数字信号处理器概论
时间:08-31
来源:互联网
点击:
MCU性能上的改进
对数字信号处理器可以确切的下这样的定义:解决实时处理要求,适合DSP运算需求的单片可编程微处理器芯片。原理上说通用微机、单片机都可以用来做信号处理的硬件平台,但作为DSP实时处理要求必须满足大数据量、复杂计算、实时性强的各种运算,因而DSP芯片针对DSP算法特点做了以下几方面的改进:
运算能力上的扩充
采用专用的硬件乘法器,有足够的字长,乘法结果保留全部数值,用双字长乘法存储器,同时可以用来做双精度运算。
自动产生数据地址
通用处理器由ALU产生地址,在DSP中专门有地址产生单元,通过程序循环,自动产生数据地址,这一单元本身也是一个微处理器,可以通过编程产生复杂的非顺序地址(例如FFT中的倒位序地址产生)。
指令时序的产生不对其他运算单元造成额外开销
指令时序是可编程的,在遇到执行程序转移和循环时,不会额外增加开销。
简单比例定标运算得到宽的动态范围
一般DSP芯片中都有桶形移位器,可以在一定范围内调整数据输出宽度,特别是在做浮点和块浮点运算时,免去主处理器作多次移位和旋转操作。
DSP处理器特点
DSP处理器的着眼点是要求速度快、处理的数据量大、效率高。但是单纯提高时钟速度受到工艺等各种因素的限制,一般是缓慢的,所以必须从结构上着手。某些概念其实在二十世纪40年代已经出现:其一是改造处理器的处理方法,用多总线、多存储器体系结构;其二是提高程序和数据流的速度,采用流水线,并行处理等方法。尽管不同厂商采用不同的技术和措施,但在这些方面都有共同点。以下就DSP芯片一些特点来作说明。
采用哈佛(Harvard)结构和改进的哈佛结构
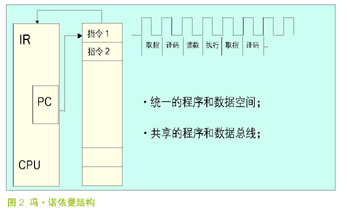
通用机采用冯·诺依曼(Von Neumenn)结构,这主要考虑到成本,其结构如图 2 所示。把指令、数据、地址的传送采用同一条总线,靠指令计数来区分三者。由于取指和存取数据是在同一存取空间通过同一总线传输,因而指令的执行只能是顺序的,不可能重叠进行,所以无法提高运算速度。
DSP处理器几乎毫无例外的采用哈佛结构,如图3所示。哈佛结构把程序代码和数据的存储空间分开,并有各自的地址和数据总线,每个存储器独立编址,用独立的一组程序总线和数据总线进行访问。
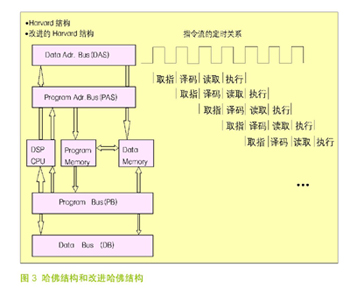
如果程序代码存储空间与数据存储空间之间还可以进行数据交换,则称为改进的哈佛结构。这种结构可以并行进行数据操作。例如在做数字滤波时把系数放在程序空间,待处理的样本数据放在数据空间,处理时可以同时提取滤波器系数和样本进行乘法和累加操作,从而大大提高运算速度。 改进哈佛结构还可以从程序存储区来初始化数据存储区,或把数据存储区的内容转移到程序存储区,这样可以复用存储器,降低成本,提高存储器使用效率。
多总线结构
例如TMS320C54X结构中有一组程序总线(PB PAB),两组读数据总线(CB CAB)、(DB DAB),和一组写数据总线(EB EAB),这样可以同时读取两组数据和存储一组数据,即同一时钟周期内可以执行一条3个操作的指令。这种附加总线和扩充地址增加数据流量,提高寻址能力。
采用流水线操作
计算机在执行一条指令时,要通过取指、译码、取数、执行等各阶段。由于DSP哈佛结构指令的各个阶段可以重叠进行,这样对每一条指令似乎都是在一个周期内完成,可以把指令周期减到最小,增加数据吞吐量。
这种流水线操作也不是十全十美的,其主要原因是,一项处理很难被分解成若干个处理规模一致、在时间上有最佳配合的流水段,因而需要用寄存器协调流水线工作。
流水线操作适用于循环操作时间足够长或多个数据点反复执行同一指令的情况。这是由于,流水线启动和停止的阶段是流水线逐步被填满和出空的过程。对于一次性非重复计算,流水线不可能达到稳态,反而用主要时间做填满和出空操作,因而是不合适的。
硬件乘法器和高效的MAC指令
在DSP算法中,乘法累加操作是大量的运算。因而DSP芯片都有硬件乘法器,使得乘法运算做到一个周期内完成。与之配合的指令为MAC-乘法累加指令,其功能如图 4 所示,它可以在单周期内取两个操作数相乘,并将结果加载到累加器。有的DSP还具有多组MAC结构,可以并行处理。
