第9章 BasicMathFunctions的使用(二)
本期教程主要讲基本函数中的相反数,偏移,位移,减法和比例因子。
9.1 相反数(VectorNegate)
9.2 求和(VectorOffset)
9.3 点乘(VectorShift)
9.4 减法(VectorSub)
9.5 比例因子(VectorScale)
9.6 BasicMathFunctions的重要说明
9.7 总结
9.1 相反数(Vector Negate)
这部分函数主要用于求相反数,公式描述如下:
pDst[n] = -pSrc[n], 0 <= n < blockSize.
特别注意,这部分函数支持目标指针和源指针指向相同的缓冲区。
9.1.1 arm_negate_f32
这个函数用于求32位浮点数的相反数,源代码分析如下:
- /**
- * @brief Negates the elements of a floating-point vector.
- * @param[in] *pSrc points to the input vector
- * @param[out] *pDst points to the output vector
- * @param[in] blockSize number of samples in the vector
- * [url=home.php?mod=space&uid=1141835]@Return[/url] none.
- */
-
- void arm_negate_f32(
- float32_t * pSrc,
- float32_t * pDst,
- uint32_t blockSize)
- {
- uint32_t blkCnt; /* loop counter */
-
-
- #ifndef ARM_MATH_CM0_FAMILY
-
- /* Run the below code for Cortex-M4 and Cortex-M3 */
- float32_t in1, in2, in3, in4; /* temporary variables */
-
- /*loop Unrolling */
- blkCnt = blockSize >> 2u;
-
- /* First part of the processing with loop unrolling. Compute 4 outputs at a time.
- ** a second loop below computes the remaining 1 to 3 samples. */
- while(blkCnt > 0u)
- {
- /* read inputs from source */
- in1 = *pSrc;
- in2 = *(pSrc + 1);
- in3 = *(pSrc + 2);
- in4 = *(pSrc + 3);
-
- /* negate the input */ (1)
- in1 = -in1;
- in2 = -in2;
- in3 = -in3;
- in4 = -in4;
-
- /* store the result to destination */
- *pDst = in1;
- *(pDst + 1) = in2;
- *(pDst + 2) = in3;
- *(pDst + 3) = in4;
-
- /* update pointers to process next samples */
- pSrc += 4u;
- pDst += 4u;
-
- /* Decrement the loop counter */
- blkCnt--;
- }
-
- /* If the blockSize is not a multiple of 4, compute any remaining output samples here.
- ** No loop unrolling is used. */
- blkCnt = blockSize % 0x4u;
-
- #else
-
- /* Run the below code for Cortex-M0 */
-
- /* Initialize blkCnt with number of samples */
- blkCnt = blockSize;
-
- #endif /* #ifndef ARM_MATH_CM0_FAMILY */
-
- while(blkCnt > 0u)
- {
- /* C = -A */
- /* Negate and then store the results in the destination buffer. */
- *pDst++ = -*pSrc++;
-
- /* Decrement the loop counter */
- blkCnt--;
- }
- }
1. 浮点数的相反数求解比较简单,直接在相应的变量前加上负号即可。
9.1.2 arm_negate_q31
这个函数用于求32位定点数的相反数,源代码分析如下:
- /**
- * @brief Negates the elements of a Q31 vector.
- * @param[in] *pSrc points to the input vector
- * @param[out] *pDst points to the output vector
- * @param[in] blockSize number of samples in the vector
- * @return none.
- *
- * <b>Scaling and Overflow Behavior:</b> (1)
- * \par
- * The function uses saturating arithmetic.
- * The Q31 value -1 (0x80000000) will be saturated to the maximum allowable positive value 0x7FFFFFFF.
- */
-
- void arm_negate_q31(
- q31_t * pSrc,
- q31_t * pDst,
- uint32_t blockSize)
- {
- q31_t in; /* Temporary variable */
- uint32_t blkCnt; /* loop counter */
-
- #ifndef ARM_MATH_CM0_FAMILY
-
- /* Run the below code for Cortex-M4 and Cortex-M3 */
- q31_t in1, in2, in3, in4;
-
- /*loop Unrolling */
- blkCnt = blockSize >> 2u;
-
- /* First part of the processing with loop unrolling. Compute 4 outputs at a time.
