人工智能泡沫已经破了两次,这次还会破吗?
如果要找这两年最大的风口,那非人工智能莫属。无论是学术界、企业界、资本市场,还是政府机构,都对人工智能怀着极大的期待和热情。但是,很多时候期望越大失望也越大。当有一天人们发现人工智能并不是想象中的那么强大时,会不会由一个极端走向另一个极端,觉得人工智能什么都不是呢?
本文试图理性分析这次人工智能浪潮褪去的可能性,以及泡沫破灭的可能“姿势”。值得提出的是,虽然人工智能有泡沫,那也不是一件多么坏的事情,适度的泡沫有助于驱动大众的热情,助推整个智能产业的发展。只是我们要保持理性,并对泡沫破灭的时候有所准备。
历史上的寒冬,人工智能的三次沉浮录
如果将眼光放长远一点,历史上已经经历了三次发展浪潮,也经历了两次低谷。换言之,人工智能的泡沫已经破灭两次了。让我们先来回顾一下人工智能这三起两落的历史,从历史中来找寻现在的意义,推导出我们可能面临的未来。
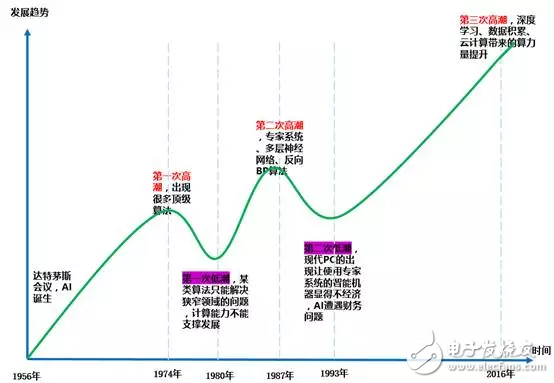
第一次浪潮和第一次低谷:
达特茅斯会议推动了全球第一次人工智能浪潮的出现,这次浪潮从1956年一直持续到1974年。当时乐观的气氛弥漫着整个学界,在算法方面出现了很多世界级的发明,其中包括一种叫做增强学习的雏形(即贝尔曼公式),增强学习就是谷歌AlphaGo算法核心思想内容。
70年代初,AI遭遇了瓶颈。人们发现逻辑证明器、感知器、增强学习等等只能做很简单、非常专门且很窄的任务,稍微超出范围就无法应对。当时的计算机有限的内存和处理速度不足以解决任何实际的AI问题。
研究者们很快发现,要求程序对这个世界具有儿童水平的认识这个要求都太高了——1970年没人能够做出人工智能需要的巨大数据库,也没人知道一个程序怎样才能学到如此丰富的信息。另一方面,有很多计算复杂度以指数程度增加,这成为了不可能完成的计算任务。
第二次浪潮和第二次低谷:
在80年代,一类名为“专家系统”的AI程序开始为全世界的公司所采纳,而“知识处理”成为了主流AI研究的焦点。专家系统的能力来自于它们存储的专业知识,知识库系统和知识工程成为了80年代AI研究的主要方向。
但是专家系统的实用性仅仅局限于某些特定情景,不久后人们对专家系统的狂热追捧转向巨大的失望。另一方面,1987年到1993年现代PC的出现,其费用远远低于专家系统所使用的Symbolics和Lisp等机器。
相比于现代PC,专家系统被认为古老陈旧而非常难以维护。于是,政府经费开始下降,寒冬又一次来临。
第三次浪潮:
1993年后,出现了新的数学工具、新的理论和摩尔定律。人工智能也在确定自己的方向,其中一个选择就是要做实用性、功能性的人工智能,这导致了一个新的人工智能路径。
深度学习为核心的机器学习算法获得发展,积累的数据量极大丰富,新型芯片和云计算的发展使得可用的计算能力获得飞跃式发展,现代AI的曙光又再次出现了。一个标志性事件发生在2016年3月,谷歌DeepMind研发的AlphaGo在围棋人机大战中击败韩国职业九段棋手李世石。随后,大众开始熟知人工智能,各个领域的热情都被调动起来了。
深度学习算法,这次人工智能崛起的技术根基可以看到,每次技术的突破,都会迎来一波人工智能的发展浪潮。这次人工智能浪潮的基石有三个,分别是算法、数据和计算能力。尤其是算法,直接决定了人工智能的发展水平。

人工智能的三大根基
首先,我们来看看这次人工智能的技术根基。1943年,美国心理学家McCulloch和数学家Pitts在论文《神经活动中所蕴含思想的逻辑活动》中首次提出神经元的M-P模型,该模型从逻辑功能器件的角度来描述神经元。M-P模型将生物神经信息处理模式简化为数学模型,为神经网络的理论研究开辟了道路。