对数字信号处理器可以确切的下这样的定义:解决实时处理要求,适合DSP运算需求的单片可编程微处理器芯片。原理上说通用微机、单片机都可以用来做信号处理的硬件平台,但作为DSP实时处理要求必须满足大数据量、复杂计算、实时性强的各种运算,因而DSP芯片针对DSP算法特点做了以下几方面的改进:
运算能力上的扩充
采用专用的硬件乘法器,有足够的字长,乘法结果保留全部数值,用双字长乘法存储器,同时可以用来做双精度运算。
自动产生数据地址
通用处理器由ALU产生地址,在DSP中专门有地址产生单元,通过程序循环,自动产生数据地址,这一单元本身也是一个微处理器,可以通过编程产生复杂的非顺序地址(例如FFT中的倒位序地址产生)。
指令时序的产生不对其他运算单元造成额外开销
指令时序是可编程的,在遇到执行程序转移和循环时,不会额外增加开销。
简单比例定标运算得到宽的动态范围
一般DSP芯片中都有桶形移位器,可以在一定范围内调整数据输出宽度,特别是在做浮点和块浮点运算时,免去主处理器作多次移位和旋转操作。
DSP处理器特点
DSP处理器的着眼点是要求速度快、处理的数据量大、效率高。但是单纯提高时钟速度受到工艺等各种因素的限制,一般是缓慢的,所以必须从结构上着手。某些概念其实在二十世纪40年代已经出现:其一是改造处理器的处理方法,用多总线、多存储器体系结构;其二是提高程序和数据流的速度,采用流水线,并行处理等方法。尽管不同厂商采用不同的技术和措施,但在这些方面都有共同点。以下就DSP芯片一些特点来作说明。
采用哈佛(Harvard)结构和改进的哈佛结构
通用机采用冯·诺依曼(Von Neumenn)结构,这主要考虑到成本,其结构如图 2 所示。把指令、数据、地址的传送采用同一条总线,靠指令计数来区分三者。由于取指和存取数据是在同一存取空间通过同一总线传输,因而指令的执行只能是顺序的,不可能重叠进行,所以无法提高运算速度。
DSP处理器几乎毫无例外的采用哈佛结构,如图3所示。哈佛结构把程序代码和数据的存储空间分开,并有各自的地址和数据总线,每个存储器独立编址,用独立的一组程序总线和数据总线进行访问。
如果程序代码存储空间与数据存储空间之间还可以进行数据交换,则称为改进的哈佛结构。这种结构可以并行进行数据操作。例如在做数字滤波时把系数放在程序空间,待处理的样本数据放在数据空间,处理时可以同时提取滤波器系数和样本进行乘法和累加操作,从而大大提高运算速度。 改进哈佛结构还可以从程序存储区来初始化数据存储区,或把数据存储区的内容转移到程序存储区,这样可以复用存储器,降低成本,提高存储器使用效率。
多总线结构
例如TMS320C54X结构中有一组程序总线(PB PAB),两组读数据总线(CB CAB)、(DB DAB),和一组写数据总线(EB EAB),这样可以同时读取两组数据和存储一组数据,即同一时钟周期内可以执行一条3个操作的指令。这种附加总线和扩充地址增加数据流量,提高寻址能力。
采用流水线操作
计算机在执行一条指令时,要通过取指、译码、取数、执行等各阶段。由于DSP哈佛结构指令的各个阶段可以重叠进行,这样对每一条指令似乎都是在一个周期内完成,可以把指令周期减到最小,增加数据吞吐量。
这种流水线操作也不是十全十美的,其主要原因是,一项处理很难被分解成若干个处理规模一致、在时间上有最佳配合的流水段,因而需要用寄存器协调流水线工作。
流水线操作适用于循环操作时间足够长或多个数据点反复执行同一指令的情况。这是由于,流水线启动和停止的阶段是流水线逐步被填满和出空的过程。对于一次性非重复计算,流水线不可能达到稳态,反而用主要时间做填满和出空操作,因而是不合适的。
硬件乘法器和高效的MAC指令
在DSP算法中,乘法累加操作是大量的运算。因而DSP芯片都有硬件乘法器,使得乘法运算做到一个周期内完成。与之配合的指令为MAC-乘法累加指令,其功能如图 4 所示,它可以在单周期内取两个操作数相乘,并将结果加载到累加器。有的DSP还具有多组MAC结构,可以并行处理。
DSP 滤波器 解码器 电路 FPGA Altera 电子 MCU 单片机 总线 振荡器 仿真 C语言 MIPS 相关文章:
- F1aSh存储器在TMS320C3X系统中的应用(11-11)
- 基于PIC18F系列单片机的嵌入式系统设计(11-19)
- DSP在卫星测控多波束系统中的应用(01-25)
- 基于PCI总线的双DSP系统及WDM驱动程序设计(01-26)
- 利用Virtex-5 FPGA实现更高性能的方法(03-08)
- DSP与单片机通信的多种方案设计(03-08)