安卓底层开发学习经验第十一期
这一期呢,我们主要是学习我们的init进程脚本如何解析我们的启动脚本的,我们init进程做完一些初始化的工作之后就会解析我们的启动脚本,他的启动过程主要分为下面几个部分
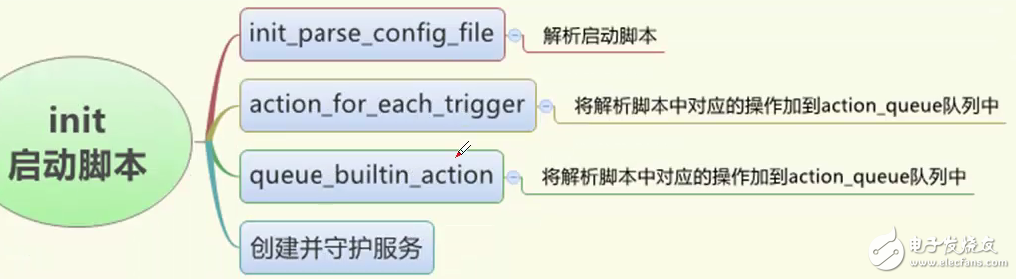
第一个就是使用init_parse_config_file函数来解析我们的启动脚本,把我们的启动脚本的每一个命令全部解析到我们的一个列表中;
第二个就会调用action_for_each_trigger和queue_builtin_action这两个函数把我们所解析的相关的操作加到我们的action_queue的队列中,然后就会从action队列中取相应的操作创建相关的服务或执行相关的命令,最后再去守护我们相关的服务
那么我们首先来看一下我们解析脚本的一个过程
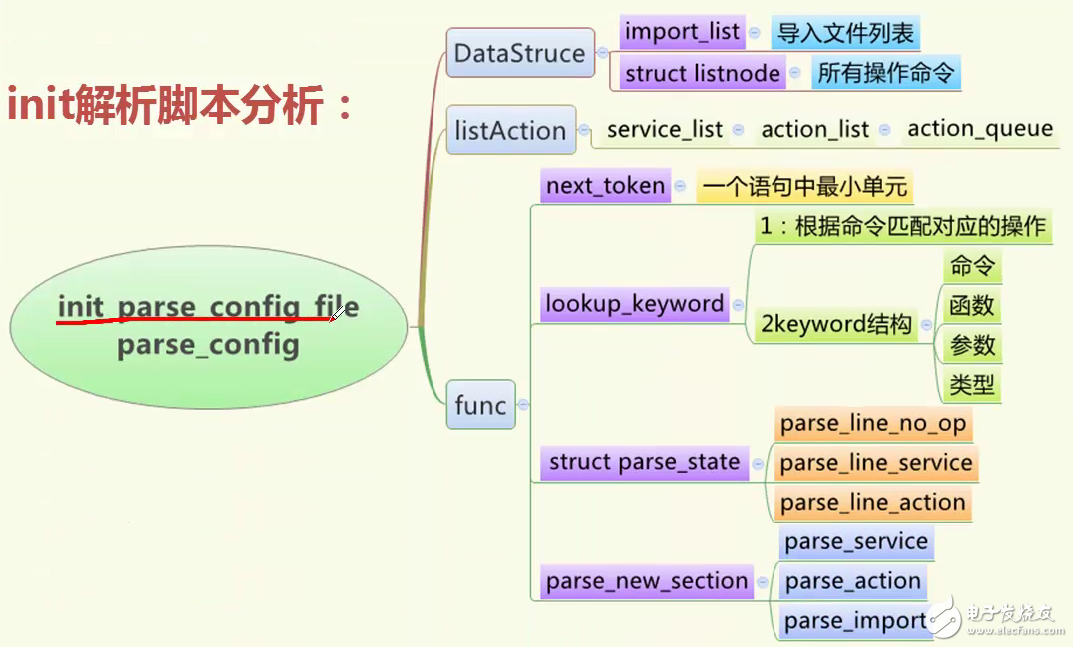
首先我们会调用init_parse_config_file来解析我们的init.rc ,在解析前,我们首先打开我们的init.rc ,然后调用parse_config这个函数来解析我们的启动脚本,在解析过程中主要涉及到以下几个数据结构和链表
我们的数据结构包括:import_list和struct listnode
import_list主要是用来保存我们init.rc中所导入的其他脚本文件,比如init.usb.rc等
struct listnode主要是用来保存启动脚本中所有的操作命令
而我们的三个链表呢,是用来保存我们命令的这三个链表分别是:service_list 、action_list 、action_queue
service_list主要是用来保存我们脚本中所有的服务
action_list 主要是用来保存我们所有的操作
action_queue主要是执行的链表
我们解析完的服务和相关的操作全都放在service_list和action_list这两个链表中,然后我们会使用其他的方法,把我们的在初始化过程中需要执行的服务和命令添加到我们的action_queue链表中,最后由我们的init进程根据action_queue中服务和命令来执行相关的操作,我们代开代码来看一下init_parse_config_file函数