- ** a second loop below computes the remaining 1 to 3 samples. */
- while(blkCnt > 0u)
- {
- /* C = -A */
- /* Negate and then store the results in the destination buffer. */
- in1 = *pSrc++;
- in2 = *pSrc++;
- in3 = *pSrc++;
- in4 = *pSrc++;
-
- *pDst++ = __QSUB(0, in1); (2)
- *pDst++ = __QSUB(0, in2);
- *pDst++ = __QSUB(0, in3);
- *pDst++ = __QSUB(0, in4);
-
- /* Decrement the loop counter */
- blkCnt--;
- }
-
- /* If the blockSize is not a multiple of 4, compute any remaining output samples here.
- ** No loop unrolling is used. */
- blkCnt = blockSize % 0x4u;
-
- #else
-
- /* Run the below code for Cortex-M0 */
-
- /* Initialize blkCnt with number of samples */
- blkCnt = blockSize;
-
- #endif /* #ifndef ARM_MATH_CM0_FAMILY */
-
-
- while(blkCnt > 0u)
- {
- /* C = -A */
- /* Negate and then store the result in the destination buffer. */
- in = *pSrc++;
- *pDst++ = (in == INT32_MIN) ? INT32_MAX : -in;
-
- /* Decrement the loop counter */
- blkCnt--;
- }
- }
1. 这个函数使用了饱和运算。
饱和运算数值0x80000000将变成0x7FFFFFFF。
2. 饱和运算__QSUB我们在上一章已经详细讲述了,这就就是实现数值0减去相应的参数变量。
9.1.3 arm_negate_q15
这个函数用于求16位定点数的相反数,源代码分析如下:
- /**
- * @brief Negates the elements of a Q15 vector.
- * @param[in] *pSrc points to the input vector
- * @param[out] *pDst points to the output vector
- * @param[in] blockSize number of samples in the vector
- * @return none.
- *
- * \par Conditions for optimum performance
- * Input and output buffers should be aligned by 32-bit
- *
- *
- * <b>Scaling and Overflow Behavior:</b> (1)
- * \par
- * The function uses saturating arithmetic.
- * The Q15 value -1 (0x8000) will be saturated to the maximum allowable positive value 0x7FFF.
- */
-
- void arm_negate_q15(
- q15_t * pSrc,
- q15_t * pDst,
- uint32_t blockSize)
- {
- uint32_t blkCnt; /* loop counter */
- q15_t in;
-
- #ifndef ARM_MATH_CM0_FAMILY
-
- /* Run the below code for Cortex-M4 and Cortex-M3 */
-
- q31_t in1, in2; /* Temporary variables */
-
-
- /*loop Unrolling */
- blkCnt = blockSize >> 2u;
-
- /* First part of the processing with loop unrolling. Compute 4 outputs at a time.
- ** a second loop below computes the remaining 1 to 3 samples. */
- while(blkCnt > 0u)
- {
- /* C = -A */
- /* Read two inputs at a time */ (2)
- in1 = _SIMD32_OFFSET(pSrc);
- in2 = _SIMD32_OFFSET(pSrc + 2);
-
- /* negate two samples at a time */ (3)
- in1 = __QSUB16(0, in1);
-
- /* negate two samples at a time */
- in2 = __QSUB16(0, in2);
-
- /* store the result to destination 2 samples at a time */ (4)
- _SIMD32_OFFSET(pDst) = in1;
- /* store the result to destination 2 samples at a time */
- _SIMD32_OFFSET(pDst + 2) = in2;
-
-
- /* update pointers to process next samples */
- pSrc += 4u;
- pDst += 4u;
-
- /* Decrement the loop counter */
- blkCnt--;
- }
-
- /* If the blockSize is not a multiple of 4, compute any remaining output samples here.
- ** No loop unrolling is used. */
- blkCnt = blockSize % 0x4u;
-
- #else
-
- /* Run the below code for Cortex-M0 */
-
- /* Initialize blkCnt with number of samples */
- blkCnt = blockSize;
-
- #endif /* #ifndef ARM_MATH_CM0_FAMILY */
-
- while(blkCnt > 0u)
- {
- /* C = -A */
- /* Negate and then store the result in the destination buffer. */
- in = *pSrc++;
- *pDst++ = (in == (q15_t) 0x8000) ? 0x7fff : -in;
-
- /* Decrement the loop counter */
- blkCnt--;
- }
- }
1. 这个函数使用了饱和运算。
饱和运算数值0x8000将变成0x7FFF。
2. 一次读取两个Q15格式的数据。
3. 由于__QSUB是SIMD指令,这里可以实现一次计算两个Q15数据的相反数。
4. 这里实现一次赋值两个Q15数据。
9.1.4 arm_negate_q7
这个函数用于求8位定点数的相反数,源代码分析如下:
- /**
- * @brief Negates the elements of a Q7 vector.
