小白也能理解的内存技术讲解
计算机系统性能的改善,不仅仅取决于cpu主频的提升,还与cpu和内存之间的存取速度密切相关。在经常帮别人推荐电脑配置的时候,我常常会被别人问起,不同类型内存之间的区别。每一次我都很不耐烦告诉他们,自己去网上搜,网上很多这样的文章。可是很多人最后还是回来找我,说“看不懂那些文章”。然后我自己尝试着上网搜一搜,发现除了最经典的当初赵效民先生写那篇内存技术终极指南(但这篇文章一点都不适合新手),其他文章都是要不罗嗦半天不知所云,要不就是陷入技术名词的泥沼让初学者不知所云,或者就是对于历史和未来侃侃其谈完了不懂还是不懂懂的又觉得没意思。
曾经看过老外写的入门文章,觉得很多写得非常深入浅出,所以现在也尝试写一些基础的东西就算是小白也能轻松理解,不追求把技术讲得多么出神入化,只求能让大多数人明白,现在你能看到,和听到的各种内存,基本差异在哪里呢?
好,由于我们不是要去回顾内存历史,所以什么快页,edo的内存统统都不说,直接从SDR开始。基本上,理解SDR是理解后面所有内存的基础,让我们看一个架构:
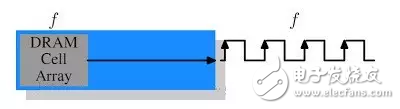
咱们这样来想,前面这个Cell Array呢,就是存数据的地方,它的作用就是不断往内存的总线上输出它其中的内容,当然这个Cell的数量肯定不只有一个,不过这里我们就以一个举例子了。它传输的速度有多快呢?这个当然就取决于具体内存的型号,不过有一点是可以肯定的,那就是这个Cell的工作频率,和连接它的总线的数据传输频率是一样的(图中的f),也就是说,假如这个Cell以每秒30Mb的速度往外发数据,那么这个总线的传输速度就是30Mb,而且内存传输是同步的,也就是说,图中的每个时钟上升沿,就是数据传输的时刻,而数据也只在每个时钟上升沿才进行传输。
SDR的结构很简单,所以思考也很简单,比如我们想提高SDR的速度,怎么弄?那就是提高频率呗,频率提高了,传输速度就上去了。但事实上,频率提高伴随的是能量消耗的提高,而且还需要提高工作电压来维持系统的稳定性。前面我们说到Cell不止一个,实际上Cell数量是很多的,这样的话,代价就太大了。怎么办?DDR就因此登场了。让我们看看DDR的示意图:
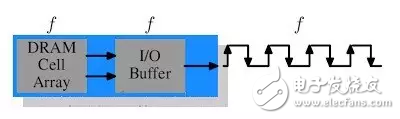
和SDR比多了一个什么?输入输出的缓冲,还有一个变化,就是时钟沿变了。其实从DDR的名称我们就可以知道,它的数据传输率应该是SDR的两倍。怎么做到的呢?那就是我们不仅在时钟上升沿传数据,还在时钟下降沿传数据。
说起来貌似很简单,但肯定有朋友会想到一个问题:你说变两倍就变两倍啊?工作频率f不变,哪里来的两倍的数据量呢?对了,所以图中才会多出来一个buffer。简单来说,在设计中用了一个小技巧:我们对两个Dram Cells使用相同的列地址线,这样就可以平行访问它们,并将数据从双行的数据总线中传出,这样,buffer得到的数据量就是两倍了。
这种设计的改变,代价是非常小的,却对内存的性能有很大的提升。
接下来就该谈DDR2了。其实DDR2所做出来的改进,也不是什么革新性的东西,看图就明白了:
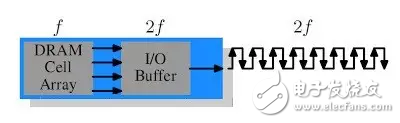
就是把buffer和总线的工作频率提高了一倍。频率提高一倍,就意味着带宽提高一倍。有朋友有疑问了,你刚才不是说“频率提高伴随的是能量消耗和工作电压的提高”,代价很大么?是的,但是请注意,带宽的提高,在这里是取决于buffer的频率提高,事实上,Cell array的频率是没变的,换句话说,我们只是提高了内存中某个适合被提高频率的部件的频率,相对于内存模组来说,这只是一个小部件,提高它的频率不会消耗很大的能量,代价小得多。