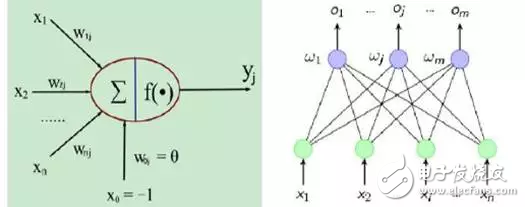
在M-P模型中,Xi(i=1,2,...,n)表示来自于与当前神经元j相连的其他神经元传递的输入信号,Wij表示从神经元i到j的连接强度,F为转移函数。那么神经元的输出用向量表示就是Yj=F(XW)。
2006年,加拿大多伦多教授Hinton和他的学生发表了《Reducing the dimensionality of data with neural networks》,提出了一种面向复杂通用学习任务的深度神经网络,指出具有大量隐层的网络具有优异的特征学习能力,而网络的训练可以采用“逐层初始化”与“反向微调”技术解决。
自此,人类借助神经网络找到了处理“抽象”概念的方法,人工智能进入了一个崭新的时代。
另一方面,由于互联网、移动互联网以及物联网的发展,企业尤其是互联网巨头积累了大量的数据。再加上云计算的发展,让计算能力像电力一样变得更加便宜,可获得性更高。
芯片性能的提高,GPU、FPGA等人工智能芯片的出现和发展,进一步提高了人类可利用的计算水平。一些互联网巨头开始利用大量数据,来训练其深度学习算法,不断提升系统的智能水平。
纯粹理性批判,我们离冬天还有几年?
介绍完了人工智能的“沉浮史”,以及支撑这次浪潮的基础。现在让我们回到刚开始的那个问题:这次人工智能的泡沫会破么?分析这个问题的角度有两个:
从历史上人工智能两次低谷的原因来分析这次面临同样困境的可能性;从这次人工智能浪潮的支撑基石角度,看目前的技术水平能支撑人工智能走多远。
从上两次人工智能泡沫破灭的原因来看,最重要的限制来自算法层面。人们对人工智能的最大期待是不断提升系统的智能水平,让智能系统逐步拓展能够处理的问题范围,最终实现通用人工智能系统,解决几乎所有领域问题。
每次人工智能浪潮中,人们都或多或少的怀有“一劳永逸”的期待。泡沫破灭的主要原因,也是现实的系统远远无法达到人们所想象的智能水平。
第一次泡沫破灭是因为人们发现当时的智能系统如逻辑证明器、感知器、增强学习等,只能做很简单、非常专门且很窄的任务,稍微超出范围就无法应对,这让智能系统不足以解决任何实际的问题。
第二次泡沫破灭也是因为专家系统所能解决的问题非常局限,远远无法达到人们的期待。
那么,算法的局限性也会是埋葬这次人工智能浪潮的掘墓人么?——很可能是!这次技术革新最大的成就无疑是深度学习技术,人工智能浪潮能走多远很大程度上取决于深度学习技术到底有多强。
深度学习是比以前的统计学和机器学习方法更为强大的模式识别方法,但具有很多的内在缺陷:
深度学习系统缺乏推理能力。深度学习技术缺乏表达因果关系的手段,缺乏进行逻辑推理的方法,而逻辑推理毫无疑问是人类智能的核心之一。
深度学习系统缺乏短时记忆能力。人类的大脑有着惊人的记忆功能,我们不仅能够识别个体案例,更能分析输入信息之间的整体逻辑序列。这些信息序列富含有大量的内容,信息彼此间有着复杂的时间关联性。
目前的深度学习系统,都不能很好地存储多个时间序列上的记忆,也就是说缺乏记忆能力。这在目前主流的人机对话系统中可以很明显的感觉出来。
人类的交流,都会基于前面的交谈内容来构建语境,后面的交流都会基于前面的语境来进行,目前的人机对话系统还远远达不到这种水平。比如苹果的Siri系统,你问它3乘以3等于多少,它可以很好的回答,但是你再问“刚才的结果再乘以3呢?”或者说“我刚刚问你什么来自?”,估计Siri得一脸懵逼。