- * @param[in] *pSrc points to the input vector
- * @param[out] *pDst points to the output vector
- * @param[in] blockSize number of samples in the vector
- * @return none.
- *
- * <b>Scaling and Overflow Behavior:</b> (1)
- * \par
- * The function uses saturating arithmetic.
- * The Q7 value -1 (0x80) will be saturated to the maximum allowable positive value 0x7F.
- */
-
- void arm_negate_q7(
- q7_t * pSrc,
- q7_t * pDst,
- uint32_t blockSize)
- {
- uint32_t blkCnt; /* loop counter */
- q7_t in;
-
- #ifndef ARM_MATH_CM0_FAMILY
-
- /* Run the below code for Cortex-M4 and Cortex-M3 */
- q31_t input; /* Input values1-4 */
- q31_t zero = 0x00000000; (2)
-
-
- /*loop Unrolling */
- blkCnt = blockSize >> 2u;
-
- /* First part of the processing with loop unrolling. Compute 4 outputs at a time.
- ** a second loop below computes the remaining 1 to 3 samples. */
- while(blkCnt > 0u)
- {
- /* C = -A */
- /* Read four inputs */
- input = *__SIMD32(pSrc)++; (3)
-
- /* Store the Negated results in the destination buffer in a single cycle by packing the results */
- *__SIMD32(pDst)++ = __QSUB8(zero, input); (4)
-
- /* Decrement the loop counter */
- blkCnt--;
- }
-
- /* If the blockSize is not a multiple of 4, compute any remaining output samples here.
- ** No loop unrolling is used. */
- blkCnt = blockSize % 0x4u;
-
- #else
-
- /* Run the below code for Cortex-M0 */
-
- /* Initialize blkCnt with number of samples */
- blkCnt = blockSize;
-
- #endif /* #ifndef ARM_MATH_CM0_FAMILY */
-
- while(blkCnt > 0u)
- {
- /* C = -A */
- /* Negate and then store the results in the destination buffer. */ \
- in = *pSrc++;
- *pDst++ = (in == (q7_t) 0x80) ? 0x7f : -in;
-
- /* Decrement the loop counter */
- blkCnt--;
- }
- }
1. 这个函数使用了饱和运算。
饱和运算数值0x80将变成0x7F。
2. 给局部变量赋初值,防止默认初始值不是0,所以从某种意义上来说,给变量赋初值是很有必要的。
3. 一次读取4个Q7格式的数据到input里面。
4. 通过__QSUB8实现一次计算四个Q7格式数据的相反数。
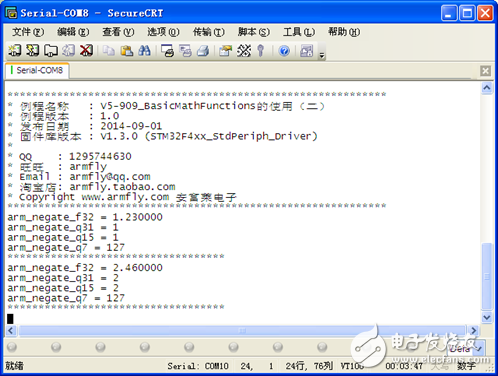
9.1.5 实例讲解
实验目的:
1. 四种类型数据的相反数。
实验内容:
1. 按下K1键, 串口打印输出结果
实验现象:
通过窗口上位机软件SecureCRT(V5光盘里面有此软件)查看打印信息现象如下:
程序设计:
9.2 偏移(Vector Offset)
这部分函数主要用于求相反数,公式描述如下:
pDst[n] = pSrc[n] + offset, 0 <= n < blockSize.
注意,这部分函数支持目标指针和源指针指向相同的缓冲区。
9.2.1 arm_offset_f32
这个函数用于求32位浮点数的偏移,源代码分析如下:
- /**
- * @brief Adds a constant offset to a floating-point vector.
- * @param[in] *pSrc points to the input vector
- * @param[in] offset is the offset to be added
- * @param[out] *pDst points to the output vector
- * @param[in] blockSize number of samples in the vector
- * @return none.
