言两大类。汉、藏语系语言最突出的一个特点就是有声调。
汉语普通话的声调起着构词辩意的作用。对于具有相同拼音的一个音节,由于声调不同,可以具有不同的含义。普通话单音节的声调变化共有四种模式,不同的声调反映在语音参数上是基音频率轨迹的变化不同。根据实验观察所定义的一些规则,可以认为基音频率轨迹的某一参数超越某一预先确定的门限时,则可判为某一声调类型。在此基础上,黄泽镇、杨行峻提出的识别模式采用基音轨迹曲线的一、二次斜率、谷点和平坦度对四种声调有很强的区别性,实验表明,这一算法的结果识别率可达到 99% 。
林茂灿指出声调信息主要存在于主要元音(及其声学过渡)上。考虑到声调音高的变化,对音长和音强都可能产生影响,即:去声最短、最强,上声最长,最弱,阴平和阳平举重,阳平又往往比阴平略长一些。声调的增强不能简单地对主要元音进行放大,而应该不同的声调在音高和音强上有不同的处理。实际应用中我们采取如下策略:
( 1 )对去声增强音强。
( 2 )对上声加大音长。
( 3 )对阴平和阳平不改变。
图 3 展示的 4 条声学曲线分别描述了四声在不同时间里的频率特征。

图 3 汉语四声的声调声学特征
2. 方法 (Methodology)
数字助听器的核心部分是增益计算,基于频域的处理过程,它建立了各频率段的输入瞬时能量与增益的函数关系,如图3所示,对每个频段的瞬时能量进行短时能量累计和长时间慢速平均可获得信号识别和分类所必要的数据。其中:
( 1 ) E j (n)= a E j (n-1) 式中: a 是时间常数 。
( 2 )使用倒谱算法提取基频, 512 个点 FFT , 40ms 汉明窗,窗移为 10ms 。
( 3 )用一个简单的滑动平均算法对每个音节测到的基频进行平滑处理,剔除那些平滑段内偏离均值过大的值。
( 4 )音高和音长分别进行归一化。
( 5 )采用一个二次曲线在最小均方误差的意义下逼近基音轨迹。并计算曲线的一次斜率、二次斜率、谷点和平坦度。
上述算法采用基于 TOCCATA 指令系统的汇编语言实现。 14 位 A/D ,采样率设为 32KHz 。
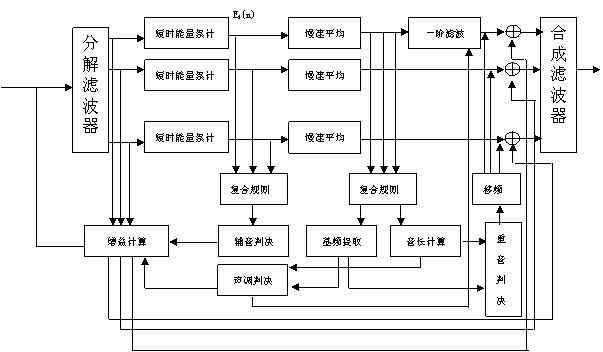
图3 . 汉语言语增强系统处理结构图
1). 语音的切分 (Classifications of Phonemes)
声波由音质(即音色)、音高、音强和音长四部分组成,这四部分在语音中起着不同的作用,但在时间上又是同时并存的。
音质成分 —— 按音节划分,如元音、辅音。
超音质成分 —— 由音高、音强和音长三部分组成,附着于一个音节或音段上。
从声波特性上看,可以由基频确定音高,根据振幅确定音强,根据时间确定音长。
- 医疗电子技术大会折射行业发展方向(04-18)
- 基于Blackfin DSP的哮喘管理设备(12-18)
- 医学成像的未来(08-25)
- 基于DSP的EASI十二导联多功能Holter系统(03-08)
- 基于AD5933的高精度生物阻抗测量方法(03-15)
- 现代医疗传感器种类及前沿应用简介(10-09)