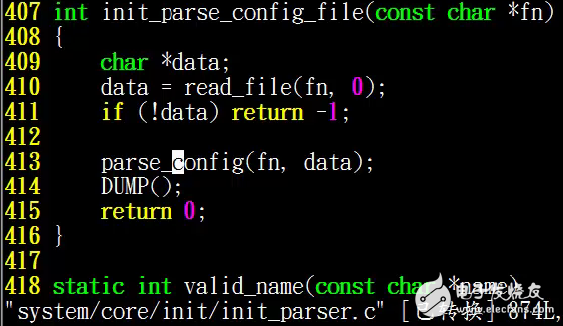
他首先会打开我们这个文件,然后调用parse_config这个函数来解析这个文件,这个解析文件就是一个简单的语法解析器
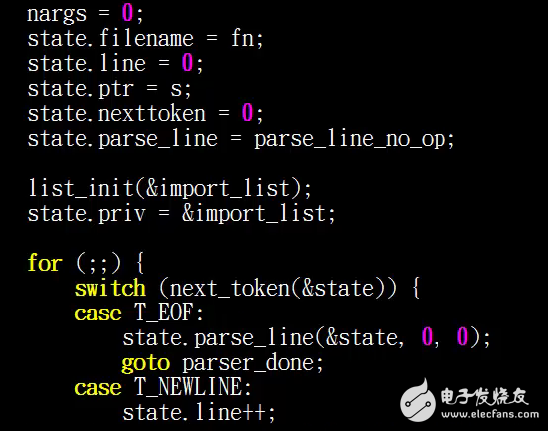
在这里会有一个parse_state变量,我们后边在看,我们再看他解析过程中,首先就是调用我们的next_token ,next_token就是一个语句中的最小单元,我们再看一下我们的启动脚本

我们一个最小的单元就是指:on 、early-init 、write 、、proc/1/oom_adj 、-16 他们都是独立的单元,下面我们来看一下我们的next_token,
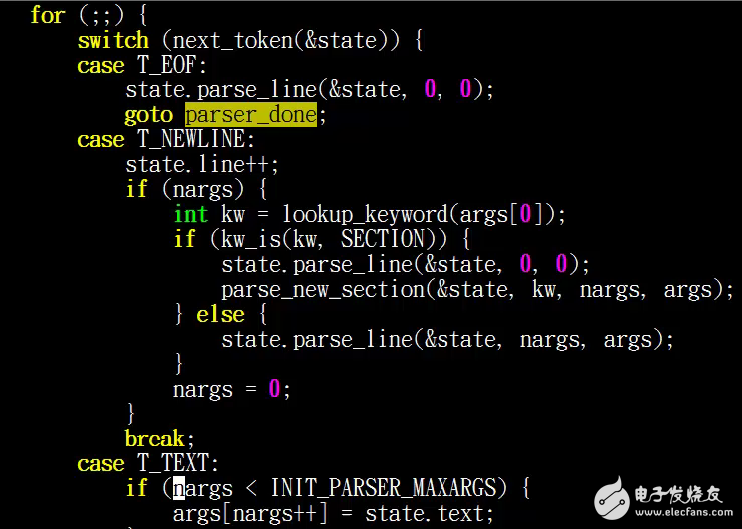
他一共有三个返回值,第一个是T_EOF,也就是我们的文件解析完成,完成之后就走到了我们的parser_done
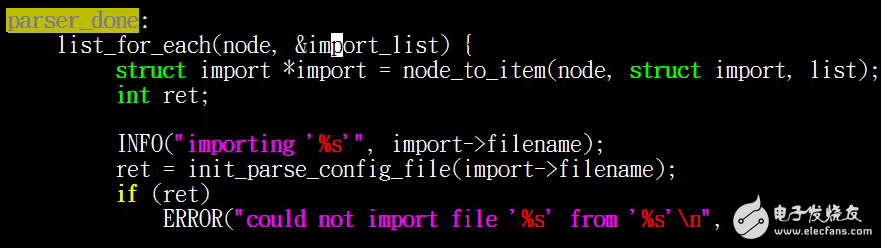
他在这里就会把我们的import_list列表中所包含的其他的init脚本,在这里重新做解析,这就是在解析完之后他会导入其他的脚本
那我们的第二个返回值是T_NEWLINE,他在执行的过程中会首先看一下我们的关键字,也就是我们返回的第一个args,如果说第一个args是SECTION的话,那么他就会调用state.parse_line做一个解析,然后调用parse_new_section这个函数,稍后我们会看到这两个函数的意思
我们再来看一下第三个返回值,他是T_TEXT,他在这里就相当于我们命令中的一个参数。
下面我们来看一下我们next_token的一个具体实现
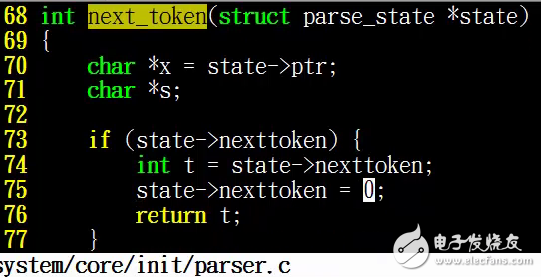
他的解析过程是根据我们这里的变量parse_state来决定的,这里的parse_state有一个nexttoken ,这个nexttoken保存着我们解析的一个状态,如果说我们在上一次解析中把这个nexttoken给设置了,那么我们会首先执行上次所设置的状态,在这个状态中会直接返回,然后把这个状态直接清0,交给我们的parse_config,而我们没有设置这个状态呢,我们就会真正的去解析这个脚本