- */
- void arm_offset_f32(
- float32_t * pSrc,
- float32_t offset,
- float32_t * pDst,
- uint32_t blockSize)
- {
- uint32_t blkCnt; /* loop counter */
-
- #ifndef ARM_MATH_CM0_FAMILY
-
- /* Run the below code for Cortex-M4 and Cortex-M3 */
- float32_t in1, in2, in3, in4;
-
- /*loop Unrolling */
- blkCnt = blockSize >> 2u;
-
- /* First part of the processing with loop unrolling. Compute 4 outputs at a time.
- ** a second loop below computes the remaining 1 to 3 samples. */
- while(blkCnt > 0u)
- {
- /* C = A + offset */ (1)
- /* Add offset and then store the results in the destination buffer. */
- /* read samples from source */
- in1 = *pSrc;
- in2 = *(pSrc + 1);
-
- /* add offset to input */
- in1 = in1 + offset;
-
- /* read samples from source */
- in3 = *(pSrc + 2);
-
- /* add offset to input */
- in2 = in2 + offset;
-
- /* read samples from source */
- in4 = *(pSrc + 3);
-
- /* add offset to input */
- in3 = in3 + offset;
-
- /* store result to destination */
- *pDst = in1;
-
- /* add offset to input */
- in4 = in4 + offset;
-
- /* store result to destination */
- *(pDst + 1) = in2;
-
- /* store result to destination */
- *(pDst + 2) = in3;
-
- /* store result to destination */
- *(pDst + 3) = in4;
-
- /* update pointers to process next samples */
- pSrc += 4u;
- pDst += 4u;
-
- /* Decrement the loop counter */
- blkCnt--;
- }
-
- /* If the blockSize is not a multiple of 4, compute any remaining output samples here.
- ** No loop unrolling is used. */
- blkCnt = blockSize % 0x4u;
-
- #else
-
- /* Run the below code for Cortex-M0 */
-
- /* Initialize blkCnt with number of samples */
- blkCnt = blockSize;
-
- #endif /* #ifndef ARM_MATH_CM0_FAMILY */
-
- while(blkCnt > 0u)
- {
- /* C = A + offset */
- /* Add offset and then store the result in the destination buffer. */
- *pDst++ = (*pSrc++) + offset;
-
- /* Decrement the loop counter */
- blkCnt--;
- }
- }
1. 浮点数的偏移值求解比较简单,加上相应的偏移值并赋值给目标变量即可。
9.2.2 arm_offset_q31
这个函数用于求32位定点数的偏移值,源代码分析如下:
- /**
- * @brief Adds a constant offset to a Q31 vector.
- * @param[in] *pSrc points to the input vector
- * @param[in] offset is the offset to be added
- * @param[out] *pDst points to the output vector
- * @param[in] blockSize number of samples in the vector
- * @return none.
- *
- * <b>Scaling and Overflow Behavior:</b> (1)
- * \par
- * The function uses saturating arithmetic.
- * Results outside of the allowable Q31 range [0x80000000 0x7FFFFFFF] are saturated.
- */
-
- void arm_offset_q31(
- q31_t * pSrc,
- q31_t offset,
- q31_t * pDst,
- uint32_t blockSize)
- {
- uint32_t blkCnt; /* loop counter */
-
- #ifndef ARM_MATH_CM0_FAMILY
-
- /* Run the below code for Cortex-M4 and Cortex-M3 */
- q31_t in1, in2, in3, in4;
-
-
- /*loop Unrolling */
- blkCnt = blockSize >> 2u;
-
- /* First part of the processing with loop unrolling. Compute 4 outputs at a time.
- ** a second loop below computes the remaining 1 to 3 samples. */
- while(blkCnt > 0u)
- {
- /* C = A + offset */
- /* Add offset and then store the results in the destination buffer. */
- in1 = *pSrc++;
- in2 = *pSrc++;
- in3 = *pSrc++;
- in4 = *pSrc++;
-
- *pDst++ = __QADD(in1, offset); (2)
- *pDst++ = __QADD(in2, offset);
- *pDst++ = __QADD(in3, offset);
- *pDst++ = __QADD(in4, offset);
-
- /* Decrement the loop counter */
- blkCnt--;
- }
-
- /* If the blockSize is not a multiple of 4, compute any remaining output samples here.