缺乏执行无监督学习的能力。无监督学习在人类和动物的学习中占据主导地位,我们通过观察能够发现世界的内在结构,而不是被告知每一个客观事物的名称。
目前几乎所有由人工智能创造的经济价值都来自监督学习技术,也就是基于系统曾经接受过的其他实例的输入,来学习对结果进行预测或对东西进行分类。
在可预见的未来,深度学习系统还无法具备无监督学习的能力。目前来看,虽然无监督学习可以帮助特定的深度网络进行“预训练”,但最终绝大部分能够应用于实践的深度学习方法都是使用纯粹的有监督学习。
另一个方面,建立在语言之上的知识系统在人类智能方面扮演至关重要的作用。语言是知识的钥匙,而知识正是 AI 的终极目标。人类社会的知识,正是通过语言来代代相传的。
仅靠观察他人,人类是无法获取到广泛的可复用知识的。对于下一代智能系统所需的知识,人工智能必须能同时进行“阅读”和“聆听”才能获取到。而此等程度的机器学习,其关键技术正是 NLP,可以说NLP是实现人与 AI 之间成功沟通的技术关键。但当前的深度学习方法还不足以解决 NLP 领域的核心问题。
仅仅通过扩大今天的深度学习技术,我们无法实现通用智能。虽然神经网络在大样本量上可以达到统计学上令人惊讶成果,但它们“对个例不可靠”,并且经常会导致人类永远不会出现的错误。
输入不准确或不完整数据的神经网络将产生错误的结果,这其中有两个著名的例子:
Google 图像错误地将非洲裔美国人分类为大猩猩;微软的 Tay 在 Twitter 上学习了几个小时后,就出现了种族主义以及歧视女性的言论。
算法的突破无疑是制约人工智能发展的关键,这次人工智能浪潮的核心——深度学习算法的局限,直接决定了目前的人工智能系统不可能实现人们所预想的通用人工智能那种状态。
除了算法层面,就人工智能的另外两个关键因素数据和算力来看,虽然取得了很大的进步,但也存在诸多问题。
首先,数据层面。积累的海量数据就是人工智能系统的“粮食”,可以说是足够多的数据将人工智能“养大的”。
一方面,随着互联网、移动互联网的发展,数据积累的速度在不断加快,5G网络建成之后,物联网体系将会贡献更大量、类型更丰富、对人类更有价值的数据;
另一方面,不是积累的数据都可用,目前机器系统能够“理解”的基本都是结构化数据,像语音、图像、社交数据这些非结构化数据的“理解”还存在很大问题,在10年之内是否能够解决非结构化数据的“理解”问题尚未可知。
算力层面。目前的GPU、FPGA等人工智能芯片,虽然比CPU计算能力更强,但局限性依然很大。我们最终的目标是实现人类一样的通用智能,继而实现超级智能,那从系统的物理结构上就必须支持这一设想。
目前来看,我们对大脑的思维过程还知之甚少,其整个处理和决策过程对于人类来说还是个“黑箱”。就当前的处理芯片跟人脑在物理结构上的差距非常大,甚至可以说根本就不是一回事。对人脑神经系统的研究还任重道远,近10年内基本也看不到获得根本突破性进展的可能。
综上所述,技术尤其是算法层面的局限,决定了这次人工智能浪潮的“天花板”。深度学习算法带来的“技术红利”,将支撑我们再发展5~10年时间,随后就会遇到瓶颈。
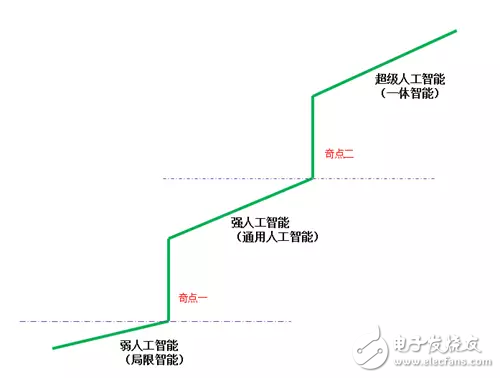
在人工智能领域,技术的进步不是线性的,而是线性积累和间断式突破交替进行的。我们必须要达到一个“技术奇点”,才能实现根本上的突破,达到通用人工智能甚至是超级人工智能的水平。
大概率的可能性,未来几年人们对人工智能怀有巨大的热情和非理性的期待,但同时会渐渐发觉推进起来越来越费劲,仿佛有个无形的“天花板”挡在那里,迟迟不能获得突破,人们的耐心被渐渐耗尽,人工智能的下一个冬天也就来临了。
泡沫会以什么姿势破灭,怎么过冬?
