借力big.LITTLE设计架构 多核处理器强效又省电
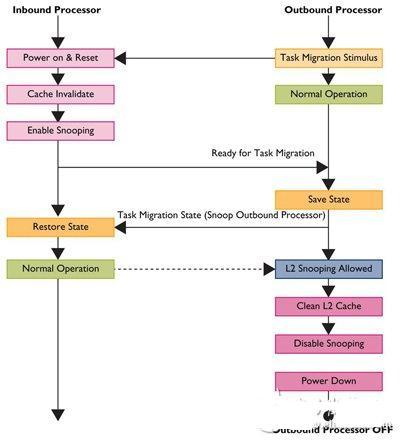
图3 big.LITTLE运算任务切换流程图
由于LITTLE处理器丛集中,每个处理器都将对应一个big丛集的处理器,因此CPU乃成对配置(Cortex-A15及Cortex-A7处理器上都有CPU0,Cortex-A15及Cortex-A7处理器上都有CPU1,以此类推),不论何时每个配对中只有一个处理器可运转;而系统则会主动侦测各处理器负载,在高负载时将内容执行移到大核心(图4)。当负载从离埠核心移到入埠核心,便会关闭其中一个核心,这种模式让big与LITTLE核心组合能随时运转。
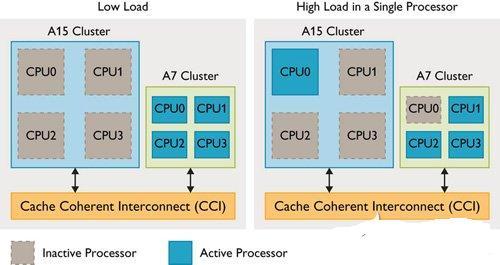
图4 big.LITTLE系统CPU切换示意图
[@B]big.LITTLE MP支援非对称丛集运作[@C]big.LITTLE MP支援非对称丛集运作
至于big.LITTLE MP模式则进一步将软体堆叠分配到两个丛集中各个处理器,如此一来,所有CPU皆可同时运作,将系统效能提升到最高点。
由于big.LITTLE系统可经由CCI-400达到高速缓存的一致性,因此有另一种模式能让Cortex-A15及Cortex-A7处理器同时运作并同步执行程式码,称为big.LITTLE MP,基本上可看作一种异质性多工处理模型。这是big.LITTLE系统最先进且最具弹性的模式,能跨越两个丛集调整单一执行环境。
在这种使用模式下,若执行绪有上述处理效能方面的需求,便可开启Cortex-A15处理器核心并同时透过Cortex-A7处理器核心执行任务。如果没有这方面需求,则只须开启Cortex-A7处理器,在实际应用上,不同丛集的处理器核心不一定一致,而big.LITTLE MP比较容易支援非对称的丛集。
改善低频运算多余功耗big.LITTLE备受瞩目
big.LITTLE技术之所以受到IC设计业者瞩目,原因就是一般移动工作量对效能的需求各有不同,必须找到最合适的核心处理。图5显示的是目前搭载Cortex-A9的移动装置中,两个核心在DVFS、闲置与完全关机状态下所花费时间的百分比,(a)处代表最低频率操作点;(b)处则代表最高频率操作点,介于两者之间则属中级频率。
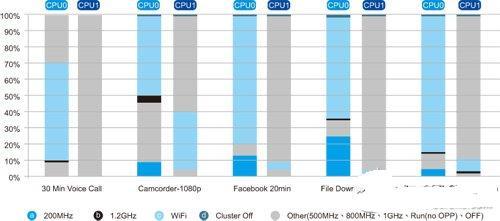
图5低密度使用案例的DVFS驻留时间
除DVFS状态之外,作业系统电源管理也会使中央处理器闲置,图中(c)处代表闲置时间,当CPU闲置的时间够长,系统电源控制软体将完全关闭其中一个核心以节省耗电,图中(d)处便代表这部分。
从图5可清楚看出应用程式处理器在好几种普通工作量下,都有相当多时间处于低频率状态,在big.LITTLE系统里,系统单芯片(SoC)可利用耗能较低的Cortex-A7核心,执行最高操作频率以外的所有工作。以相同方式分析更为密集的工作量,Cortex-A7处理器对应出低于1GHz频率的机会仍然很大。
事实上,自2011年起,使用者层级软体已能在big.LITTLE排程上运转,不过,那只是在处理器核心与互联的软体模型环境上发展。为完整评估big.LITTLE系统效能、功耗及调校是否合宜,还须打造一个能让使用者软体全速运转的测试芯片。
ARM测试芯片早在2012年初夏即由晶圆代工厂完成,并在短短几周内开始搭配参考设计板运转,支援完整版的Linux系统及Android 4.0作业系统。这个测试芯片包含一个双核心Cortex-A15丛集、一个三核心Cortex-A7丛集,以及CCI-400快取一致汇流排架构。会影响部分使用者评效基准的绘图处理器并不包括在内,但平台仍可支援Linux、Android作业系统与效能测试软体。
测试芯片的Cortex-A15最高频率达1.2GHz,Cortex-A7则为1GHz.效能评析结果显示,虽然测试芯片上的记忆体系统效能不如big.LITTLE SoC量产后的预测水准,但Cortex-A15与Cortex-A7中央处理器的效能仍落在预期范围内。
用来测试big.LITTLE效能的任务量,主要基于Android 4.0系统,透过网页进行网路浏览器效能循环,背景则有音效播放。在此实例中均以相当密集的工作量搭配对性能需求不高的背景活动,网路浏览器每2秒便进行网页循环,每页卷动达500画素,因此对系统效能需求相对较高。
这组结论属于较早期的测试结果,用来测试初版big.LITTLE MP修正程式组,将Linux排程程式从一个完整而平衡的排程模式调整成big.LITTLE模式。预期未来在更多业者投入软体修正后,效能与能耗将更进一步改善,而其他可调校的部分也将有相关解决方案被提出。
另外,测试芯片缺少GPU,使CPU的负载高过搭载GPU系统在卸载状态下的负载水准,而在CPU负载较低的状况下,可能会较常使用LITTLE核心,进而达到节能目的。它包含一套基本的电压及频率操作点,但没有对单一处理器核心做独立的电源开关设计,因此big.LITTLE系统单芯片量产后测试结果可望提升。举例来说,后台任务效能便可节省超过70%能耗。