- ** No loop unrolling is used. */
- blkCnt = blockSize % 0x4u;
-
- while(blkCnt > 0u)
- {
- /* C = A + offset */
- /* Add offset and then store the result in the destination buffer. */
- *pDst++ = __QADD(*pSrc++, offset);
-
- /* Decrement the loop counter */
- blkCnt--;
- }
-
- #else
-
- /* Run the below code for Cortex-M0 */
-
- /* Initialize blkCnt with number of samples */
- blkCnt = blockSize;
-
- while(blkCnt > 0u)
- {
- /* C = A + offset */
- /* Add offset and then store the result in the destination buffer. */
- *pDst++ = (q31_t) clip_q63_to_q31((q63_t) * pSrc++ + offset);
-
- /* Decrement the loop counter */
- blkCnt--;
- }
-
- #endif /* #ifndef ARM_MATH_CM0_FAMILY */
-
- }
1. 这个函数使用了饱和运算。
饱和运算数值0x80000000将变成0x7FFFFFFF。
2. 指令__QADD我们在上章教程中已经讲解过,这里是实现两个参数相加。
9.2.3 arm_offset_q15
这个函数用于求16位定点数的偏移,源代码分析如下:
- /**
- * @brief Adds a constant offset to a Q15 vector.
- * @param[in] *pSrc points to the input vector
- * @param[in] offset is the offset to be added
- * @param[out] *pDst points to the output vector
- * @param[in] blockSize number of samples in the vector
- * @return none.
- *
- * <b>Scaling and Overflow Behavior:</b> (1)
- * \par
- * The function uses saturating arithmetic.
- * Results outside of the allowable Q15 range [0x8000 0x7FFF] are saturated.
- */
-
- void arm_offset_q15(
- q15_t * pSrc,
- q15_t offset,
- q15_t * pDst,
- uint32_t blockSize)
- {
- uint32_t blkCnt; /* loop counter */
-
- #ifndef ARM_MATH_CM0_FAMILY
-
- /* Run the below code for Cortex-M4 and Cortex-M3 */
- q31_t offset_packed; /* Offset packed to 32 bit */
-
-
- /*loop Unrolling */
- blkCnt = blockSize >> 2u;
-
- /* Offset is packed to 32 bit in order to use SIMD32 for addition */
- offset_packed = __PKHBT(offset, offset, 16); (2)
-
- /* First part of the processing with loop unrolling. Compute 4 outputs at a time.
- ** a second loop below computes the remaining 1 to 3 samples. */
- while(blkCnt > 0u)
- {
- /* C = A + offset */
- /* Add offset and then store the results in the destination buffer, 2 samples at a time. */
- *__SIMD32(pDst)++ = __QADD16(*__SIMD32(pSrc)++, offset_packed); (3)
- *__SIMD32(pDst)++ = __QADD16(*__SIMD32(pSrc)++, offset_packed);
-
- /* Decrement the loop counter */
- blkCnt--;
- }
-
- /* If the blockSize is not a multiple of 4, compute any remaining output samples here.
- ** No loop unrolling is used. */
- blkCnt = blockSize % 0x4u;
-
- while(blkCnt > 0u)
- {
- /* C = A + offset */
- /* Add offset and then store the results in the destination buffer. */
- *pDst++ = (q15_t) __QADD16(*pSrc++, offset);
-
- /* Decrement the loop counter */
- blkCnt--;
- }
-
- #else
-
- /* Run the below code for Cortex-M0 */
-
- /* Initialize blkCnt with number of samples */
- blkCnt = blockSize;
-
- while(blkCnt > 0u)
- {
- /* C = A + offset */
- /* Add offset and then store the results in the destination buffer. */
- *pDst++ = (q15_t) __SSAT(((q31_t) * pSrc++ + offset), 16);
-
- /* Decrement the loop counter */
- blkCnt--;
- }
-
- #endif /* #ifndef ARM_MATH_CM0_FAMILY */
-
- }
1. 这个函数使用了饱和运算。
饱和运算数值0x8000将变成0x7FFF。
2. 将两个Q15格式的变量合并成一个Q31格式的数据,方便指令__QADD16的调用。
3. 由于__QADD16是SIMD指令,这里调用一次就能实现两个Q15格式数据的计算。
9.2.4 arm_offset_q7
这个函数用于求8位定点数的偏移,源代码分析如下:
- /**
- * @brief Adds a constant offset to a Q7 vector.
- * @param[in] *pSrc points to the input vector
- * @param[in] offset is the offset to be added
- * @param[out] *pDst points to the output vector
- * @param[in] blockSize number of samples in the vector
- * @return none.
- *
- * <b>Scaling and Overflow Behavior:</b> (1)
- * \par
- * The function uses saturating arithmetic.
- * Results outside of the allowable Q7 range [0x80 0x7F] are saturated.