接下来的DDR3就很好分析了(这里是说的标准DDR3,不是显卡上用的GDDR3)。同样看图
我们还是对IO buffer的line做手脚,这次把它的频率提升到4倍,带宽也到了4倍,请注意,此时Cell array的频率(核心频率)还是不变的。
当然,DDR3的改进要比当年DDR2的改进还是要大一些的,比如,它把工作电压从1.8V降到了1.5V,因此电能消耗相对就减少了。除此以外,核心die尺寸的减小,也给DDR3的功耗带来了可观的节省,换句话说,我们可以用相同的功耗,来获得更高的频率了。
好,讲到这里,估计很多朋友都会得到这么一个印象:改进嘛,那就是绕着弯子去提高频率,你加buffer不也是为了“代价更好”地提高频率么?对,这是因为带宽的大小,本质上就是由频率所决定的。但是这并不意味着频率可以无限制提升,由于总线频率越高,我们能利用的总线并行化程度就越低。我们拿DDR2举例子,DDR2内存有240pin的引脚,所有与数据和地址总线相连的引脚,PCB上布线的长度都必须几乎相等,这无疑极大增加了设计难度。更糟糕的是,DDR2规范规定了,每个通道只能有两个模组,DDR3呢?这玩意的数据传输率太高了,所以它每通道的内存模块数量已经被限制到一个了。
这给系统带来的直接影响就是:我们可用的最大内存容量变小了。要知道,内存控制器(大部分在北桥中)能搞定的内存通道数量是有限的,多了就控制不过来了,很多的主板,都最大只支持4个DDR2或者DDR3模组,想一想,4条内存(假设都是单模组),你能得到多少容量?要知道理论上,32位处理器也能支持64G的内存啊,别说64位了(不谈操作系统影响,反正至少Linux是没有限制的)。
当然我们也可以增加外部内存控制器——如果你能忍受巨大的延迟的话——所以通常这都是很不现实的。有没有别的解决办法呢?有,比如就像AMD已经做了的那样,或者Intel准备在CSI总线中做的那样——把内存控制器集成到CPU中,这样,由于CPU直接和内存相连,我们能够利用的内存Ranks数目,实际上和CPU的数量直接联系,CPU数量越多,内存带宽越高,形成类似于多核系统中的NUMA架构。这个过程根本就没有北桥复杂性的什么事。
问题解决了?没有。NUMA架构不是万能的,它有它的缺陷,只不过这里我们暂时不用管它。更何况,还有信号干扰之类的各种各样的问题潜伏着,随时准备出来兴妖作怪。
实际上,目前的学术界还在为解决“如何更好扩展内存带宽”而努力,比较有成效的,就是Intel推出的FB-DRAM。这里,我尽量用比较通俗的语言来大体解释一下FB-DRAM。
首先,FB-DRAM的存储芯片和现在最流行的DDR2,3是一个东西,那具体的差别在哪里呢?我们别去研究什么AMB之类的东西,说白点,主要就是和内存控制器的连接关系。DDR系列内存中,我们传输数据用的是并行总线,在这里变了,是串行总线。好处是什么?大家都是电子爱好者,想想SATA,PCI Express这些改进,再想想当年号称内存技术之王的Rambus…….囧。如果直接讲,串行总线的最大好处就是可以把频率提升到很高很高的话,似乎有点太空话了,所以稍微说几点具体优势:
1、每通道可以有更多的模组存在
2、北桥或者内存控制器能使用更多的通道
3、可以双线全双工
4、设计成差分总线的成本很低,可以进一步减少干扰
如果还是难以明白,我再说明白一点:FB-DRAM引脚只有69根,用了它,每个内存通道允许有8个内存模组的存在。由于引脚数目的降低,北桥现在可以连接6个内存通道了,针对每个通道的主板布线的要求度和复杂度也大幅降低。
算一算现在的最大内存容量?增加了12倍。带宽呢?和DDR2-800比,增加了4倍。付出的代价?那就是由于串行频率过高,驱动总线的能耗相对较大。