他解析的过程呢是一个字符一个字符的去判断,如果我们遇到的是0,那么我们就认为这个文件解析完成,返回一个T_EOF,如果我们遇到一个“\n”,那么就说明我们遇到了一个新的一行,这时就会返回一个T_NEWLINE,如果我们遇到其他字符可以继续操作,如果说我们遇到一个#号,这个是一个注释行,我们可以把它忽略,然后返回一个新的行。
其实从第一个for循环我们可以看到,我们这个for循环的作用就是把我们脚本中没用的字符,比如说\n 、\t 、以及无用的空格等给清除掉,过滤掉,因为我们调用一次肯定是上次遇到了一个完整的单词,或者说遇到了一个完整的行,进来之后呢,他里边第一个必须遇到一个正常的字母,然后才能说明他有一个新的token,这是我们第一个for循环的作用。如果我们在for循环最后遇到一个字符,就会调到我们的text标签中执行,下面我们来看一下我们的text
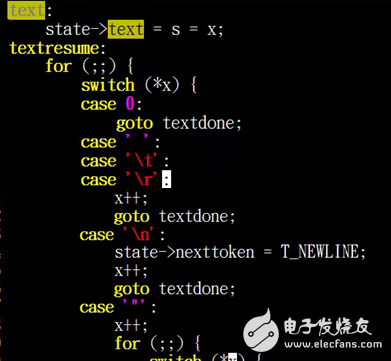
在这里主要是解析我们最小的一个token,如果说我们上一个遇到了一个字符,那么他在这里就会解析这个单词的结束,如果下一个是0的话,他在这里就会走一下textdone ,如果我们遇到的是空格、\n 、 \t 、\r我们就说我们遇到了一个完整的单词 ,这个单词就会返回,如果遇到\n ,我们可以看到我们在这里设置了nexttoken,是T_NEWLINE,然后在这里也走到了textdone,如果我们遇到了一个引号,那么它就会去做一些相关的事情,接下来来我们来看一下我们的textdone
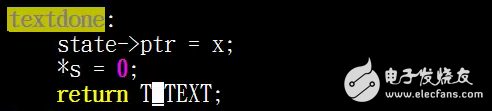
在这里textdone他就是标记了这个字符的一个级数位置,然后返回了一个T_TEXT,也就是返回了一个完整的单词,这就是我开门nexttoken所做的一个操作,了解了nexttoken之后呢,我们就知道了解析的一个最小的元素是如何来生成的,然后我们会根据返回值做一些不同的操作,如果说我们返回的是一个T_NEWLINE,那么我们就可以查找一下我们下一行是一个什么样的语法,下面我们来看一下lookup_keyword的实现,我们将下面的内容放到下一期来学习。
顶!d=====( ̄▽ ̄*)b一下