- */
-
- void arm_offset_q7(
- q7_t * pSrc,
- q7_t offset,
- q7_t * pDst,
- uint32_t blockSize)
- {
- uint32_t blkCnt; /* loop counter */
-
- #ifndef ARM_MATH_CM0_FAMILY
-
- /* Run the below code for Cortex-M4 and Cortex-M3 */
- q31_t offset_packed; /* Offset packed to 32 bit */
-
-
- /*loop Unrolling */
- blkCnt = blockSize >> 2u;
-
- /* Offset is packed to 32 bit in order to use SIMD32 for addition */ (2)
- offset_packed = __PACKq7(offset, offset, offset, offset);
-
- /* First part of the processing with loop unrolling. Compute 4 outputs at a time.
- ** a second loop below computes the remaining 1 to 3 samples. */
- while(blkCnt > 0u)
- {
- /* C = A + offset */
- /* Add offset and then store the results in the destination bufferfor 4 samples at a time. */
- *__SIMD32(pDst)++ = __QADD8(*__SIMD32(pSrc)++, offset_packed); (3)
-
- /* Decrement the loop counter */
- blkCnt--;
- }
-
- /* If the blockSize is not a multiple of 4, compute any remaining output samples here.
- ** No loop unrolling is used. */
- blkCnt = blockSize % 0x4u;
-
- while(blkCnt > 0u)
- {
- /* C = A + offset */
- /* Add offset and then store the result in the destination buffer. */
- *pDst++ = (q7_t) __SSAT(*pSrc++ + offset, 8);
-
- /* Decrement the loop counter */
- blkCnt--;
- }
-
- #else
-
- /* Run the below code for Cortex-M0 */
-
- /* Initialize blkCnt with number of samples */
- blkCnt = blockSize;
-
- while(blkCnt > 0u)
- {
- /* C = A + offset */
- /* Add offset and then store the result in the destination buffer. */
- *pDst++ = (q7_t) __SSAT((q15_t) * pSrc++ + offset, 8);
-
- /* Decrement the loop counter */
- blkCnt--;
- }
-
- #endif /* #ifndef ARM_MATH_CM0_FAMILY */
-
- }
1. 这个函数使用了饱和运算。
饱和运算数值0x80将变成0x7F。
2. 通过__PACKq7将4个Q7格式的数据合并成一个Q31格式的数据。
3. 由于__QADD8是SIMD指令,这里调用一次就能实现四个Q8格式数据的计算。
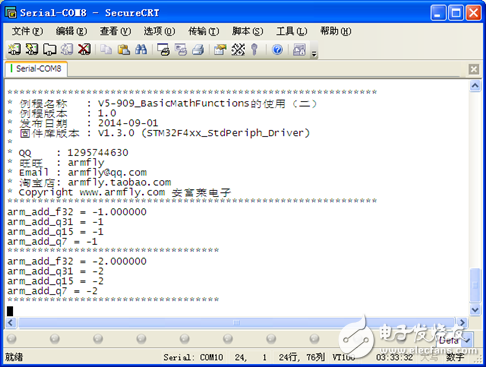
9.2.5 实例讲解
实验目的:
1. 四种类型数据的相反数。
实验内容:
1. 按下K2键, 串口打印输出结果
实验现象:
通过窗口上位机软件SecureCRT(V5光盘里面有此软件)查看打印信息现象如下:
程序设计:
9.3 位移(Vector Shift)
这部分函数主要用于实现位移,公式描述如下:
pDst[n] = pSrc[n] << shift, 0 <= n < blockSize.
注意,这部分函数支持目标指针和源指针指向相同的缓冲区。
9.3.1 arm_shift_q31
这个函数用于求32位定点数的位移,源代码分析如下:
- /**
- * @brief Shifts the elements of a Q31 vector a specified number of bits.
- * @param[in] *pSrc points to the input vector
- * @param[in] shiftBits number of bits to shift.
- * A positive value shifts left; a negative value shifts right. (1)
- * @param[out] *pDst points to the output vector
- * @param[in] blockSize number of samples in the vector
- * @return none.
- *
- *
- * <b>Scaling and Overflow Behavior:</b> (2)
- * \par
- * The function uses saturating arithmetic.
- * Results outside of the allowable Q31 range [0x80000000 0x7FFFFFFF] will be saturated.
