嵌入式设备上的文件系统优化设计
函数block_read_full_page( )的具体实现过程如图2所示。系统根据传入的参数,获得Block大小,生成相应的缓存空间,然后反复发出Block读的Request,直到完成整个Page的读任务。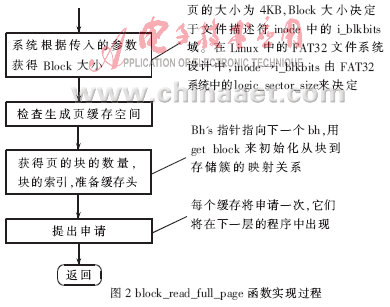
如图2所示Block_read_full_page( )的实现机理中,最重要的是根据系统状况,经过计算确切地获得将由多少个Block来组成一个Page。
在Linux实现中,Block大小决定于文件描述符inode中的i_blkbits域。在Linux中的FAT32文件系统设计中,inode->i_blkbits是由FAT32系统中的logic_sector_size决定的,即用/linux-2.4.x/fs/fat/inode.c来实现从FAT32文件系统映射到Linux的inode各项定义。
1.5 系统MAKE_REQUEST[1-4]
经过上述各个步骤的计算,在文件系统实现中,将文件读操作转化为若干个不同的Block读需求,最后向下层驱动程序层发起具体的命令Request。上述的转化,基本上是根据底层配置以及内存管理的需求,将大的/整体的命令细分/拆分为更加细小的动作。
而在实际执行过程中,肯定存在较多的过度拆分的情况,以致于产生过多低效率的命令,因此,在具体实现过程中,为了避免这种情况,在实际发出Request之前,需要对其进行相应的检查,合并相关的Request,以提高系统实现性能。这个过程将由submit_bh来完成。
图3所示是submit_bh函数中的主体调用子函数_make_request的实现过程。在FAT32实现中,_make_request根据获得的Block大小、存储设备的sector number,准备好内存空间后,向IDE发出具体的Request。而具体的Request合并将发生在发出Request之前。其实现原理根据当前队列中Request的地址相关性来判断。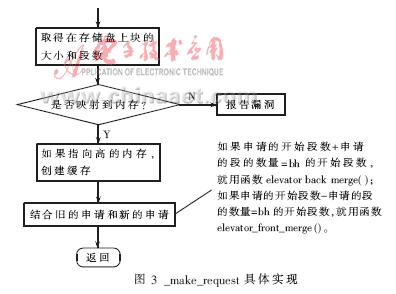
2 优化策略分析
面对提高文件系统访问性能的需求,经过分析系统如何处理用户发起的读命令,观察read( )命令从VFS到具体的文件系统FAT32的实现,转化为具体的每一个Request的整个过程,系统的优化可从以下几个方面进行。
2.1 Block读操作改进
根据1.4节针对block_read_full_page( )的描述,实际上是根据实际文件系统定义的Block大小,将一个page转化为多个Block的读动作。而在FAT32的具体实现中,根据/linux-2.4.x/fs/fat/inode.c文件中的描述,Block size等于logic_sector_size的大小,即逻辑扇区大小。
在FAT文件系统的定义中,逻辑扇区是为了统一不同硬盘的物理扇区而设置的。由于一般物理扇区最小为512B,因此在FAT32普遍实现中,逻辑扇区设置为512B。
而当前大容量的硬盘系统,其物理扇区普遍大于4KB。在这种情形下,根据Linux上的FAT32实现,一个4KB或者以上的物理扇区的读,被人为地划分为8次512B逻辑扇区的读命令。而由于物理原因,可知道物理扇区将是磁盘上最小的寻址单位,也就是说,在最坏的情况下(即下层__make_request没有及时判断出这些buffer是可以合并的),向一个以4KB为扇区的硬盘发出一个page(4KB)的读命令,最后将由8次同一个扇区的读动作来实现。
针对block_read_full_page划分的不合理,可以尝试用重写block_read_full_page来实现,即扩大Block为4KB。这样即可以认为,一个Linux的page读将按照一次Block读来完成。同时由于Linux内存管理都以4KB大小的page作为基本单位,这样在所有文件系统的内部,将以4KB为最小单位进行读取,把跨4KB的特殊情况留给下层驱动来完成拆分(由于大容量硬盘的应用目标,这种情况几乎不会出现)。因此,Block改进就是通过改进Block的大小,进行合并过多的拆分,来达到提高系统的读性能的作用。
2.2 预读机制控制
Linux系统上的FAT32文件系统实现,依然强烈依赖着预读机制来完成实际的读操作。这是由于Linux最初是以PC机为设计目标的,即存在内存交换文件和各种缓冲机制来对有限的资源进行无限的逻辑扩展[5]。
这种多重缓冲的设计机制,非常适合应用程序/控制命令流存储的磁盘管理。然而,在本嵌入式系统设计中,FAT32作为数据存储空间,数据存储相对有序,并且可预测性比较强。因此,这种抽象带来的好处不是特别的明显。同时由于存在多级缓冲,尤其是硬盘系统的多级缓冲,会造成以下几个缺点:
(1)因多次数据搬移,造成性能下降。对于嵌入式系统尤其是消费类设备,由于成本的原因,其总线带宽(包括内存总线与外部总线)都是相对有限的,因此,在这类总线中的数据搬移造成的延迟,是不能忽略的(而PC机的设计中,由于高速的内存吞吐量,往往这个延迟是可以忽略的)。
(2)缓冲和cache的存在,会造成具体动作更多不可预测性,这违反了实时系统的需求。因为嵌入式系统很多层面都有一定的实时性要求;其次,增加了硬盘电源管理的难度,即硬盘状态将频繁切换,减少有机会进入省电的Idle模式及更加省电的Sleep模式,浪费了硬盘自身APM(Advanced Power Management)带来的好处。
因此,在本设计中需要对预读机制进行管理,甚至去除预读机制。实际上是对文件读实现中的do_generic_file_read( )函数进行改造,去除了预读判断机制,采用直接调用方式。
2.3 Page机制改进
整个文件系统的读操作,将以page为单位进行相应的规划,即以4 096B为考虑对象。而在真实的磁盘系统中,由于大容量磁盘的普及,4 096B几乎成了最小的物理扇区。面对这样的磁盘系统,其FAT文件读写具体实现,实际上不能充分利用底层硬件以及驱动程序提供的各种优化措施,如DMA等[6-7]。
针对这样的思路,需要引入多个page读操作的相关性,即在fat_readpage( )之前增加多个page合并的判断。可以借鉴Request合并的方式进行page合并,即通过目标地址判断的方式进行合并部分Page读动作。
- 基于FAT16文件系统的嵌入式温度记录器(05-30)
- SPI Flash M25P32 的TFFS文件系统的设计与实现(07-04)
- AT24C512中数据的文件系统化管理(10-09)
- 基于ATmega32的SD卡上FAT32文件系统数据读取(10-08)
- 基于STM32处理器的便携式BMP图片解码系统设计(01-07)
- 基于ARM9和μC/OS-II的SD卡文件系统设计与实现(07-08)