人工智能技术和产业特性决定了,在没能实现高水平的智能之前,现在势头正猛的应用领域,在未来几年很可能会进入寒冬,乃至退出人们的视线,就像第二次浪潮中的专家系统一样。
人工智能的产业化应用,更多的是基于人们对于未来技术发展水平更高的预期,而不是当下已经达到的水平。比如自动驾驶领域,未来商用是基于能够达到L4级别的预期,但如果预期落空了呢?很可能自动驾驶就会被彻底抛弃。
就一般产业而言,线性发展的成分更重一些,即使产业不能再往前推进了,依然能够保持比较高的产业成熟度。人工智能产业则不同,如果以百分制来衡量一个产业的发展程度,人工智能不是从1慢慢发展到100,而是要么是90分以上,要么是10以下。
试想一下,你有一个智能助手,如果他的智力水平一直在10岁以下,你能接受么?那样的智能助手更多的是个玩具,不能委以重任,毕竟谁也不会将重要的事情交给一个小孩子来做。
再比如翻译领域,一旦智能系统能够达到人类水平的翻译能力,那将是一次彻底的颠覆,人类翻译员将彻底消失;但是,在没达到那种水平之前,翻译系统基本就是个摆设,你不能通过那套系统来与外国人顺畅的交流,也不能将看到的整段材料马上转换成另一种语言。
人工智能的泡沫,更多的是产业化和商业应用层面的。很多做人工智能应用的企业,如果发现将方案落地的期待落空,那他整个商业价值存在的根基就不存在了,整个产业将会消失,大量企业也会倒闭。
面对那样一个未来,我们应该怎么应对呢?我提出几点参考建议:
适度降低对人工智能的技术预判,理性设定商业模式。企业要仔细评估技术的发展潜力,不要抱有不切实际的幻想。寻找并设计一些智能水平不是太高就能具有商业价值的应用模式,并基于此来构建竞争壁垒。比如在自动驾驶领域,我们要做好L4在10年内无法实现的心理准备,寻找一些L3级别就能具有商业价值的应用领域。
现在就开始准备“过冬的粮草”。泡沫破灭之后,融资会变得越来越难,依据公司本身的造血能力维持基本没戏。所以,现在尽可能的多融资吧,并且在未来几年省着点花,争取能挨过寒冬。
实行曲线救国策略,发展一些“伪智能”业务,拓展业务领域。如果哪天发现“纯人工智能”这条路走不通,可以考虑发展一些周边产业,只要能带来现金流就行。虽然挂羊头卖狗肉有点缺德,但能保存“革命的火种”,也算一件好事。
我对人工智能事业怀有深切的热情,但目前的技术水平还无法满足我们内心最深切的期待,这一波人工智能浪潮很可能在几年内遭遇低谷。
比较坏的情况是:大多数人会由于失望而对人工智能事业不信任,媒体会由吹捧转而嘲讽冷落,大量企业可能倒闭,目前炙手可热的人工智能人才会遭遇职业危机,流入人工智能领域的资金会越来越少,到处都是一副萧条的景象。
怀有最美好的期待,做最坏的打算,这是干事业应有的理智和态度。希望这次人工智能浪潮不是行将破灭的泡沫,但如果是,请做好准备。
转来自中国软件网,作者欧应刚。
看看
分析的很有道理。
看看
路过。
深度学习是个大方向,针对具体的领域还需要细分