- */
-
- void arm_shift_q31(
- q31_t * pSrc,
- int8_t shiftBits,
- q31_t * pDst,
- uint32_t blockSize)
- {
- uint32_t blkCnt; /* loop counter */
- uint8_t sign = (shiftBits & 0x80); /* Sign of shiftBits */ (3)
-
- #ifndef ARM_MATH_CM0_FAMILY
-
- q31_t in1, in2, in3, in4; /* Temporary input variables */
- q31_t out1, out2, out3, out4; /* Temporary output variables */
-
- /*loop Unrolling */
- blkCnt = blockSize >> 2u;
-
-
- if(sign == 0u) (4)
- {
- /* First part of the processing with loop unrolling. Compute 4 outputs at a time.
- ** a second loop below computes the remaining 1 to 3 samples. */
- while(blkCnt > 0u)
- {
- /* C = A << shiftBits */
- /* Shift the input and then store the results in the destination buffer. */
- in1 = *pSrc;
- in2 = *(pSrc + 1);
- out1 = in1 << shiftBits;
- in3 = *(pSrc + 2);
- out2 = in2 << shiftBits;
- in4 = *(pSrc + 3);
- if(in1 != (out1 >> shiftBits)) (5)
- out1 = 0x7FFFFFFF ^ (in1 >> 31);
-
- if(in2 != (out2 >> shiftBits))
- out2 = 0x7FFFFFFF ^ (in2 >> 31);
-
- *pDst = out1;
- out3 = in3 << shiftBits;
- *(pDst + 1) = out2;
- out4 = in4 << shiftBits;
-
- if(in3 != (out3 >> shiftBits))
- out3 = 0x7FFFFFFF ^ (in3 >> 31);
-
- if(in4 != (out4 >> shiftBits))
- out4 = 0x7FFFFFFF ^ (in4 >> 31);
-
- *(pDst + 2) = out3;
- *(pDst + 3) = out4;
-
- /* Update destination pointer to process next sampels */
- pSrc += 4u;
- pDst += 4u;
-
- /* Decrement the loop counter */
- blkCnt--;
- }
- }
- else (6)
- {
-
- /* First part of the processing with loop unrolling. Compute 4 outputs at a time.
- ** a second loop below computes the remaining 1 to 3 samples. */
- while(blkCnt > 0u)
- {
- /* C = A >> shiftBits */
- /* Shift the input and then store the results in the destination buffer. */
- in1 = *pSrc;
- in2 = *(pSrc + 1);
- in3 = *(pSrc + 2);
- in4 = *(pSrc + 3);
-
- *pDst = (in1 >> -shiftBits); (7)
- *(pDst + 1) = (in2 >> -shiftBits);
- *(pDst + 2) = (in3 >> -shiftBits);
- *(pDst + 3) = (in4 >> -shiftBits);
-
-
- pSrc += 4u;
- pDst += 4u;
-
- blkCnt--;
- }
-
- }
-
- /* If the blockSize is not a multiple of 4, compute any remaining output samples here.
- ** No loop unrolling is used. */
- blkCnt = blockSize % 0x4u;
-
- #else
-
- /* Run the below code for Cortex-M0 */
-
-
- /* Initialize blkCnt with number of samples */
- blkCnt = blockSize;
-
- #endif /* #ifndef ARM_MATH_CM0_FAMILY */
-
-
- while(blkCnt > 0u)
- {
- /* C = A (>> or <<) shiftBits */
- /* Shift the input and then store the result in the destination buffer. */ (8)
- *pDst++ = (sign == 0u) ? clip_q63_to_q31((q63_t) * pSrc++ << shiftBits) :
- (*pSrc++ >> -shiftBits);
-
- /* Decrement the loop counter */
- blkCnt--;
- }
-
-
- }
1. 如果函数的参数shiftBits是正数那么表示左移,如果参数shiftBits是负数那么就是右移。
2. 这个函数使用了饱和运算。
饱和运算数值0x80000000将变成0x7FFFFFFF。
3. 获取偏移值shiftBits是正数还是负数。
4. 如果移位值是正数,那么就是左移。
5. 数值的左移仅支持将其左移后再右移相应的位数后数值不变的情况,如果不满足这个条件,那么输出结果只有两种结果(这里就是实现输出结果的饱和运算)。
out =0x7FFFFFFF & 0xFFFFFFFF =0x80000000
out =0x7FFFFFFF & 0x0000000 =0x7FFFFFFF
6. 如果移位值是负数,那么就是右移。
7. 将偏移值取反然后左移即可。
8. 用于实现剩余数值偏移的计算。
9.3.2 arm_shift_q15
这个函数用于求16位定点数的位移,源代码分析如下:
- /**
- * @brief Shifts the elements of a Q15 vector a specified number of bits.