IC设计业者正全力投入big.LITTLE开发,然而,各界最常见的疑问就是应选择哪一种软体模式?目前主要是在CPU切换与big.LITTLE MP之间择一,而两种方式各有正反意见。在CPU切换方面,由于big及LITTLE核心处于搭配成对的状态,因此对称式的拓扑能顺畅运作;而big及LITTLE核心数量不同的非对称式拓扑则须额外的运转。
big.LITTLE MP模式效果更出色
由于Cortex-A7中央处理器核心体积较小,因此可使用四个LITTLE核心加上一到两个big核心,这种作法可能会具有吸引力。从正面角度来看,中央处理器切换让电源及效能的调校更为容易,可重复利用既有的作业系统电源管理程式码,代表实作将有多年的研发及测试结果做为支援。加上不必调整核心排程程式,范围比执行big.LITTLE MP模式更为简化,而软体模式也能日趋成熟。
整体而言,CPU切换是一种极佳解决方案,相关IC设计业者亦正研拟升级至big.LITTLE MP模式,以提供更多元的处理器运算解决方案。big.LITTLE MP具有多项技术优势,虽技术尚未完全成熟,但目前的测试结果已相当不错。由于此模式也支援非对称式拓扑,故毋须调整软体即可完全利用系统中所有核心,对提升芯片效能并降低功耗更有利。
举例来说,big.LITTLE MP能同步利用所有核心在短时间内达到最高效能,或将big与LITTLE核心上的DVFS设定与排程程式设定调成不同状态,以节省更多电力。不过弹性提升仍有其代价,芯片商与系统业者均须增加调校动作,才能从big.LITTLE MP平台获取完整的效能及能耗优势。
这与过去一直为主流,由芯片和晶圆代工厂将作业系统能源管理设定,以及DVFS参数资料,依装置需求转化为移动系统单芯片平台的作法并无太大差异。big.LITTLE MP模式将切换模式延伸并纳入新的参数资料,不仅更为节能,更能为经过效能优化的big核心增加系统回应度。
big.LITTLE MP模式正快速成熟,已有许多芯片商积极投入开发,产品可望在2013下半年大量出炉。由于big.LITTLE MP模式并不须大幅改变硬体,因此晶圆厂可部署支援CPU切换模式的平台,进行核心更新后,再升级到big.LITTLE MP模式,或直接建置现有完整的big.LITTLE平台。
目前big.LITTLE MP相关软体已开始运转,并开始在芯片商研发平台端进行系统测试,ARM与合作夥伴亦正积极进行软体强化,针对各种使用实例将系统效能调校至最佳效果,包括排程程式的负载平衡政策、上下切换点以及执行绪优先秩序等。此外,ARM也在开放原始码平台每月定期推出big.LITTLE MP修正程式组,内含测试芯片平台、测试结果以及说明文件的最新的调校结果。Linaro也已推出修正程式组和CPU切换软体,并开始供应Linaro联盟成员。
随着big.LITTLE技术演进,ARM近期更发布两款具有big.LITTLE处理性能的新型CPU核心--Cortex-A57及Cortex-A53处理器。Cortex-A57是经过效能优化的big核心,每时脉周期的效能较Cortex-A15增加25%,频率效能与能源效率也都高于Cortex-A15处理器。Cortex-A53则为LITTLE核心,每时脉周期效能增加40%,能源效率则等同于Cortex-A7.
布局下世代big.LITTLE ARM加速推出新核心
这些新核心在架构上都完全相同,并支援ARMv8架构,因此能导入进阶版的NEON技术与浮点功能、加密加速并支援64位元。除AMBA4 ACE,两种核心也都支援新世代快取一致汇流架构,且跟现有ARMv7架构的CPU核心一样,能在AArch32模式下执行既有程式码。支援64位元及额外一般用途暂存器的应用方式洗炼而有效率,且能耗增加不多。
微架构也经过强化,以增加各核心在每个指令时脉周期中的传输量。这些新款核心在经过软体细部升级并支援64位元定址模式后,将会跟Cortex-A15及Cortex-A7处理器一样支援big.LITTLE技术。
两种核心将在2013年提供给合作晶圆厂,预计2014年开始量产。
未来,big.LITTLE设计将为移动装置系统功耗及效能控制点的极度宽动态(Wide Dynamic Range)带来全新的可能性,这是单一类型处理器核心所无法达到的。目前市面上装置的工作量往往混杂程度高低不同需求的执行绪,这种宽动态便可为其提供完美的执行环境,提供一个在新世代移动平台下,提升装置运算效能并延长续航力的大好机会。
big LITTLE 多核处理器 ARM 大小核 相关文章:
- 多核处理器将如何改变电源管理?(11-19)
- 借力大小核设计架构 多核处理器强效又省电(01-03)
- 处理器的大小端模式分析(06-28)
- 多核处理器构架的高速JPEG解码算法(02-07)