- * @param[in] *pSrc points to the input vector
- * @param[in] shiftBits number of bits to shift.
- * A positive value shifts left; a negative value shifts right. (1)
- * @param[out] *pDst points to the output vector
- * @param[in] blockSize number of samples in the vector
- * @return none.
- *
- * <b>Scaling and Overflow Behavior:</b> (2)
- * \par
- * The function uses saturating arithmetic.
- * Results outside of the allowable Q15 range [0x8000 0x7FFF] will be saturated.
- */
-
- void arm_shift_q15(
- q15_t * pSrc,
- int8_t shiftBits,
- q15_t * pDst,
- uint32_t blockSize)
- {
- uint32_t blkCnt; /* loop counter */
- uint8_t sign; /* Sign of shiftBits */
-
- #ifndef ARM_MATH_CM0_FAMILY
-
- /* Run the below code for Cortex-M4 and Cortex-M3 */
-
- q15_t in1, in2; /* Temporary variables */
-
-
- /*loop Unrolling */
- blkCnt = blockSize >> 2u;
-
- /* Getting the sign of shiftBits */
- sign = (shiftBits & 0x80); (3)
-
- /* If the shift value is positive then do right shift else left shift */
- if(sign == 0u)
- {
- /* First part of the processing with loop unrolling. Compute 4 outputs at a time.
- ** a second loop below computes the remaining 1 to 3 samples. */
- while(blkCnt > 0u)
- {
- /* Read 2 inputs */
- in1 = *pSrc++;
- in2 = *pSrc++;
- /* C = A << shiftBits */
- /* Shift the inputs and then store the results in the destination buffer. */
- #ifndef ARM_MATH_BIG_ENDIAN
-
- *__SIMD32(pDst)++ = __PKHBT(__SSAT((in1 << shiftBits), 16),
- __SSAT((in2 << shiftBits), 16), 16);
-
- #else
-
- *__SIMD32(pDst)++ = __PKHBT(__SSAT((in2 << shiftBits), 16), (4)
- __SSAT((in1 << shiftBits), 16), 16);
-
- #endif /* #ifndef ARM_MATH_BIG_ENDIAN */
-
- in1 = *pSrc++;
- in2 = *pSrc++;
-
- #ifndef ARM_MATH_BIG_ENDIAN
-
- *__SIMD32(pDst)++ = __PKHBT(__SSAT((in1 << shiftBits), 16),
- __SSAT((in2 << shiftBits), 16), 16);
-
- #else
-
- *__SIMD32(pDst)++ = __PKHBT(__SSAT((in2 << shiftBits), 16),
- __SSAT((in1 << shiftBits), 16), 16);
-
- #endif /* #ifndef ARM_MATH_BIG_ENDIAN */
-
- /* Decrement the loop counter */
- blkCnt--;
- }
-
- /* If the blockSize is not a multiple of 4, compute any remaining output samples here.
- ** No loop unrolling is used. */
- blkCnt = blockSize % 0x4u;
-
- while(blkCnt > 0u)
- {
- /* C = A << shiftBits */
- /* Shift and then store the results in the destination buffer. */
- *pDst++ = __SSAT((*pSrc++ << shiftBits), 16); (5)
-
- /* Decrement the loop counter */
- blkCnt--;
- }
- }
- else (6)
- {
- /* First part of the processing with loop unrolling. Compute 4 outputs at a time.
- ** a second loop below computes the remaining 1 to 3 samples. */
- while(blkCnt > 0u)
- {
- /* Read 2 inputs */
- in1 = *pSrc++;
- in2 = *pSrc++;
-
- /* C = A >> shiftBits */
- /* Shift the inputs and then store the results in the destination buffer. */
- #ifndef ARM_MATH_BIG_ENDIAN
-
- *__SIMD32(pDst)++ = __PKHBT((in1 >> -shiftBits),
- (in2 >> -shiftBits), 16);
-
- #else
-
- *__SIMD32(pDst)++ = __PKHBT((in2 >> -shiftBits), (7)
- (in1 >> -shiftBits), 16);
-
- #endif /* #ifndef ARM_MATH_BIG_ENDIAN */
-
- in1 = *pSrc++;
- in2 = *pSrc++;
-
- #ifndef ARM_MATH_BIG_ENDIAN
-